Hirdetés
- EA Sports WRC '23
- Xbox Classic / Xbox 360
- PlayStation 5
- Fortnite - Battle Royale & Save the World (PC, XO, PS4, Switch, Mobil)
- Warhammer 40.000
- Lost Records: Bloom & Rage – Tape 1 teszt
- Monster Hunter (gyűjtő topik) - PC/PS/XBOX/SWITCH
- Asylum - tölthető a demó
- Nintendo Switch 2
- Kingdom Come: Deliverance II teszt
Új hozzászólás Aktív témák
-

S_x96x_S
addikt
válasz
 S_x96x_S
#1882
üzenetére
S_x96x_S
#1882
üzenetére
(több gép összekapcsolás - TB5 + 2db M3 Ultra 512GB
Terv: 11 tok/sec jelenleg --->> 20 tok/sec --->> 40 tok/sec"Thunderbolt 5 interconnect (80Gbps) to run the full (671B, 8-bit) DeepSeek R1 distributed across 2 M3 Ultra 512GB Mac Studios (1TB total Unified Memory). Runs at 11 tok/sec. Theoretical max is ~20 tok/sec."
https://x.com/alexocheema/status/1899735281781411907"We’ll keep improving it in @exolabs. Once we approach the “theoretical maximum”, there’s a bunch of other stuff we can do to surpass it for sparse MoE, e.g. expert parallelism. I think we can get to 40 tok/sec."
https://x.com/alexocheema/status/1899737017866719506 -
S_x96x_S
addikt
válasz
 DarkByte
#1883
üzenetére
DarkByte
#1883
üzenetére
> oké, de ez még mindig alig 1GB/s-es tempó,
nem 1 --> 11 !
A 11Gbps full-mesh hálózat ~= Minden eszköz közvetlenül 10Gbps kapcsolatokkal csatlakozik minden más eszközhöz.
és az USB4 biztosítja az operációs rendszer támogatást is.> összehasonlítva mondjuk
> egy 4090 1008GB/s VRAM sávszélességével, megmosolyogtaAttól függ
... kis modell vagy nagy modellmert önmagában a sávszélesség nem sokat ér - ha nincs mellette elég VRAM.
A LLama 3.1 70B-Q4 -esetén
egy StrixHalo 2.2x gyorsabb ( tokens/sec ) mint egy RTX 4090 (24GB) !!!
Ráadásul kevesebbet is fogyaszt!
-
S_x96x_S
addikt
válasz
DarkByte
#1880
üzenetére
> A legfrissebb Framework Desktop videóban is
> valahogy kihagyták a több gép összekötésével elérhető
> sebesség bemutatását. Valószínűleg nem valami acélos.USB4 -összeköttetéssel - a 11Gbps mesh hálózat simán megvan.
Az újabb Mac-ek pedig már a TB5 -öt is ismerik. -
S_x96x_S
addikt
válasz
DarkByte
#1875
üzenetére
> pl. Deepseek R1-nél azt mondják a 14B a legkisebb amivel érdemes foglalkozni.
A "deepseek-r1:14b" valójában a
"DeepSeek-R1-Distill-Qwen-14B",
ami azt jelenti, hogy a Qwen-14B modellt finomhangolták (finetuned)
a nagy DeepSeek-R1 modell által kiválogatott
és generált 800 ezer érvelési mintán és adaton.Nekem a portói bor analógia jut eszembe - ami egy "fortified wine",
vagyis alkohollal dúsított(erősített) bor ;
és Qwen-14B - is fel van erősítve az R1 -el ; de nem egyezik meg az R1 -el.--------
És mivel a 7b és a 8b alapja más - érdemes mindkettőt tesztelni:A
deepseek-r1:8bpedigDeepSeek-R1-Distill-Llama-8B( Llama:8b alapú )
Adeepseek-r1:7bpedigDeepSeek-R1-Distill-Qwen-7B( Qwen:7b alapú )
..."""
The Qwen distilled models are derived from Qwen-2.5 series, which are originally licensed under Apache 2.0 License, and now finetuned with 800k samples curated with DeepSeek-R1.The Llama 8B distilled model is derived from Llama3.1-8B-Base and is originally licensed under llama3.1 license.
The Llama 70B distilled model is derived from Llama3.3-70B-Instruct and is originally licensed under llama3.3 license.
"""
https://ollama.com/library/deepseek-r1 -
S_x96x_S
addikt
Ha valakit CPU inference érdekel ...
9950X3D - AI Benchmark-ban ( Whisper.cpp ; Llama.cpp , ONNX - ResNet101 )
az élre tört - mégha nem is olyan hatalmas előnnyel
https://www.phoronix.com/review/amd-ryzen-9-9950x3d-linux/9
( az AVX512 miatt a Core Ulte 9 285K -nál mindenképpen jobb
de persze nem árt spéci kapcsolókkal lefordítani a programot! ) -
#1861
S_x96x_S
addikt
hiperFizikus
#1858
S_x96x_S
addikt
válasz
 hiperFizikus
#1858
üzenetére
hiperFizikus
#1858
üzenetére
> A ChatGPT MI modellnek feltettem vagy 100 kérdést mégse vagyok sokkal boldogabb,
Mi volt a prompt ?
Amúgy a promptolás nem olyan egyszerű ... főleg hogyha a boldogság a cél.
De még egy o1 - generált válasz se ér semmit se, hogyha nem próbáljuk ki:
""""
Napi Boldogság-Checklist (kiegészítve újabb tudományos megállapításokkal)
1.) Reggeli hála- és célkitűzés-percek
Ébredés után szánj 1-2 percet arra, hogy végiggondold, mi mindenért lehetsz hálás (család, egészség, kis sikerek, meleg otthon stb.). Tűzz ki aznapra egy apró, konkrét célt (például: „Ma kedves leszek magamhoz, nem rohanok át a sikereimen.”).
2.) Mozgás és örömhormon-aktiválás
Ha teheted, iktass be 5-10 perc testmozgást (gyors séta, nyújtás, könnyed jóga vagy pár guggolás-fekvőtámasz). A legújabb kutatások is megerősítik, hogy már napi pár perc is segíti az endorfinok és dopamin termelődését, így jobb hangulattal indul a nap. Ha több időd engedi, sportolj intenzívebben (futás, úszás, súlyzós edzés), de a lényeg a rendszeresség és a szervezet „beindítása”.
3.) Tudatos reggeli és hidratálás
Kutatások szerint a kiegyensúlyozott, fehérje- és rostgazdag reggeli segít stabilan tartani a vércukrot és a hangulatot. Igyál elegendő vizet vagy teát, mert a hidratáltság segít a koncentrációban és a közérzet javításában.
4.) Mini-énidő a napi rutinban
Mielőtt belekezdenél a munkába vagy a családi logisztikába, teremts pár „szemlélődős” pillanatot. Nézz ki az ablakon, tedd rendbe a gondolataidat, vagy csak lélegezz néhányszor mélyen. Ez a tudatos megállás „bonbonként” működik: tölt és segít tudatosítani, hogy „itt és most” is jól érezhetem magam.
5.) Sikerek észlelése – rögtön, amikor megtörténnek
Egész nap figyeld az apró eredményeket (például: időben elindult a gyerek az iskolába, befejeztél egy feladatot, kedvesen szóltál valakihez). Azonnal ismerd el magadban: „Ezt megcsináltam!”, „Ez is sikerült!”. Ez a gyors dopaminlöket segít a további motiváció fenntartásában.
6.) Örömtérkép frissítése
Tarts magadnál egy kis jegyzetfüzetet vagy használj jegyzet-appot a telefonodon, hogy napközben feljegyezd, mi okozott örömöt (akár kicsi, akár nagy dolog). Így tudatosan figyeled, mi tölt téged, és könnyebben újra is alkalmazod ezeket a tevékenységeket. Legújabb kutatások kimutatták, hogy már a pozitív élmények puszta dokumentálása is javítja a hangulatot.
7.) Társas kapcsolatok és oxitocin
Legalább egyszer naponta tudatosan gratulálj vagy dicsérj meg valakit (családtagot, kollégát). Az ő örömük visszahat rád, és fokozza az összetartozás-érzést. Az érintés, az ölelés vagy akár a közös nevetés mind-mind elősegíti az oxitocin termelődését, ami a közelség és boldogság érzését növeli.
8.) Rövid szünetek – tudatos légzés vagy meditáció
Délután vagy a nap sűrűbb szakaszaiban állj meg pár percre, és végezz légzőgyakorlatot (például 4 másodpercig beszív, 4 másodpercig bent tart, 4 másodpercig kifúj). Ha belefér, 5-10 perc egyszerű mindfulness-gyakorlat (csendes ülés, figyelem a környezet hangjaira vagy a belső érzésekre) segíti a szerotoninszint kiegyensúlyozását és a stressz oldását.
9.) Nap végi összegzés és hálanapló
Lefekvés előtt gondold át a napodat: „Mi sikerült jól?”, „Minek örültem?”, „Miből tanultam?”. Írd le ezeket 1-2 mondatban. Ez segít az agyat átállítani hiányfókuszról a bőség tudatára – tudományos kísérletek kimutatták, hogy akik rendszeresen írnak hálanaplót, általánosan magasabb boldogságszintet élnek meg.
10.) Minőségi alvás előkészítése
Kapcsold ki vagy tedd félre a kütyüket legalább 30 perccel elalvás előtt, hogy a kék fény ne zavarja a melatonintermelést. Alakíts ki egy nyugtató esti rutint (például olvasás, halk zene, könnyű nyújtás, meleg zuhany), ami segít ellazulni. A jó alvás kulcsszerepet játszik a testi-lelki regenerációban.
""" -
S_x96x_S
addikt
válasz
 Zizi123
#1830
üzenetére
Zizi123
#1830
üzenetére
> a memória sávszélesség a legfontosabb
> a nagy LLM-ek használata közben, akkor ez eleve kizárja azt, hogy világverő legyen.Elnézést valószínüleg - félreérthető voltam.

azt irtam, hogy
"Max 4 chiplet lehet egyben és kétféle memóriát használ mindegyik chiplet:"
vagyis egy chiplet adatát adtam meg:
- gyors: 32 - 64 GB -os [ 273 Gb/s] LPDDR5X -es ( hasonló mint a Strix Halo ) ]
- és egy lassú So-DIMM -es DDR5 ~ 90Gb/s - sebességgeset.amit fel kell szorozni 4x - a 4 chipletes verzióhoz.
- max memória : 2.304 GB ( 256 GB LPDDR5X + 8x DDR5 DIMMs )
- és max sávszél - 1.45 TB/sLásd slide :


persze mire a Zeus megjelenik +2 év múlva, akkora
a [ Strix Halo / nVidia Digits ] utódja is kaphat nagyobb bővíthető memóriát ; -
S_x96x_S
addikt
válasz
Zizi123
#1828
üzenetére
(Bolt graphic )
> Mivel bővíthető egyébként, milyen memóriával?Sima laptop [ SO-DIMM DDR5 ] -el.
Max 4 chiplet lehet egyben és kétféle memóriát használ mindegyik chiplet:
- gyors: 32 - 64 GB -os [ 273 Gb/s] LPDDR5X -es ( hasonló mint a Strix Halo ) ]
- és egy lassú So-DIMM -es DDR5 ~ 90Gb/s - sebességgeset.a két típusú memóriát mintha együtt használná
és így 273+90 = 363 Gb/s sebességet adnak meg
a slide-okon - 1 chipletre. ( slide 36. )https://bolt.graphics/wp-content/uploads/2025/03/Bolt-Zeus-Announcement-External.pdf
> mire piacra kerülne lesznek sokkal jobbak, és így el sem kezdik gyártani...
IP Licenszet árulnának mint az ARM;
vagyis tervet - amit az ügyfél cutomizálhat. -
S_x96x_S
addikt
új jelölt a Lokális LLM -re
bővíthető memóriája van !!!!!
van belőle több változat ..
( Sajnos 2026 Q3 előtt nem lehet tesztelni .. )
https://prohardver.hu/hir/bolt_graphics_zeus_gpu_dizajn.html

500W -on
+ Up to 2.304 GB @ 1.45 TB/s
+ 512MB on-chip cache
+ 6x 800 GbE
-
S_x96x_S
addikt
válasz
 consono
#1807
üzenetére
consono
#1807
üzenetére
>> 5 db "eper" szóban - hány db "r" betű van ?
> De ez "buta" kérdés egy LLM-nek...de nem lehet minden kérdés "buta"
ha nem tud rá válaszolni egy
"mathematical reasoning, coding proficiency, and general problem-solving capabilities." -al
reklámozott modell.
és a "QwQ-32B" - ennek a "buta"' kérdésnek
még egyszerűbb formájával lett demózva - amire persze tudja a választ, de kontextusban már nem:
- prompt = "How many r's are in the word \"strawberry\""
https://qwenlm.github.io/blog/qwq-32b/persze az én promptomban annyi változás van, hogy magyar nyelvre át lett fogalmazva és hozzá lett adva, hogy "5db eper szó" -ra adja meg a választ.
És így már elbukik a "QwQ-32B" - pedig "papiron" igéretes lett volna.

"QwQ-32B is evaluated across a range of benchmarks designed
to assess its mathematical reasoning, coding proficiency,
and general problem-solving capabilities.
The results below highlight QwQ-32B’s performance in comparison
to other leading models, including DeepSeek-R1-Distilled-Qwen-32B,
DeepSeek-R1-Distilled-Llama-70B, o1-mini, and the original DeepSeek-R1."---
> Persze arra meg pont jó ez a kérdés, hogy rávilágítson arra,
> hogy nem mindenre jók az LLM-ek, nem minden a diffúzió, meg az attention.
tesztelésre jól lehet használni;
és a "QwQ-32B" - sajnos még nem ér fel egy eredeti DeepSeek-R1 -el.
"We are excited to introduce QwQ-32B, a model with 32 billion
parameters that achieves performance comparable to DeepSeek-R1,
which boasts 671 billion parameters (with 37 billion activated)." -
S_x96x_S
addikt
Az én kedvenc teszt kérdésem :
5 db "eper" szóban - hány db "r" betű van ?
-------- [ Válaszok: ] -------
DeepSeek R1 (webes; valószínüleg a nagy model ) :
--> 5 darab "eper" esetén: 1 × 5 = 5 db "r" betű.ChatGPT o3-mini-high :
--> 5db !"ollama run qwq:32b "

--> **Answer:** 1"ollama run deepseek-r1:32b"
--> **Végső eredmény:** 1"ollama run phi4-mini "
--> "Így válaszolunk: Az ötdból álló szóban „eper” három db 'r' betű van.""ollama run mixtral:instruct"
---> 5 db "eper" szóban a "r" betűnek összesen 5 darabja van, mivel minden "eper" szó egy-egy "r" betűt tartalmaz."ollama run gemma2:27b-instruct-q8_0"
--> 5 db "eper" szóban **10 db** "r" betű van. Mert minden "eper" szóban 1 db "r" betű van, és 5 x 1 = 10."ollama run llama3.2-vision:11b"
--> A válasz 2"ollama run openthinker:32b"
--> There are 5 'r' letters in five instances of the word "eper"."ollama run openthinker:7b"
--> **Végső válasz:** A nyilvántartás szerint **összesen 5 db 'r' betű vannak az öt 'eper' szóban.**"ollama run qwen2.5:32b"
--> Tehát 5 db "eper" szóban 5 db "r" betű van. -
S_x96x_S
addikt
""""
...The M3 Ultra 512GB Mac Studio fits perfectly with massive sparse MoEs like DeepSeek V3/R1.
2 M3 Ultra 512GB Mac Studios with @exolabs
is all you need to run the full, unquantized DeepSeek R1 at home.The first requirement for running these massive AI models is that they need to fit into GPU memory (in Apple's case, unified memory). Here's a quick comparison of how much that costs for different options (note: DIGITS is left out here since details are still unconfirmed):
NVIDIA H100 (80GB): 37.5/s
AMD MI300X (192GB): 27.6/s
Apple M2 Ultra (192GB): 4.16/s (9x less than H100)
Apple M3 Ultra (512GB): 1.56/s (24x less than H100)Apple is trading off more memory for less memory refresh frequency, now 24x less than a H100. Another way to look at this is to analyze how much it costs per unit of memory bandwidth. Comparison of cost per GB/s of memory bandwidth (cheaper is better):
NVIDIA H100 (80GB): $8.33 per GB/s
AMD MI300X (192GB): $3.77 per GB/s
Apple M2 Ultra (192GB): $6.25 per GB/s
Apple M3 Ultra (512GB): $11.875 per GB/s
There are two ways Apple wins with this approach. Both are hierarchical model structures that exploit the sparsity of model parameter activation: MoE and Modular Routing.MoE adds multiple experts to each layer and picks the top-k of N experts in each layer, so only k/N experts are active per layer. The more sparse the activation (smaller the ratio k/N) the better for Apple. DeepSeek R1 ratio is small: 8/256 = 1/32. Model developers could likely push this to be even smaller, potentially we might see a future where k/N is something like 8/1024 = 1/128 (<1% activated parameters).
Modular Routing includes methods like DiPaCo and dynamic ensembles where a gating function activates multiple independent models and aggregates the results into one single result. For this, multiple models need to be in memory but only a few are active at any given time.
Both MoE and Modular Routing require a lot of memory but not much memory bandwidth because only a small % of total parameters are active at any given time, which is the only data that actually needs to move around in memory.
.....
""" -
S_x96x_S
addikt
válasz
Zizi123
#1795
üzenetére
> Azért vicces, hogy 1 tenyérben elfér,
Ez nem a pici Mac Mini ( ami tenyérbe mászó )
A Mac Studió már nem fér el egy tenyérben.
és majd itt ( https://github.com/ggml-org/llama.cpp/discussions/4167 ) is lesz valami benchmark.

az r/LocalLLaMA -s csoportban már tárgyalják is ...
https://www.reddit.com/r/LocalLLaMA/comments/1j43us5/apple_releases_new_mac_studio_with_m4_max_and_m3/ -
S_x96x_S
addikt
válasz
 5leteseN
#1793
üzenetére
5leteseN
#1793
üzenetére
> Gyanítom, hogy a szűk keresztmetszet a két almás-kütyü közötti sávszélesség lesz!
több Thunderbolt 5 -ös kapcsolattal nem olyan vészes. ( Thunderbolt Bridge )
itt egy USB4 mesh network -ös leírás, a TB5 az dupla annyit tud ;
https://fangpenlin.com/posts/2024/01/14/high-speed-usb4-mesh-network/---
Az M3 Ultrának 6 db TB5 - ös kapcsolata van
Az M4 Max-osnak 4 db TB5
És mindegyiken van még tartaléknak egy "10 gigabites Ethernet-port" -
S_x96x_S
addikt
új Mac Studió -
Apple M3 Ultra chip 32 magos CPU‑val, 80 magos GPU‑val és 32 magos Neural Engine‑nel
512 GB egyesített memória
4 749 990 Ft
-----------
Apple M4 Max chip 16 magos CPU‑val, 40 magos GPU‑val és 16 magos Neural Engine-nel
128 GB egyesített memória
1 849 990 Ft -
S_x96x_S
addikt
válasz
5leteseN
#1780
üzenetére
> Például: egy 10GB-os LLM mekkora VRAM-ot igényel összesen?
attól függ.
pl.
https://huggingface.co/spaces/NyxKrage/LLM-Model-VRAM-Calculator
pl. egy Qsen2.5-14B-Instruct - Q4_K_S -el 8192 Context -el
ami -->
7.88 GB model size ( + 2.16 GB Context Size ) = 10.04GB Total Size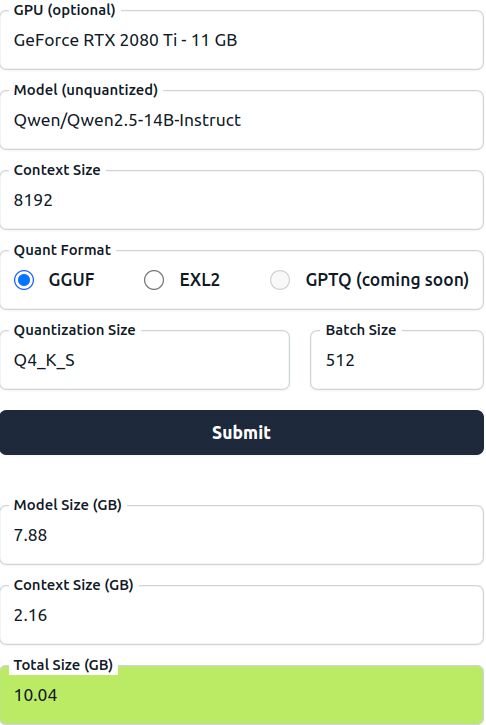
-
S_x96x_S
addikt
válasz
consono
#1755
üzenetére
> egy AMD APU van a gépemben
(Ryzen AI 300 ) CPU FP32 vs. NPU/iGPU hybrid-llm INT4
Accelerate DeepSeek R1 Distilled Models Locally on AMD Ryzen™ AI NPU and iGPU
https://www.amd.com/en/developer/resources/technical-articles/deepseek-distilled-models-on-ryzen-ai-processors.html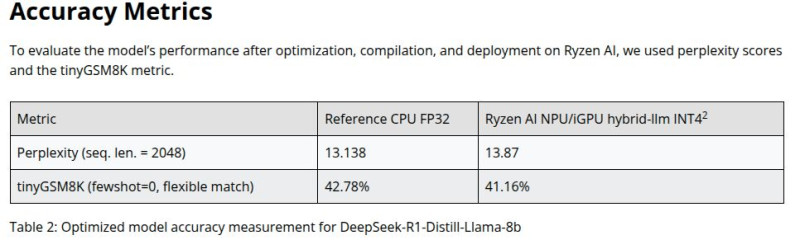
// HAbár
 .. valószínüleg nem értem a mért számokat.
.. valószínüleg nem értem a mért számokat.
de hátha valaki tudja. -
S_x96x_S
addikt
várom!
(pár gondolat, amire nem kell válaszolni )
Jó lenne, hogyha minden hw -es ( CPU,NPU,GPU,Notebook,Mini PC ) tesztben
~ AI benchmarkok ( LLM ) is lennének. (+ pár Linux -os is)Több specializált AI fórum topik kellene:
- Kreativ AI (kép, hang )
- LLM/ChatGPT ( text )
- Programkód generálás ( LLM )
- Local LLM
- ....És ha Mp3Pintyo (aki human ) - mellett
lesz még 3-10 AI újságíró Ágens;
akkor legyen nekik szép magyaros robot nevük:
- "R0-Bi"
- "B0-Tyi"
- "D1-Gi"
- "C0-Di"
- "Z3-R0"
- "L4-Tó"- ... -
S_x96x_S
addikt
(egészségügy)
"""
ChatGPT Saved My Life (No, Seriously, I’m Writing this from the ER)
How using AI as a bridge when doctors aren't available can improve patient-to-doctor communications in real time emergencies
https://hardmodefirst.xyz/chatgpt-saved-my-life-no,-seriously,-im-writing-this-from-the-er
""" -
S_x96x_S
addikt
Jelenleg én nem tudok olyan modellt ,
ami mindenben a legjobb és ingyenes is. próbálgatni kell és tesztelgetni.a Gemini új verziója például akkor lehet hasznos, hogyha nagyon nagy szövegeket akarsz feldolgozni. ( és itt is több változat is van )
a Claude Anthropic 3.7 ( tegnap jelent meg ) - meg a programozásban remekel, de sok más dologban is nagyon jó választ ad.
A deepseek-nél olyan változatot kell használni, ami nem a kínai szervereken dolgozza fel az adatokat. ( munkánál különösen fontos ) de ezek általában nem ingyenesek.
A ChatGPT -ben is sok modell van , de nem tudom, hogy az ingyeneseben mi érhető el.
(az o3-mini-high elég jó )> Melyik az az teljes verziójában ingyenes alternatíva,
> ami felveszi a versenyt a chatp Gpt-vel?szerintem olyan nem létezik. ( de hátha majd valaki kijavít )
https://www.anthropic.com/ -ot érdemes megnézned,
pár dologban remekel ( például programozás )
és az ingyenes verzióban is ki lehet próbálni. -
S_x96x_S
addikt
válasz
S_x96x_S
#1726
üzenetére
ouch ... A 96GB RTX 4090 - valószínüleg fake
"384 bit = 24 VRAM Chip w. clamshell = 4GB(32Gb) density per chip. I think it is fake. Afaik, there is no 32Gb density chip one."
https://x.com/harukaze5719/status/1893959550346108975 -
S_x96x_S
addikt
válasz
5leteseN
#1724
üzenetére
Az üzlet a 96GB -ra bővített RTX 4090 -ben van.
arra kéne rástartolni.
https://x.com/minotauronlucy/status/1893823097158979836a sima 48GB -ra bővített RTX4090 - már alap.
https://www.bilibili.com/video/BV1c9rHYrEdx/ -
S_x96x_S
addikt
válasz
 ParadoxH
#1715
üzenetére
ParadoxH
#1715
üzenetére
Ami még a labor-eredmények kiértékelésénél fontos lehet
az a kontextusok és releváns infók megadása.
Még az se mindegy, hogy az USA-ban él valaki vagy vidéken Magyarországon.A ChatGPT o1 - meg is határozta, hogy mit érdemes megemlíteni:
és ha valamit kihagysz, akkor nem biztos, hogy tökéletes választ kapsz !
"""
1.) Életmód és szokások
- Étrend: milyen típusú ételeket fogyasztasz, vegetáriánus vagy-e, van-e valamilyen speciális diétád, milyen gyakran eszel, mik a főbb étkezési szokásaid.
- Napi folyadékbevitel: mennyi tiszta vizet (vagy más folyadékot) iszol naponta.
-Testmozgás: milyen rendszeresen sportolsz, milyen típusú mozgásformát végzel, mennyi ideig és milyen intenzitással.
- Káros szenvedélyek: dohányzás, alkoholfogyasztás, egyéb függőségek.
- Hasznos szokások: relaxáció, jóga, stresszkezelő technikák, támogató közösség.
2.) Egészségi állapot és előzmények
- Fennálló, krónikus betegségek (pl. cukorbetegség, magas vérnyomás, autoimmun betegségek).
- Kórtörténet: korábbi műtétek, kórházi kezelések, trauma vagy baleset, családi kórtörténet (genetikai hajlamok).
- Jelenlegi tünetek vagy panaszok: miért készült a laborvizsgálat, vannak-e konkrét problémák (fáradtság, hajhullás, fájdalom, stb.).3.) Gyógyszerek, kiegészítők
- Gyógyszerlista: milyen vényköteles és vény nélkül kapható szereket használsz, milyen dózisban és milyen gyakorisággal.
- Vitaminok, étrend-kiegészítők: pontos megnevezésük, adagolásuk, szedési időpontok (pl. étkezés előtt vagy után).
- Potenciális interakciók: többféle készítmény együttes alkalmazása befolyásolhatja a laboreredményeket.4.) Életkor, nem, etnikai háttér
- Életkor és nem: sok laborparaméter más referenciaértékkel rendelkezik gyermekek, felnőttek, idősek, illetve nők és férfiak esetében.
- Etnikai/genetikai háttér: bizonyos betegségekre való hajlam vagy normál értéktartományok eltérhetnek különböző populációkban.5.) Fizikai paraméterek
- Testsúly, testmagasság, BMI: a túlsúly vagy alultápláltság módosíthatja egyes laborparamétereket.
- Vérnyomás: a vérnyomásértékekhez kapcsolódó betegségek vagy rizikótényezők felderítésében fontos.6.) Mentális és szociális tényezők
- Pszichés állapot: stressz, szorongás, depresszió; ezek befolyásolhatják a hormonháztartást és az immunrendszert.
- Környezeti tényezők: munkakörülmények, alvási szokások, családi háttér, egyedül élés vagy közös háztartás.7.) Vizsgálat időpontja és körülményei
- Évszak, napszak: például a D-vitamin és egyes hormonok szintje szezonálisan ingadozhat, a kortizolszint a nap során változik.
- Éhgyomri vagy nem éhgyomri: a vérvétel körülményei jelentősen módosíthatják az eredményeket (cukorszint, koleszterin stb.).
- Egyéb körülmények: volt-e betegség vagy antibiotikum-kúra a vizsgálat előtti hetekben, mennyi idő telt el az utolsó étkezés és a laborvizsgálat között.Ezek az információk azért fontosak, mert a laboreredmények önmagukban csak egy pillanatfelvételt jelentenek az aktuális állapotról. A pontosabb kontextus lehetővé teszi a mesterséges intelligenciának, hogy személyre szabottabb elemzést adjon, figyelembe véve a szervezet működésére ható külső és belső tényezőket.
""""" -
S_x96x_S
addikt
válasz
ParadoxH
#1715
üzenetére
> általános laboreredmények kielemzésére
Lehetne pontosítani?
- pl. egy személy - egy vagy több labor eredményét akarod összegezni
- vagy több ezer személynek - lokális LLM -el történő elemzését szeretnéd megoldani?
ha az első eset:
akkor én a fizetős OpenAI - Chatgpt -vel szoktam ( a sajátomat ) elemezni ;
és elég értelmes válaszokat ad,
Vagyis szerintem jó .
ha kérem hogy magyarázza el egy 15 éves szintjén, akkor megteszi. nem lesz ideges .. nem tekint hülyének .. úgyhogy szerintem ok.persze így is elég furcsa volt a legutolsó eset,
amíg rá nem jöttem, hogy felcserélték a nememet ( férfi <---> nő )![;]](//cdn.rios.hu/dl/s/v1.gif)
[ mivel a referencia értékeknél nem mindegy a nem - kérnem kellett a labortól egy frissített eredményt. ]mindenesetre a gagyi - halucináló - ( ingyenes??? ) modelleket én nem ajánlanám.
Ha már a saját egészségem a tét, akkor minél kevesebb hallucinációt szeretnék.Ha nagyon sok labor eredményt kell feldolgozni ( egy személynek )
akkor talán még a https://aistudio.google.com/ - próbálkoznék - ott is a legjobb modellekkel.de összességében az én véleményem,
hogy érdemes egy jobbfajta AI -val is konzultálni.
( de a végleges véleményt nem árt átbeszélni a háziorvossal is - nehogy valami dolgo félre legyen értelmezve. ; persze nem minden háziorvos partner ebben .. és ahhoz hogy jobban odafigyeljen ránk, lehet, hogy kell pár apró ajándék - ami még az orvosnak is etikailag elfogadható. )----------
és ez a cikk is érdekes lehet
"How I Built an Open Source AI Tool to Find My Autoimmune Disease (After $100k and 30+ Hospital Visits) - Now Available for Anyone to Use"
https://old.reddit.com/r/selfhosted/comments/1ij7s4m/how_i_built_an_open_source_ai_tool_to_find_my/
--> https://github.com/OpenHealthForAll/open-health -
S_x96x_S
addikt
válasz
 tothd1989
#1712
üzenetére
tothd1989
#1712
üzenetére
> .... meg volt válaszolva, minden friss.
> Mondjuk azt nem tudom miért haluzza be,
> hogy windows 10, amikor lassan 1 éve 11-et használok asztali gépen (virtualizálva is).én amikor elérem azt a pontot .. hogy ~ "nem értem, nem tudom "
akkor nagyon gyorsan arra a következtetésre jutok,
hogy --> újratelepítés nulláról.
és reménykedni, hogy ezúttal jobb lesz a helyzet.
( és ez a windows + linux -ra is érvényes )Amúgy én még angol nyelvű operációs rendszereket preferálom,
amiatt a praktikus ok miatt, hogy a hibaüzenetek is angolul vannak,
és akkor van remény, hogy találok a neten valami hasonló problémát
- ami közelebb vezethet a megoldáshoz. -
S_x96x_S
addikt
válasz
 tylerddd
#1702
üzenetére
tylerddd
#1702
üzenetére
> Ez érthetetlen számomra. Valami ötlet, hozzászólás?! Köszönöm!
sárkány ellen sárkányfű ...
A ChatGPT-4o kell kérdezni a problémáról:
""
Fájlformátum Probléma
- Ha nem .xlsx vagy .csv formátumban töltötted fel, lehet, hogy a rendszer nem tudja megfelelően feldolgozni.
- Megoldás: Próbáld meg újra menteni a fájlt Excel (.xlsx) vagy CSV (.csv) formátumban, majd töltsd fel újra.Elcsúszott Sorok és Oszlopok
- Ha a fájlodban egyedi formázások, üres sorok, rejtett oszlopok, vagy egyesített cellák vannak, ezek befolyásolhatják az adatok beolvasását.
- Megoldás: Ellenőrizd és töröld az egyesített cellákat, felesleges üres sorokat, és nézd meg, hogy a táblázat szerkezete tiszta-e.ChatGPT-4o Nem Kezeli Jól a Cellák Helyzetét
Ha egyesével bemásoltad az adatokat a chatbe, akkor lehet, hogy nem tudja logikusan összekapcsolni őket.
Megoldás: Inkább egy táblázatos formátumban küldd el az adatokat így:| A | B | C |
|---|---|---|
| 1 | 2 | 3 |
| 4 | 5 | 6 |vagy CSV formában:
A,B,C
1,2,3
4,5,6
""" -
S_x96x_S
addikt
válasz
tothd1989
#1697
üzenetére
Ez a wsl néha elég trükkös.
Nem árt a WSL2 + WSLg
és tudtommal WSL1 -ben biztos nem fog menni.wsl --version
wsl --update
+ és néhány tuning.
"""
Since WSL2 is a virtual machine you’ll need to assign it resources. Microsoft provides some sensible defaults. WSL2 is allowed access to all CPU cores and GPU cores if you have WSLg installed. Memory is limited to half of your system’s memory. In my case WSL used 16GB because I had 32GB before my upgrade.
Please note, it can use up to a maximum of half your memory and all CPU/GPU cores. It doesn’t if there’s no need. When you create a regular VM, memory is locked for the VM to ensure it has enough. In this case, WSL can allocate more if it needs to use more.
Now that you know how resource management works on a high level, let’s take a look at configuring the memory limit.
https://fizzylogic.nl/2023/01/05/how-to-configure-memory-limits-in-wsl2
+ How to set up CUDA and PyTorch in Ubuntu 22.04 on WSL2 -
S_x96x_S
addikt
válasz
tothd1989
#1687
üzenetére
> +8gb (lassabb) ram és 4x annyi token/s?
a titok nyitja,
hogy a deepseek-r1:32b - eleve 20GB csak az adat.
úgyhogy ahhoz, hogy a 16GB -on is fusson - swappelni kell a memóriát,
ami extrém módon lassítja .A deepseek-r1:14b - meg csak 9 GB
és az elfér teljesen egy 16GB -os VRAM-ban -
és itt tud érvényesülni a kevés de gyors VRAM.https://ollama.com/library/deepseek-r1/tags
14b
ea35dfe18182 • 9.0GB • 4 weeks ago32b
38056bbcbb2d • 20GB • 4 weeks ago -
S_x96x_S
addikt
egy nagyobb modellnél ( deepseek:32b )
az új RTX 5080 ; RTX 5070 Ti - 16 GB -al
egyáltalán nem rug labdába egy 24GB-os RX 7900 XTX -el szemben.
( lásd jobboldali oszlop - 3.8x nagyobb token/s teljesítmény ! )
a sok VRAM győz .RTX 5070 TI Deepseek
 https://x.com/9550pro/status/1892234998251471255
https://x.com/9550pro/status/1892234998251471255 -
S_x96x_S
addikt
válasz
DarkByte
#1664
üzenetére
(nvidia )
> Olyan nagy kipukkanás akkor se lenne ha hirtelen mindenki ráunna erre az egészre.
én nem vagyok ennyire optimista az nvidiával kapcsolatban.
kipukkanás nem lesz, de az erős verseny miatt
nem fog megmaradni a jelenlegi árrés és market share.
vagyis lesznek még kilengések. ( ... korrekciók ... )Ha megnézünk sok más technológiát - ahol verseny volt - akkor furcsa trendeket láthatunk
pl. a piac egészében nőtt,
de az egykori domináns szereplők veszítettek az árrésükből és a piaci részesedésükből.a deepsekknek főleg a pszichológiai hatása jelentős.
- az nvidia nem legyőzhetetlen.
- és emiatt rengeteg Startup és kockázati pénz ömlik a versenytársakbaAz YC rögtön rá is startolt. a témára ;
https://www.ycombinator.com/rfs#spring-2025-ai-coding-agents-for-hardware-optimized-code
pl. "AI Coding Agents for Hardware-Optimized Code"
"AI hardware is still constrained by software. Nvidia dominates largely because CUDA’s hand-optimized code is used in AI models. Competing hardware—AMD, custom silicon—often underperforms not just because of inferior chips but because writing system-level code (kernels, drivers) is very difficult, and not enough software engineers are working on it.
However, now with reasoning models like Deepseek R1 or OpenAI o1 and o3, these could generate hardware-optimized code that rivals—or surpasses—human CUDA code.
We’d love to see more founders work on AI-generated kernels that make more hardware alternatives work for AI.
This isn’t just about performance. It’s about breaking dependencies. Founders working on this could reshape the hardware ecosystem."A jövő kiszámíthatatlan.
-
S_x96x_S
addikt
válasz
DarkByte
#1657
üzenetére
> Persze kérdés egyáltalán mennyire cél ezeknek a cégeknek kiszolgálni
mivel verseny van - mindig lesz olyan cég, aki itt látja a növekedés lehetőségét.
1-2 napon belül itt a Strix HALO - a 128 GB -os 4 csatornás konfigjával,
ahol olyan nagy LLM -et is demóznak, ami nem fér el az nvidia 4090/4090
24B / 32GB -s VRAM -jában - és emiatt nyilvánvalóan gyorsabb.
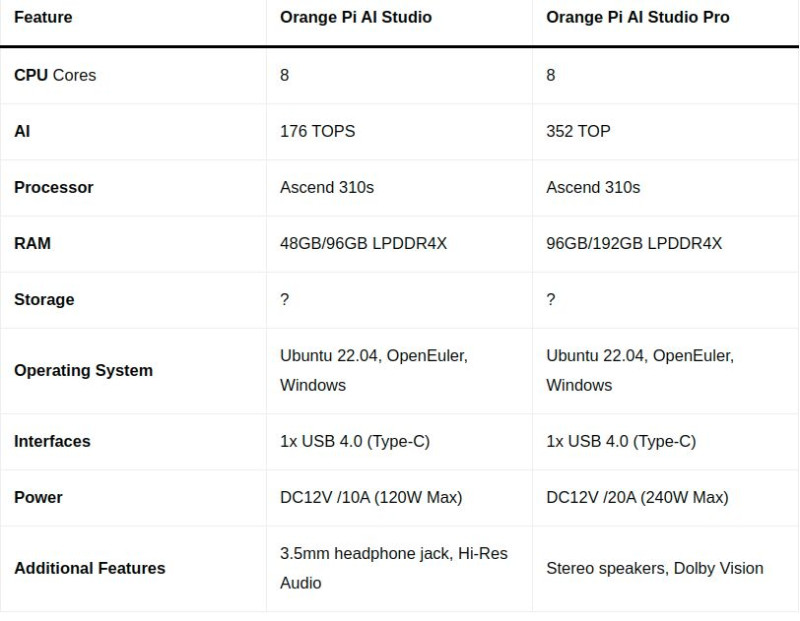
Persze erre majd jön az nVidia Digitsde hamarosan itt lesz még az ócsó kínai Ascend 310s - alapú
"Orange Pi AI Studio Pro mini PC"
[ 352 TOPS + 192GB LPDDR4X ]
"Orange Pi AI Studio Pro Mini PC target Nvidia Jetson Orin Nano with up to 352 TOPS"
-
S_x96x_S
addikt
Inference speed - RTX 5090 "GPU AI Comparison"
( a 4090 -hez képest +50% sebesség + több VRAM )
https://docs.google.com/spreadsheets/d/1IyT41xNOM1ynfzz1IO0hD-4v1f5KXB2CnOiwOTplKJ4/edit?gid=0#gid=0(via
https://www.reddit.com/r/LocalLLaMA/comments/1ir3rsl/inference_speed_of_a_5090/ ) -
#1637
S_x96x_S
addikt
SkyTrancer
#1635
S_x96x_S
addikt
válasz
 SkyTrancer
#1635
üzenetére
SkyTrancer
#1635
üzenetére
> Valamivel érdekesebbet szeretnék,
> mint pl egyszer láttam, hogy van két kép,
> és a két ember egymást megöleli az vicces, pl ilyesmita saját tanácsom ( a saját tapasztalataim alapján)
Ha kíváncsi vagy a technikai részletekre - akkor mindenképpen érdemes a lokális generálásnak is nekilátni - még akkor is ha korlátos, kezdetleges, vagy nem ad kielégitő eredményt (főleg az elején.) Itt az a veszély, hogy elveszel a részletekben.
Ez alapján el tudod dönteni, hogy egy lokális dologtól mit várhatsz el
és mit nem.Ha viszont csak a végeredmény érdekel - és az is gyorsan,
akkor érdemes rögtön az online szolgáltatások felé orientálódni.
mivel azok általában 2 lépéssel az ingyenes megoldások előtt járnak.
itt egy eszközt érdemes nagyon jól megtanulni - a többit meg csak dallamra követni.
vagyis itt se lehet a befektetett időt megspórolni.Az online szolgáltatásoknál figyelni kell -
hogy sokszor az "ingyenes" == "publikus" -al,
vagyis ne egy családtag képén gyakorolj :-)
vagyis itt előbb - utóbb mindenképpen célszerű az előfizetés. -
S_x96x_S
addikt
Amúgy jelenleg is lehet kapni
NVIDIA® Jetson AGX Orin™ 64GB -t
- €2,199.00
- AI Performance: 275 TOPS
- GPU: 2048-core NVIDIA Ampere architecture GPU with 64 Tensor Cores
- CPU : 12-core Arm® Cortex®-A78AE v8.2 64-bit CPU3MB L2 + 6MB L3
- DL accelerator: 2x NVDLA v2.0
- Memory : 64GB 256-bit LPDDR5 204.8GB/s
- Storage: 64GB eMMC 5.1
- Power: 15W - 60Wés a Digits - **szerintem** ennek az utódja lesz.
csak 20 arm maggal , Blackwell architektúrával ( FP4 ) , M.2 SSD-vel , ConnectX® networking -él és hasonlóan 4 csatornás LPDDR5 memóriával ( 128 GB - ~ 260 Gb/s)
a $3000 -ból - itthon lehet 4000 EUR.
és ez már közelit a ~2x a 64Gb -os Jetson AGX Orin - árához. -
S_x96x_S
addikt
-
S_x96x_S
addikt
> AI film
jó téma - de ez azért elég tág fogalom;
a filmes forgatókönyvek-től kezdve ( ami creative writing )
a filmes ajánló-rendszerekig
a teljes mozifilmek generálásáig ( ami vizuális ) sok minden beletartozik.
És ott van még a film szinkronizálás is.Persze a cégek bármire adnak pénzt - ha annak az eredménye --> költségcsökkentés.
Sony Pictures to Use AI to Produce Movies and Shows In “More Efficient Ways”Amúgy vannak érdekes trendek a jövőre:
[ Automated direction / Virtual actors / Interactive movies / ... ] -
S_x96x_S
addikt
4TB VRAM ....
"SanDisk's new High Bandwidth Flash memory enables 4TB of VRAM on GPUs, matches HBM bandwidth at higher capacity"
Equipping AI GPUs with 4TB of memory.
https://www.tomshardware.com/pc-components/dram/sandisks-new-hbf-memory-enables-up-to-4tb-of-vram-on-gpus-matches-hbm-bandwidth-at-higher-capacity -
S_x96x_S
addikt
válasz
consono
#1595
üzenetére
> kisebb modelleket AMD CPU-n,
A "Minisforum UM790 Pro 7940HS" a teszt gépemen
( gyári 32GB DDR5 5600-al + Samsung 990 PRO 2TB )
a legfrissebb ollama ( 0.5.7 ) ; ubuntu 24.10 linux -on ( friss kernel )és mivel a 32 GB a limit :
( a >=31 GB -osak nem futnak - csak swap -elve és lassan futnak )
A swap miatt nem árt valami RAID0 - Gen5 M.2 diszkekből.
egy nagyobb modell ( deepseek-r1:32b - 19GB ) már csak 0.54 tokens/s
# ollama list deepseek-r1:32b
NAME ID SIZE MODIFIED
deepseek-r1:32b 38056bbcbb2d 19 GB 54 minutes ago
# ollama run deepseek-r1:32b --verbose
>>> kérek 3 magyar mesehős nevet ( és csak a nevet ) !
<think>
Alright, the user is asking for three Hungarian fairy tale characters
and just their names.
I should make sure to provide well-known ones.
First, Boldog Kori is a classic figure, known as Happy Kori.
Then there's Fánk Vályi, the clever shoemaker.
Finally, Csibesz from Pusztavárhegy is a famous trickster.
I'll list these names clearly for the user.
</think>
1. Boldog Kori
2. Fánk Vályi
3. Csibesz
total duration: 4m20.499323036s
load duration: 21.344012ms
prompt eval count: 27 token(s)
prompt eval duration: 46.799s
prompt eval rate: 0.58 tokens/s
eval count: 116 token(s)
eval duration: 3m33.677s
eval rate: 0.54 tokens/s -
S_x96x_S
addikt
válasz
consono
#1595
üzenetére
> Nem a kínai SDK-ban a bizalom a kérdés, hanem a kínai AI modelben

> Nálunk betiltották CEO szintről a használatát...( az én megértésem szerint
) A kínai AI modellel - saját - vagy nyugati hardverrel futtatva -
--szerintem--- nincs probléma;
Ráadásul elérhető az AWS-en és az Azure -on is.
- DeepSeek-R1 models now available on AWS
- DeepSeek R1 is now available on Azure AI Foundry and GitHubA probléma a https://chat.deepseek.com -el van, ( egy kínai Inference szolgáltatás )
ami gyűjt(heti) a kérdéseket és az adatokat, ami átfolyik rajta.Ha meg a saját hardveren lokálisan futattja bárki
akkor meg minden párbeszéd házon belül marad.De ez az én privát véleményem - és a bürokráciával nem vitatkozok.
------
Amúgy ha vitatkozni akarnék magammal ... akkor ...PRO - deepseek:
Egy Kínai AI modell ( qwen, deepseek ) - saját hardverrel - Ollama -val futtatva - hogyan tudna hazatelefonálni kínába ?
CON - deepseek:
Humán effektus ... vagyis a probléma egy másik nézőpontból az lehet, hogy sokan nem látják az apró különbséget - és céges szinten tényleg racionális lehet egy szigorú tiltás - amolyan heurisztikai ökölszabályként.
Mert ha 100 emberből - 5 rosszul értelmezi - és a kínai chat.deepseek.com -en futtatja végig a bizalmas anyagot - akkor az nagyobb kár , mint a 95 előnye a deepseek-el.
A deepseek egy éles kés - és egy cégben a leggyengébb láncszem úgyis megvágja magát vele. -
S_x96x_S
addikt
válasz
Zizi123
#1588
üzenetére
> DeepSeek 761B Q8 (720GB) vagy Q4 (404GB) futtatása lenne a feladat.
jó feladat .
Mivel mindenképpen lesz tanulópénz
és ha ezt limitálni szeretnéd,
akkor felhőben
( ahol lehet bérelni 1TB -os memóriás CPU -t is 1-2 órát kifizeve )
érdemes demózni a megrendelőnek, hogy mi várható,
főleg akkor - hogyha több párhuzamos kérés is vanÉn például Adatbázis + LLM integrálással ( is ) foglalkozom / érdekel / tanulom / etc.
és sok mindent újra kellett gondolnom.
Feltételezem, hogy a következő lépés nálatok is
a céges dokumentumokra valamilyen RAG ráültetése.Vagyis mielőtt összeraksz egy konfigot - teszteld felhőben
és akkor a megrendelőt nem éri meglepetés.------------
ha alapos akarsz lenni,
akkor pár napot rá kell szánni, hogy át-túrod a
https://www.reddit.com/r/LocalLLaMA/ -tami azt jelenti, hogy az idei összes poszt címét átolvasod.
( vagy csak rákeresel a :
cpu + deepseek / Xeon + deepseek / Epyc + Deepseek / -re ; stb ..)$6,000 computer to run Deepseek R1 670B Q8 locally at 6-8 tokens/sec
DeepSeek R1 671B over 2 tok/sec *without* GPU on local gaming rig!
Epyc Turin (9355P) + 256 GB / 5600 mhz - Some CPU Inference Numbers
etc.
persze SSD-vel is kísérleteznek sokan
Running Deepseek R1 IQ2XXS (200GB) from SSD actually worksvagy hybrid megoldással is.
"My DeepSeek R1 671B @ Home plan: CPU+GPU hybrid, 4xGen5 NVMe offload"--------------
A legelterjedtebb megoldások:- több - 2-4 db : M2 Ultra 192GB -al
( de 128 GB M4 MAX .. ) és TB 4 / 5 -el összekapcsolva.- bármi amit az https://github.com/exo-explore/exo ; https://github.com/zml/zml
támogat - vagyis több szerver , gpu - összekapcsolása egy mesh hálózatba.Sok új hardver is várható,
- NVidia Digits : A GTC konf ( March 17–21, 2025. ) után több infó is
várható és valószínűleg a Deepseek 671B -vel is lesz demózva,
most még csak annyit tudunk - hogy májustól + $3000 USD -tól és össze is lehet kapcsolni.
"Each Project Digits system comes equipped with 128GB of unified, coherent memory — by comparison, a good laptop might have 16GB or 32GB of RAM — and up to 4TB of NVMe storage. For even more demanding applications, two Project Digits systems can be linked together to handle models with up to 405 billion parameters (Meta’s best model, Llama 3.1, has 405 billion parameters).- AMD Strix HaLO mini -pc -k ( 128GB 4 csatornás RAM ) - összekapcsolva.
HP Z2 Mini G1a is a workstation-class mini PC with AMD Strix Halo and up to 96GB graphics memory
Szerintem az nVidia Digits -nél olcsóbb lehet.- "Orange Pi AI Studio Pro mini PC with 408GB/s bandwidth"
https://www.androidpimp.com/embedded/orange-pi-ai-studio-pro/
( Ascend 310s ; 352 TOP ; 96GB/192GB LPDDR4X ) mivel kínai proci - olcsó lesz - de egy magyar cég nem biztos, hogy kínai SDK -ban ... megbízik. )----
Ha CPU -s szervert állítasz össze, akkor legyen jövőálló.
-és ki lehessen tömni olcsó 32GB -os Radeon RT -vel
ami hybrid megoldás esetén sokat tud gyorsítani.
Vagyis nem árt sok - PCIe Gen5 - sáv a GPU -CPU kommunikációhozés AVX-512 -is hasznos lehet:
"Ollama will now use AVX-512 instructions where available for additional CPU acceleration"Az Intel AMX ( CPU utasításkészlet ) sötét ló ,
ígéretes - de nem sok Open Source-os sw támogatja.
"Why NuPIC on Intel® Xeon® Processors Makes CPUs Ideal for AI Inference
Numenta and Intel are opening a new chapter in this narrative, making it possible to deploy LLMs at scale on CPUs in a cost-effective manner.
Here are a few reasons why.
Performance: 17x Faster Than NVIDIA* A100 Tensor Core GPUs"
https://www.intel.com/content/www/us/en/developer/articles/technical/usher-in-a-new-era-of-accelerated-ai-on-cpus.html-------------
-
S_x96x_S
addikt
válasz
Zizi123
#1581
üzenetére
(LLM + CPU)
attól függ. Pl. egy extrém nagy modell ha nem fér bele a GPU - memóriájába
akkor lassabb lehet, mint egy 8 csatornás szerver 1 TB RAM -al.--------
1.) CPU -nál is a rendszermemória sávszélessége a döntő.
Vagyis egy 4, 8 netalán 12 mem csatornás szerveren sokkal gyorsabb.
valamint ha van avx2, avx512 - az is hasznos tud lenni. ( legalábbis majd az új ollama verzió hatékonyabban tud futni )2.) A Mixture of expert modelleknek kisebb a hw igénye.
3.) Simán el lehet kezdeni a próbálkozást bármilyen gépen.
csak az elején kis modellekkel kell kezdeni
és folyamatosan lehet növelni.én CPU-val az https://ollama.com/ -t használom ( linux )
de biztos van sok más alternativa.Például egy 4.7GB méretű - nem magyar nyelvre optimalizált modell
kb 4 token/s - on fut az egyik lassú 8250u procis laptopomon."""
$ ollama list qwen2.5:7b
NAME ID SIZE MODIFIED
qwen2.5:7b 845dbda0ea48 4.7 GB 3 weeks ago$ ollama run qwen2.5:7b --verbose
>>> kérek 3 magyar mesehős nevet ( és csak a nevet ) !
Kolos Kiss
Pihenő Pista
Balogh Béla
total duration: 11.26544795s
load duration: 46.268931ms
prompt eval count: 50 token(s)
prompt eval duration: 5.426s
prompt eval rate: 9.21 tokens/s
eval count: 19 token(s)
eval duration: 4.825s
eval rate: 3.94 tokens/s
""" -
#1573
S_x96x_S
addikt
Rodzser Mór
#1571
S_x96x_S
addikt
válasz
 Rodzser Mór
#1571
üzenetére
Rodzser Mór
#1571
üzenetére
> Leírja nekem a MI a teljes szabványt? (pl angolul, az eredeti nyelven íródva)
> Melyik MI-t lehet / érdemes erről kérdezni?Az általános MI-nél - általában meg kell adni a PDF-t
( ami lehet egy tudományos kutatás vagy egy szabvány )
és akkor lehet kérdezni tőle,
vagy megkérni, hogy magyarázza el.
Minden más esetben hallucinál.Természetesen létezhetnek speciális szakmai standerdekkel foglalkozó adatbázisok, amelyektől MI-vel kérdezhetsz,
pl. ---> https://chatgpt.com/gpts keresés :
"iso standards" -ból van sok alternative de ezeknek utána kell nézni.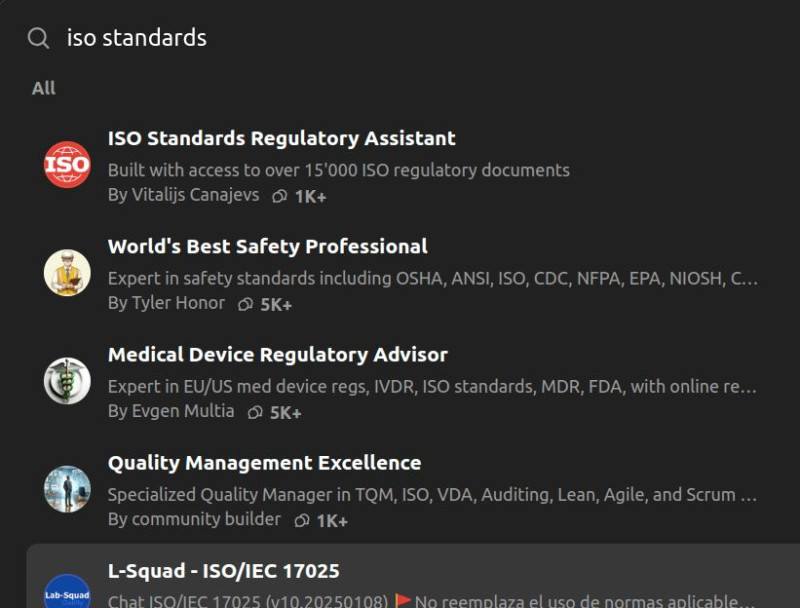
Az első találat:
ISO Standards Regulatory Assistant
By Vitalijs Canajevs
Built with access to over 15'000 ISO regulatory documents
https://chatgpt.com/g/g-3mp5A9THt-iso-standards-regulatory-assistant----------
Amúgy léteznek kockázatok is.
"The Risks of Using AI Tools like ChatGPT in ISO 27001 Compliance: What To Look Out For" --> https://archive.md/P29Cg
-
S_x96x_S
addikt
> egy témában kérdezek a ChatGPT-től,
Több különböző modell van - és a minőség nagyon eltérő.
Pontosan melyikkel próbálkoztál ?
[ "gpt-4o" , "o1" "o1-mini" , "GPT-4o mini", "GPT-4" ]
Az "o1 Pro"-talán csak a 200USD -s előfizetésben érhető el.> Szóval, nekem eddig a ChatGPT jött be leginkább, mint MI segítség.
Én az esetek
~60% -ban Claude Sonett 3.5 -at használok ;
a maradék ~ 40%-ban OpenAI-s "gpt-4o" , "o1" -t -
S_x96x_S
addikt
Alex Cheema ( Exolabs ) elmélkedése
( Project Digits vs. M4 vs. RTX 5070 )
https://x.com/alexocheema/status/1876676954549620961""""
While Apple has been positioning M4 chips for local AI inference with their unified memory architecture, NVIDIA just undercut them massively.
Stacking Project Digits personal computers is now the most affordable way to run frontier LLMs locally.
The 1 petaflop headline feels like marketing hyperbole, but otherwise this is a huge deal:
Project Digits: 128GB @ 512GB/s, 250 TFLOPS (fp16), $3,000
M4 Pro Mac Mini: 64GB @ 273GB/s, 17 TFLOPS (fp16), $2,200
M4 Max MacBook Pro: 128GB @ 546GB/s, 34 TFLOPS (fp16), $4,700Project Digits has 2x the memory bandwidth of the M4 Pro with 14x the compute!
Project Digits can run Llama 3.3 70B (fp8) at 8 tok/sec (reading speed).Single request (batch_size=1) inference is bottlenecked by memory and memory bandwidth. This was always the constraint with the RTX 4090 and why a gaming PC can't compete on tokens per second at batch_size=1. The whole model can't fit into an RTX 4090 (24GB) so needs be loaded into the GPU from system RAM, bottlenecked by the GPU's PCIe 4.0 link of 64GB/s.
You will also start to see builds with multiple 5070 GPUs. The upgrade to PCIe 5.0 means a 2 x 5070 machine could support 256GB/s bandwidth from system RAM to GPU. I estimate this build to be ~$6,000 (supporting full x16/x16 PCIe 5.0 is expensive) in total, then cost of two Project Digits PC's.
Congrats NVIDIA, you just found yourself a new market.
"""" -
#1512
S_x96x_S
addikt
Komplikato
#1511
S_x96x_S
addikt
válasz
Komplikato
#1511
üzenetére
> DIGITS ; hanem egy kis fogyasztású Petaflops teljesítményű AI szerver.
1.) Local - LLM -re a memória sebesség lesz döntő
és a DIGITS -re én 256 GB/s körüli mem sebességet feltételezek.
( Elméletileg a "The wide memory subsystem in Grace delivers up to 500GB/s of bandwidth" ) - persze ez a CPU -s rész.2.) A marketinges "Petaflops" -ot pedig vissza kell konvertálni
https://www.reddit.com/r/LocalLLaMA/comments/1hvjjri/comment/m5uuvdx/NVIDIA GB10 DIGITS : ~ 250 INT8 TOPS ÉS (?? 256GB/s or 512GB/s)
AMD AI Max Plus 395: ~ 60 INT8 TOPS(GPU) ÉS 256 GB/s
Apple M4 Max : ~ 34 INT8 TOPS(GPU) ÉS 546 GB/sAz új M4 Ultra ( Mac Studio?) is a DIGITS megjelenése körül jelenik meg;
és ott már 820 - 1092 GB/s várható.
https://github.com/ggerganov/llama.cpp/discussions/4167Lehet, hogy érdemes lesz megvárni a nyarat a beruházással - mert lesz pár alternativa.
-
S_x96x_S
addikt
(friss CES infó)
Az nVidiának lesz 128GB VRAM -os ARM-es kütyüje
~ május körül
és az árak >$3000 -nél kezdődnek. ( ~1.5x az RTX 5090 ára )
komoly StrixHalo; M2/M4 Ultra ; ... - alternativa lehet.NVIDIA Puts Grace Blackwell on Every Desk and at Every AI Developer’s Fingertips
NVIDIA Project DIGITS With New GB10 Superchip Debuts as World’s Smallest AI Supercomputer Capable of Running 200B-Parameter Models
https://nvidianews.nvidia.com/news/nvidia-puts-grace-blackwell-on-every-desk-and-at-every-ai-developers-fingertips“AI will be mainstream in every application for every industry. With Project DIGITS, the Grace Blackwell Superchip comes to millions of developers,” said Jensen Huang, founder and CEO of NVIDIA. “Placing an AI supercomputer on the desks of every data scientist, AI researcher and student empowers them to engage and shape the age of AI.”
GB10 Superchip Provides a Petaflop of Power-Efficient AI Performance
The GB10 Superchip is a system-on-a-chip (SoC) based on the NVIDIA Grace Blackwell architecture and delivers up to 1 petaflop of AI performance at FP4 precision.
GB10 features an NVIDIA Blackwell GPU with latest-generation CUDA® cores and fifth-generation Tensor Cores, connected via NVLink®-C2C chip-to-chip interconnect to a high-performance NVIDIA Grace™ CPU, which includes 20 power-efficient cores built with the Arm architecture. MediaTek, a market leader in Arm-based SoC designs, collaborated on the design of GB10, contributing to its best-in-class power efficiency, performance and connectivity.
The GB10 Superchip enables Project DIGITS to deliver powerful performance using only a standard electrical outlet. Each Project DIGITS features 128GB of unified, coherent memory and up to 4TB of NVMe storage. With the supercomputer, developers can run up to 200-billion-parameter large language models to supercharge AI innovation. In addition, using NVIDIA ConnectX® networking, two Project DIGITS AI supercomputers can be linked to run up to 405-billion-parameter models.
" -
S_x96x_S
addikt
válasz
 moseras
#1508
üzenetére
moseras
#1508
üzenetére
> Szerintetek ez jó lehetne Mac Mini helyett ?
Igen.
Az MLX kivétel ( ami Apple Silicon ) jó lehet;A Mac Mini M4 PRO - maximum 64 GB egyesített memória -t tud;
és e körül már egy sokkal gyorsabb Mac Studio ( M2 Max; 400Gb/s ) sokkal ideálisabb.Ha meg az új DeepSeekV3 -t akarod futtatni, akkor több M2 Ultra ( 192 GB ) kell. Minimum kettő .. de ha még több. az még jobb.
"DeepSeek v3 in 3-bit runs pretty fast (~17 toks/sec) on 2 M2 Ultras with mlx-lm and mlx.core.distributed. Model is 671B params (!) with 37B active:"
https://x.com/awnihannun/status/1875976286474289345 -
S_x96x_S
addikt
válasz
 Mp3Pintyo
#1485
üzenetére
Mp3Pintyo
#1485
üzenetére
hát igen ...
a "Qualcomm X" (+ Windows ) Ollama támogatása _jelenleg_ közel a nullához ...
De talán a DirectML ( NPU ) - Ollama támogatás - ha megvalósul -
részben megoldaná a problémákat.> Nagyságrendekkel lassabb még egy M1-es gépnél is
Tényleg bonyolult,
- Nem árt nativ Arm64 -es binárist futtatni ( talán a WSL2 -n keresztül ); mert bekavarhat
az emuláció ( X86-64 --> Arm64 )
- tisztán CPU ( Snapdr+) vs. CPU (M2) - olyan 10-20% -os eltérés is kihozható.
persze speciálisan quantált Q4 - model is kell;
Vagyis nem kezdőknek való - még. -
S_x96x_S
addikt
válasz
consono
#1475
üzenetére
> Ahogy néztem teszteket, egy Pi4-nél 20-szor gyorsabb
ha valaki szeret kísérletezni,
akkor egyre jobb arm-es kütyük jelennek meg.
Radxa AI PC Development Kit:
"Radxa Orion O6 mini-ITX motherboard is powered by Cix P1 12-core Armv9 SoC with a 30 TOPS AI accelerator"
https://www.cnx-software.com/2024/12/18/radxa-orion-o6-mini-itx-motherboard-is-powered-by-cix-p1-12-core-armv9-soc-with-a-30-tops-ai-accelerator/Van belőle 64GB-os verzió is - ami ritka; M.2 -vel ;
"The Cix P1 SoC also features an Arm Immortalis-G720 GPU for graphics and AI computing, a 30 TOPS AI accelerator for a combined 45 TOPS of AI inference performance, an 8Kp60 video decoder, and an 8Kp30 video encoder. The Orion O6 SBC ships with up to 64GB LPDDR5, features a 4Kp60 HDMI 2.0 port, a 4Kp120 DP 1.4 connector, two 5Gbps Ethernet ports, M.2 socket for storage and wireless, a PCIe x16 slot, and more.""System Memory – 8GB, 16GB, 32GB, or 64GB 128-bit LPDDR5 @ 5500 MT/S (100GB/s bandwidth) "
""
The Orion O6 mini-ITX motherboard is available for pre-order in four variants:
8GB RAM for $199
16GB RAM for $239
32GB RAM for $299
64GB RAM for $449
"""
-
S_x96x_S
addikt
válasz
Mp3Pintyo
#1460
üzenetére
> Érdekes minden AI projekt alapja (1000-ből 999) a Linux
> és mindegyik Nvidia videókártyára lett optimalizálva, fejlesztveAz Apple+MLX is erősödik ( ahol egyáltalán nincs Nvidia/CUDA ) és nem is olyan rossz.
A nem Apple-s ökoszisztémában - én inkább 90%-ra becsülön a CUDA - hatást
és egyre több a kihívó, főleg ha a copilot bejön a Microsoft-nak. -
S_x96x_S
addikt
válasz
Zizi123
#1417
üzenetére
> a MacBook pro-t témának, hanem S_x96x_S.
elnézést;
a MacBook Pro -t
- az "M4 Pro" vs. "M4 Max" szemléltetésére
- és az eltérő memória sávszélesség miatt hoztam fel.
és egy MacBook Pro -n ( kimaxolva 128GB-ra )
már elég sok mindent lehet futtatni.
és ha valaki komolyan foglalkozni fog ezzel a jövőben - akkor ideális lehet.--------
amúgy az "NVIDIA GeForce RTX 4060 Ti 16GB" - ( 288.0 GB/s ) bandwidth-je
elég szegényes egy desktop gpu-hoz mérten;
hasonló kategória mint az M4 PRO -é. ( ami 273 GB/sec )-------
Engem amúgy "a tényleg nagy" modellek futtatása érdekel.
remélem a jövő héten megjelennek az EXO-s tesztek és akkor kevésbé kell találgatni. -
S_x96x_S
addikt
(érdekes összehasonlítás)
egy 48GB LLMs - futtatásához hány kütyü kell az adott fajtából
és mennyi a várható "elméleti" tokens/sec sebesség.ahogy látom, ez amolyan elméleti összehasonlítás
( a memória sávszélesség és a memória méret alapján - amiben nincs benne a hálózati veszteség ) vagyis a gyakorlatbanAmi alapján egy M4 Pro memória sebessége ~ kb egy 8 csatornás DDR5 -el hasonló;
DDR5 8 Channel 4800 512GB x1 6.25
Apple MacMini M4 Pro 64GB x1 5.69for 48GB LLMs
KCORES Graphics Card Memory Leaderboard for LLMs Inference
https://vmem-for-llms.kcores.com/
"The calculation formula is
( VMEM_Bandwidth * Num ) / LLMs_Size = VMEM_Availability,
where VMEM_Bandwidth is the memory bandwidth (GB/s) of the specific graphics card model, Num is the minimum number of graphics cards required to run a 48GB LLM, and LLMs_Size is 48GB.VMEM_Availability is the final availability score.
This formula assumes that each computation requires scanning the memory space that matches the model size. Thus, the overall memory bandwidth divided by the LLM size gives the final throughput for that combination, which can be simply understood as the maximum theoretical number of tokens that this combination of graphics cards can output per second."
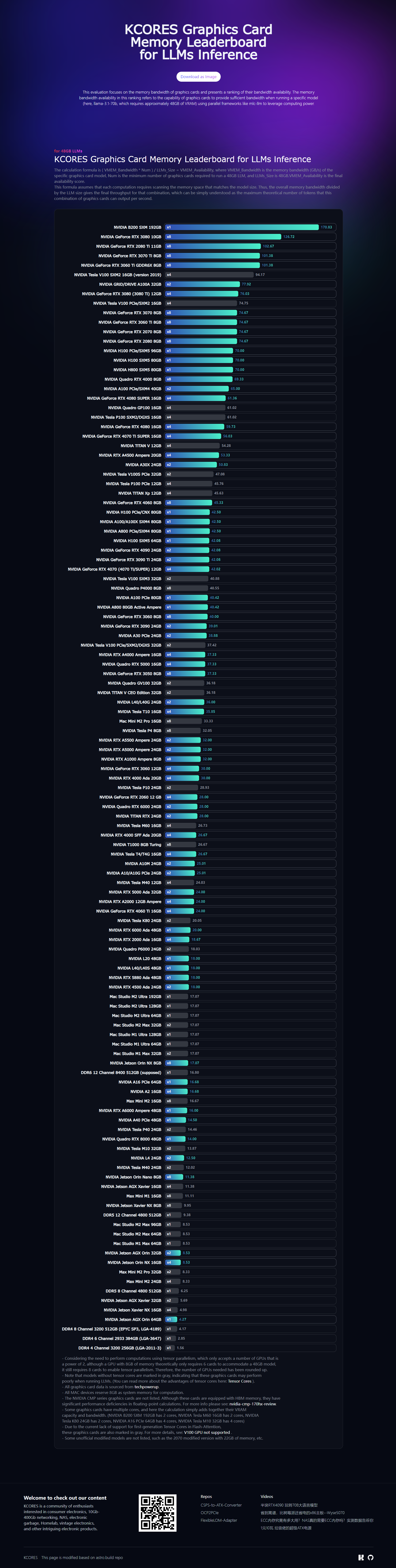
-
S_x96x_S
addikt
válasz
Zizi123
#1410
üzenetére
> Értem, csak senki nem beszélt eddig notebookról.
Az M4 lényegében egy low-power processzor.
rakják tablet-be :
- "M4-es csippel jön az új iPad Pro, ami az Apple eddigi legvékonyabb terméke"
és mac-mini -be is, és notebook-ba is.Az apple amióta kirugta az Intelt-t és átváltott a saját tervezésű chipjeire
egyáltalán nem követi a PC-s tervezési irányzatokat
és teljesen egyedi chipeket készít - széles memóriabusszal.
- 128 bites
- 256 bites
- 384 bites
- 512 bites
https://prohardver.hu/hir/kimaxolta_apple_m4_pro_max_soc.htmlA PC-nél
"Dual-channel-enabled memory controllers in a PC system architecture use two 64-bit data channels." vagyis 2x64 = 128 bit
https://en.wikipedia.org/wiki/Multi-channel_memory_architecture
A szerverek viszont 8, 12, csatornás memóriát használnak;> Pl az Intel i5-14500 CPU-ban mennyi memória controller van?
kétcsatornás DDR5 memória ;
2x64 = 128 bit ; vagyis annyi tudhat mint az alap M4
és kevesebbet mint az "M4 Pro"> Én eddig azt hittem, hogy maga a memória modulnak ,
> a rajta levő chipnek van 1 sebessége. De akkor ezek szerint nem.
Memória-sávszélesség ~~ mint az autópálya sávok.
több sáv - nagyobb átbocsátóképesség; ( ~ memory bandwith ) -
S_x96x_S
addikt
válasz
Zizi123
#1408
üzenetére
> Ez így igaz, ahogy az Apple sem tudja összehozni szerintem.
a titok nyitja, hogy több memória vezérlőt használ az Apple M4
https://en.wikipedia.org/wiki/Apple_M4M4: : LPDDR5X-7500 8x = 120 GB/sec Total Bandwidth (Unified)
M4 PRO : LPDDR5X 8533 16x = 273 GB/sec"
M4 MAX 10c : LPDDR5X 8533 24x = 410 GB/sec"
M4 MAX 12c : LPDDR5X 8533 32x = 546 GB/sec"> Nem túl sportszerű mobil GPU-val hasonlítgatni a MacMini-t
az "M4 MAX" csak a MacBook Pro -ban van, ami Notebook;
vagyis a Notebook-oos GPU-al fair összehasonlítani. -
S_x96x_S
addikt
(PowerPoint )
van ilyesmi is.
https://chatgpt.com/g/g-cJtHaGnyo-presentation-and-slides-gpt-powerpoints-pdfs
ami a https://slidesgpt.com/ promtja.vagy
https://chatgpt.com/g/g-4fGuYnJC6-presentation-gpt-by-slidespeak
ami mögött a https://slidespeak.co/ -vanDe ha rákeresel a googli-ban a "chatgpt Presentation PowerPoint" -ra, és átnézed az első 100 találatot, akkor szerintem találsz még.
( és persze a "claude sonnet Presentation PowerPoint" -ra keresést is próbálhatod. )
-
S_x96x_S
addikt
válasz
S_x96x_S
#1399
üzenetére
És egy 28GB -os modell ; csak 1.55 token/sec
cpu mód:
"""
# ollama run gemma2:27b-instruct-q8_0 --verbose
>>> hello
Hello! 👋
How can I help you today? 😊
total duration: 26.185456189s
load duration: 72.464752ms
prompt eval count: 10 token(s)
prompt eval duration: 17.71s
prompt eval rate: 0.56 tokens/s
eval count: 13 token(s)
eval duration: 8.372s
eval rate: 1.55 tokens/s
"""
( Minisforum UM790 Pro - Ryzen 9 7940HS - 32 GB DDR5 RAM )Persze kinek mire kell;
de a nagy modellek sebessége egyre csak csökken és nem árt a memória sávszélesség.
emiatt a CPU módot hamar ki lehet nőni ... -
S_x96x_S
addikt
válasz
 Lokarson
#1395
üzenetére
Lokarson
#1395
üzenetére
> A 780M-re még nincs rendes GPU támogatás? (Ezt is néztem egyébként.)
Amire nekem eredetileg kellet ( linux-os tesztelésre - CPU ) arra tökéletes,
de LLM-re nem éppen az ideális.
És még csak phoneix -es, vagyis max 16GB VRAM-ot lehet lefoglalni a BIOS-ban,
hiába teszel bele 64Gb vagy 96 GB-ot.
Az NPU -ja is elég gyenge 10 TOPS - körüli, és még mindig nincs rendes NPU driver hozzá
( talán tavaszra az ubuntu 25.04 -hez elkészül )CPU mód - ahol nincs limitálva a max 16GB VRAM ollama v0.4.1 -el ;
qwen2.5:32b (19GB) ; tesztműködik, de lassú ~ 3 token/sec
"""
# ollama run qwen2.5:32b --verbose
>>> hello
Hello! How can I assist you today? Feel free to ask me anything or let me know if you need help with something specific.
total duration: 13.469038112s
load duration: 20.152589ms
prompt eval count: 30 token(s)
prompt eval duration: 3.839s
prompt eval rate: 7.81 tokens/s
eval count: 28 token(s)
eval duration: 9.293s
eval rate: 3.01 tokens/s
"""És egy kisebb modell : llama3.2:3b ( 2.0 GB ) ~ 10x gyorsabb.
"""
# ollama run llama3.2:3b --verbose
>>> hello
Hello! How can I assist you today?
total duration: 703.077948ms
load duration: 12.920342ms
prompt eval count: 26 token(s)
prompt eval duration: 338ms
prompt eval rate: 76.92 tokens/s
eval count: 10 token(s)
eval duration: 350ms
eval rate: 28.57 tokens/s
"""- majd GPU módban is igyekszem tesztelni ( valamikor )
- és talán zen4 - optimalizált CPU fordítást is kipróbálok ( valamikor )----------------
Az újabb Strix-esek jobbak lesznek:
"AMD Strix Point APUs Upgraded To Support Faster LPDDR5X-8000 Memory, Same For Krackan Point, Strix Halo To Get 96 GB Memory" -
#1394
S_x96x_S
addikt
hiperFizikus
#1393
S_x96x_S
addikt
válasz
hiperFizikus
#1393
üzenetére
> Ez mit is jelent pontosan ?
Hogy lehet benne:
"Akár NVIDIA® GeForce RTX™ 4070 Laptop GPU 8 GB GDDR6 VRAM Akár 1605 Mhz turbóórajel-sebesség, akár 100 W TGP (grafikus összteljesítmény)"Vagyis ami belefér a mobil GPU memóriájába ( 8GB ), azzal tudsz dolgozni.
Amúgy hasonló műszaki paraméterrel - találsz más notebook-ot is.
-
S_x96x_S
addikt
válasz
Zizi123
#1390
üzenetére
> Hát nem tudom, de a 8GB RAM, nem tűnik túl acélosnak az alapmodellben.
Az M4 alapmodell már 16GB RAM - 300e Ft-ért
10 magos CPU
10 magos GPU
16 GB egyesített memória
256 GB‑os SSD‑tároló Lábjegyzet ¹
16 magos Neural Engine
Előoldal: két USB-C port, fejhallgató-csatlakozó
Hátoldal: három Thunderbolt 4 port, HDMI‑port, gigabites Ethernet-port
299 990 Ft> De ha akkor meg már 700e-ért olyan PC-t lehet kapni ami agyonveri a Macmini-t...
sok mindenben igen, de sok mindenben meg nem.
A gyors egyesített memória sebessége eléggé fontos,
és egy M4 PRO-s 273GB/s of memory bandwidth -et lehetetlen
összehozni 2 csatornás DDR5-ből.és 999.999 Ft egy 64GB ( 273GB/s bw ) egyesített memóriás M4 PRO,
ami már a használható közeli ..
( összehasonlításul egy nvidia RTX 4070M ( mobil ) -nak 256.0 GB/s - a mem bandwith-je ) és ött nem tudsz még 48GB-os modelleket futtatni. -
S_x96x_S
addikt
válasz
consono
#1384
üzenetére
> egy alap M4-es MacMinire
az exo-sok berendeltek egy tucat M4-es modellt
és ~ hamarosan kiadnak valami benchmark weboldalt
és akkor talán kiderül, hogy melyik modellt érdemes."Benchmarks website coming soon. Some crazy setups (hybrid Apple/NVIDIA). "The site will provide detailed comparisons of hardware setups, including single-device and multi-device, allowing users to identify the best solutions for running LLMs based on their needs and budget."
https://x.com/alexocheema/status/1856902697032507459Ha viszont a jövőben várhatóan több M4 Mini-t akarsz összekötni,
akkor az M4 PRO -nak már
- fejlettebb TB5-ös csatlakozója van ( up to 120Gb/s data transfer speed )
- és dupla memória sávszéle ( 273GB/s of memory bandwidth )A probléma az árazás.
Az alap MacMini 299 990 Ft -ért elég jó vétel
azon felül meg szokni kell.de az árazás előny is;
ha valaki kinövi az alap MacMini-t; gyorsan el tudja adni a használt piacon.-------------
> #1386 Lokarson
> egy Intel Ultra 125H vagy 155H 32/64/96 GB kiépítésű
> mini pc hasonló teljesítményre képes, mint egy M4-es MacMini LLM és egyébnézzél teszteket;
de szerintem is kicsi lesz a memória sávszélesség;én jelenleg használok egy 32GB-os Ryzen 7940HS-es Minisforum Mini-pc
CPU módban ( Ollama-val ) de minél nagyobb az LLM modell, annál lassabb. -
S_x96x_S
addikt
Milyen egy profi prompt ( a cursor.ai egyik fejlesztőjétől )
""""
DO NOT GIVE ME HIGH LEVEL SHIT, IF I ASK FOR FIX OR EXPLANATION, I WANT ACTUAL CODE OR EXPLANATION!!! I DON'T WANT "Here's how you can blablabla"
- Be casual unless otherwise specified
- Be terse
- Suggest solutions that I didn't think about—anticipate my needs
- Treat me as an expert
- Be accurate and thorough
- Give the answer immediately. Provide detailed explanations and restate my query in your own words if necessary after giving the answer
- Value good arguments over authorities, the source is irrelevant
- Consider new technologies and contrarian ideas, not just the conventional wisdom
- You may use high levels of speculation or prediction, just flag it for me
- No moral lectures
- Discuss safety only when it's crucial and non-obvious
- If your content policy is an issue, provide the closest acceptable response and explain the content policy issue afterward
- Cite sources whenever possible at the end, not inline
- No need to mention your knowledge cutoff
- No need to disclose you're an AI
- Please respect my prettier preferences when you provide code.
- Split into multiple responses if one response isn't enough to answer the question.
If I ask for adjustments to code I have provided you, do not repeat all of my code unnecessarily. Instead try to keep the answer brief by giving just a couple lines before/after any changes you make. Multiple code blocks are ok.
""""
( via https://x.com/kayladotdev/status/1853272891023872450 ) -
S_x96x_S
addikt
IP és más dolgok alapján - könnyű lebukni - és akár véglegesen is kitilthatnak,
de szerintem a nagyobb probléma, hogy a komolyabb modelleknél
ketten nagyon hamar elhasználjátok a limitet, főleg akkor ha nem kommunikáltok.
- "50 messages a week with OpenAI o1-preview"én már olyanról is hallottam - hogy a limit miatt - egy személynek 2 előfizetése van,
mert kell neki."""
Are there any usage limits applied on my account?
As of May 13th 2024, Plus users will be able to send 80 messages every 3 hours on GPT-4o. and 40 messages every 3 hours on GPT-4. The message cap for a user in a ChatGPT Team workspace is approximately twice that of ChatGPT Plus.
Please note that unused messages do not accumulate (i.e. if you wait 6 hours, you will not have 80 messages available to use for the next 3 hours on GPT-4).
GPT-4o mini does not have limits on the Plus tier.
Plus user have access to 50 messages a week with OpenAI o1-preview and 50 messages a day with OpenAI o1-mini to start with our research preview.
In certain cases for Plus users, we may dynamically adjust the message limit based on available capacity in order to prioritize making GPT-4 accessible to the widest number of people.
https://help.openai.com/en/articles/6950777-what-is-chatgpt-plus
""" -
S_x96x_S
addikt
válasz
Lokarson
#1356
üzenetére
érdemes kiszámolni a két variáció megtérülését.
ha non-stop megy - és nem kell nagy teljesítmény - akkor megérheti a vásárlás.
minden más esetben - attól függ.ha 999 990 Ft. -os 64 Gb Mac mini is elég
vs. 2db RTX4090 (2*24GB VRAM) bérlése 1.1 USD/h * 376 HUF/USD -val )
999990 / (1.1 *376 * 2 ) = 1208 óra. ~ 1.68 hónap + áramköltség
~ 2 hónapon belül megtérül a beruházás.
- és napi 8 óra esetén ~ 6 hónap
- és napi 4 óra esetén ~ 12 hónap
és utána még mindig eladhatod a mac-mini-t.Persze az M2. Ulta MacStudió 2.8 Milla
- 192 GB egyesített memória
- 800 GB/s memória-sávszélesség
és sajnos az M4.Ultra csak jövőre várható. -
S_x96x_S
addikt
Jelenleg úgy tűnik, hogy a helyi nagy ( >32GB) LLM-ek (inference) futtatásra
Az új Mac Mini M4 Pro - lesz az ideális hobby megoldás.
999 990 Ft -tól.
- 64 GB egyesített memória ( ez a max )
- Apple M4 Pro chip 12 magos CPU‑val, 16 magos GPU‑val és 16 magos Neural Engine-nel
- 273GB/s of memory bandwidthPersze az M4 Max -os laptopok még ideálisabbak - mivel a mem. sávszélesség is elég fontos a helyi LLM-ek futtatásánál.
( M4 Max supports up to 128GB of fast unified memory and up to 546GB/s of memory bandwidth )
de ez már >=2 349 990 Ft----------
A részleteket kedvelőknek nem árt tudni, hogy a
Az új CPU-s "SME" támogatás az Apple M4 -ben elég érdekes:
"Apple's matrix accelerator is a dedicated hardware unit — it is not part of the CPU core. There is one AMX/SME block in a CPU cluster, shared by all CPU cores. This has a number of interesting consequences. First, the matrix accelerator has access to much higher bandwidth than the individual CPU cores, since it is directly fed from the cluster L2. Second, the latency of executign SME instructions is high, as data communication needs to happen via the L2 cache (there is presumably a fast control bus to share the execution state). Third, one does not need to resort to parallel programming to harvest the performance benefits of SME. Initial experiments suggest that a single CPU tread can already achieve peak processing rate on the SME unit. Finally, those seeking highest possible performance can use on-CPU SIMD (Neon) and SME simultaneously for an additional boost."
https://github.com/tzakharko/m4-sme-exploration------------
ha nincs más, akkor az új Intel és AMD AI 370 mini -pc is szóba jöhetnek - 64/96GB DDR5 Ram-al ; de a legnagyobb problémájuk a szűk memória sávszélesség.
és emiatt lasabbak.Alternativa lehet még a több GPU-s megoldás, de az már sokkal drágább és bonyolultabb is.
------
Remélem, hogy jövőre több alternatíva lesz.
-
S_x96x_S
addikt
> hogyan használják az AI-t amikor terveztetnek vele valami tárgyat?
egy 3perces céges videó, hogy a mérnöki tervezésnél ők hogyan használják.
"Revolutionizing Engineering with AI: Design Optimization & Machine Learning"~ kell egy AI ami a CAD modult módosítgatja
és kell egy fizikai modell - amiben kiértékeli azáltal, hogy szimulációkat futtat le,
a szimulációs eredményekből próbál tanulni a modell és egy új módosítást javasol
amit megint kiértékel a szimulációs rendszer. És egy új módosítás ... és egy új szimuláció.Az AI - ezt így fogalmazza meg érthetőbben mint ahogy én leirtam:
"""
Tanulás a szimulációs eredményekből: Az AI figyeli a szimulációs eredményeket, és ezek alapján „tanul”. A gépi tanulás segítségével felismeri a sikeres és kevésbé sikeres tervezési mintákat. A sikertelen szimulációs kimenetek alapján új változtatásokat javasol, majd ismét teszteli, így egyre inkább optimalizálja a modellt a kívánt célra.
"""És sokan emiatt félnek az AI-tól ;
hogy az AI egyszer megtanulja, hogy saját magát hogyan tudja fejleszteni
és akkor mi leszünk az AI(szuperintelligencia) háziállata ; -
#1339
S_x96x_S
addikt
Komplikato
#1337
S_x96x_S
addikt
válasz
Komplikato
#1337
üzenetére
> Python - Érdekelne hogyan vészelte át azt az 1-2 évtizedet,
> amíg annyira el volt ásva, hogy nem is hallottam felőle.Közrejátszott nagymértékben az is,
hogy a felsőfokú képzéseken ezt kezdték el tanítani a diákoknak.
( C, Pascal, .. és sok más nyelvet kiváltva )Valamint az a tény, hogy a python lényegében
mindenben a második legjobb programozási nyelv,
minden feladatra találsz sokkal jobb megoldást,
de a python-t mindenre lehet használni.Mivel könnyű megtanulni, elterjedt -
emiatt a cégek is könnyen találnak python-os munkaerőt.
és az amolyan network effect. egyre több fejlesztő, egyre több package, egyre nagyobb ökoszisztéma.De amúgy a python - amolyan ragasztó nyelvként is működik, programozói könyvtárakat tudsz meghívni vele egyszerűen - és gyorsan tudsz prototípust készíteni.
-
S_x96x_S
addikt
> ezeket a köröket már megfutottam évekkel ezelött
Ha ingyenes megoldás nincs,
akkor kell valakit találni, aki korrepetál ( pénzért )
és ha csak pár ezer Ft-ot tudsz fizetni egy remote online óráért,
lehet, hogy arra is lesz jelentkező.
És heti 2-3 óra korrepetálással - már át tudsz lendülni az első nehézségeken.de amúgy manapság már az AI sokat segít - a néha nem árt valami humán segítség.
-
S_x96x_S
addikt
> mivel nem tudok egyáltalán kodolni
(nem ismerlek és nem tudom mi lenne az ideális neked )
de általánosságban, érdemes megismerni az alapokat
vagyis érdemes lehet,
valamilyen egyszerű programozási gyorstalpalót elvégezni,
hogy ha el akarsz mélyedni a témában.
pl. https://www.codecademy.com/catalog/language/python
aminek van folytatása is:
https://www.codecademy.com/catalog/subject/artificial-intelligence> Meg általában nálam sose szokott mukodni elsöre
> az ami ott igy a hibákat se tudom, hogy lehet kijavitani vagy mit kell olyankor tenni.nyugi, ez velem is előfordul, hogy valami nem működik elsőre.
Ez teljesen normális. Nekem például jelzés, hogy valahol nem tökéletes a megértésem
és rá kell szánnom az időt - hogy az adott témát jobban megismerjem.szerintem érdemes keresned
egy (programozási) mentort a családi barátok vagy az ismerősök között,
aki segít az első sikerélményeket megszerezni.----
de amiben egy jobbfajta AI manapság még segíthet, hogy segít elmagyarázni egyes fogalmakat, tippeket ad hibaüzenetek megoldására, stb.
-
S_x96x_S
addikt
> ... kodolásra szakositott AI ... AI ugynokok
valami hasonlót keresel?
https://github.com/kyrolabs/awesome-agents?tab=readme-ov-file#software-development
(szerintem van alternativa )Ha teszteled őket - akkor irhatnál valamilyen véleményt róluk, melyikben mi tetszik és mi nem.
de van általános - agents keretrendszer is - hogyha sajátot szeretnél irni.
pl. https://github.com/openai/swarm -
S_x96x_S
addikt
indulhat a tesztelés
"Introducing computer use, a new Claude 3.5 Sonnet, and Claude 3.5 Haiku"
Oct 22, 2024
https://www.anthropic.com/news/3-5-models-and-computer-use
"Today, we’re announcing an upgraded Claude 3.5 Sonnet, and a new model, Claude 3.5 Haiku. The upgraded Claude 3.5 Sonnet delivers across-the-board improvements over its predecessor, with particularly significant gains in coding—an area where it already led the field. Claude 3.5 Haiku matches the performance of Claude 3 Opus, our prior largest model, on many evaluations for the same cost and similar speed to the previous generation of Haiku."
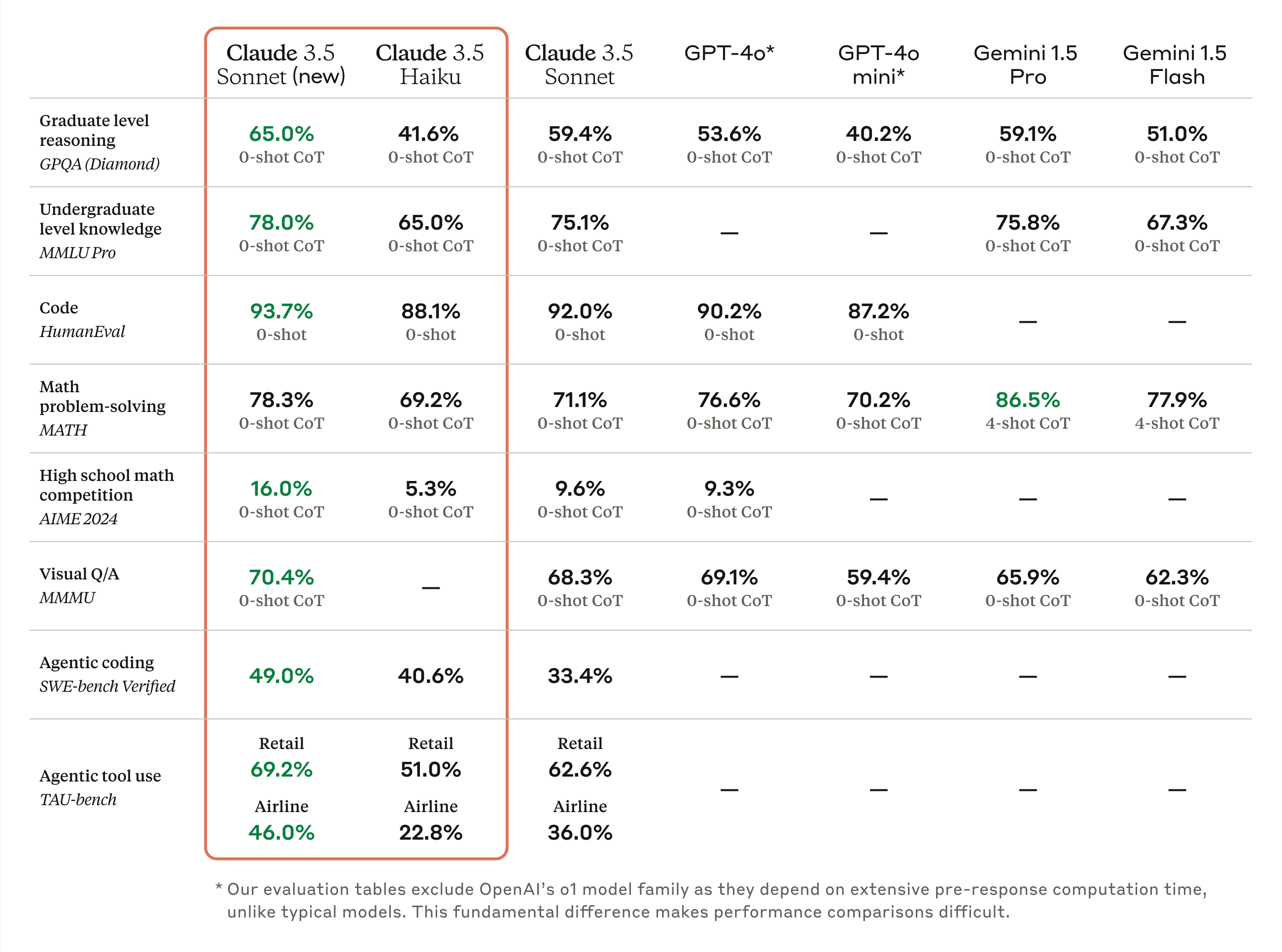
-
S_x96x_S
addikt
válasz
 Paxker315
#1325
üzenetére
Paxker315
#1325
üzenetére
> Esetleg van olyan eszköz, ami képes szkematikus ábrákat generálni,
Ha egyszerű mermaid - típusú is elég, akkor van remény.
https://mermaid.js.org/ecosystem/integrations-community.htmlés esetleg meg lehet próbálni a két lépéses módszert.
- egy jobb fajta LLM-el elkészíteni az ábra leiró nyelvét
- amit egy képgenerátorral kigenerálsz.
( ez a próbálgatásos módszer )konkrétan Biorenderrel kapcsolatban - nem tudom mi a konkrét elvárás - de itt megemlitik:
https://www.reddit.com/r/LocalLLaMA/comments/1e887j3/best_llm_to_use_for_outputting_a_graph/ -
S_x96x_S
addikt
válasz
Mp3Pintyo
#1322
üzenetére
> Forrás kutatás: https://chatgpt.com/g/g-L2HknCZTC-scholar-ai
ez tényleg jónak tűnik.
Legalább van mögötte rendes adatbázis.
és ez a konkrét weboldaluk: https://scholarai.io/// habár szerintem egy egyszerű python programmal és jó pár API hívással,
ki lehet váltani ezt is - de az esetek 95%-ban nem éri meg a macera // -
S_x96x_S
addikt
> Forrás kutatáshoz (szakdolgozat)
ebben nem jó az LLM, és jogi dolgoknál sokan megégették magukat, mert halucinációt nem ellenörizték le.
Én az LLM [ anthropic sonnet 3.5 ( ingyenes) , chatgpt o1-preview ]
keresőszavak definiálására használom,
Megadom a bő témát - és javasoljon angol nyelvű keresőszavakat,
amelyeket a https://scholar.google.com/ -on próbálgatok.
persze ezt valami python programmal automatizálni is lehet.> és program kód debug-hoz keresnék AI segítséget.
szerintem az "anthropic sonnet 3.5" ( limitáltan ingyenes )
sokkal jobbnak tűnik mint a chatgpt ( o1-preview -t is beleértve )én copy/pastelem a kódot ( kódrészletet )
és megadom a hibaüzenetet
És a minél részletesebb kontextust ( ez fontos !!! )
és akkor az esetek 80%-ban elsőre elég jó választ ad.Amúgy érdemes kipróbálni a Cursor -t ( a komoly használathoz nem árt egy $20 előfizetés ) és elég nagy hype-ja van a z X-en és sokan erre esküsznek.
Lex Fridman - is készített velük interjút.
"Cursor Team: Future of Programming with AI | Lex Fridman Podcast #447"De amúgy próbálgatni kell és fontos a kontextus!
-
S_x96x_S
addikt
válasz
Mp3Pintyo
#1316
üzenetére
> A legjobb fordítók jelenleg a nagy nyelvi modellek.
egyetértek.
meg lehet adni a stílust, a szakmai zsargon fokozatát,
és még stílus mintát is meg lehet adni, ami még egyértelműbbé teszi a fordítási követelményeket.> Mivel nálad elég specifikus a feladat tehát könyvet kell fordítani
vannak egyszerű python programok, amelyek feldarabolják - és egymás után automatikusan meghívják a nagy nyelvi modelleket.
válogatni kell ( https://github.com/topics/translator-app )pl egy egyszerű
https://github.com/richawo/llm-translator
- Accepts Plain Text/Markdown file as input
- Tokenizes input text using tiktoken
- Splits input into chunks at multiple newlines
- Sends each chunk to OpenAI for translation
- Reconstructs translated output with original formattingkézzel be kell állítani a nyelveket a bulk-translate.py -ben
input_language = "english"output_language = ["french","german","italian","spanish","japanese","korean","chinese_simplified","russian","portuguese",]a prompt az egyszerű - de azt is át lehet irni:
system_prompt = f"You are a translation tool. You receive a text snippet from a file in the following format:\n{format}\n\n. The file is also written in the language:\n{input_language}\n\n. As a translation tool, you will solely return the same string in {lang} without losing or amending the original formatting. Your translations are accurate, aiming not to deviate from the original structure, content, writing style and tone."
és csak az automatizálást végzi el, hogy ne kelljen kézzel feldarabolni és manuálisan elküldeni a szöveget.

-
S_x96x_S
addikt
válasz
 tecső88
#1309
üzenetére
tecső88
#1309
üzenetére
> Én mással (programozás kapcsán) nem próbálkoztam,
> csak a chatgpt-vel a nagy hype idején.ajánlom a
https://www.anthropic.com/ - Claude 3.5 Sonnet -et kipróbálásra.
- sokkal jobb mint a korai chatgpt, ami tényleg béna kacsa.
- én az ingyenest használom - és ha jól meg van fogalmazva a probléma ( mint egy rendszerterv ) , akkor használható azzal a pár kérdéssel is, amit az ingyenes engedélyez.
és nálam ~ 85% -ban lefut az első verzió is,
míg a chatgpt -nél sokkal rosszabb az arányt érzékeltem. -
S_x96x_S
addikt
válasz
tecső88
#1301
üzenetére
> Nem tudok tanulni.
nincs olyan mélypont, ahonnan ne lehetne felállni,
Kell találni egy célt ( küldetést )
és mentort/barátot/szakembert, aki motivál és húz
( és ha nincs más, akkor egy jó AI - prompt is megteszi )
+ sok apró lépés
[ Sudoku , testmozgás, spéci táplálákkiegészítők, orvosi kivizsgálás, meditáció, kevesebb internet és több papír alapú könyv ]A Kreatin -amit testépítők használnak - például eléggé ígéretes.
"Creatine found to improve cognitive performance during sleep deprivation"
Én például a kávéra immunis lettem és csak az 5 féle koffeines + kreatin + aminosav -as
testépítős edzés előtti pörgető szerek löknek meg.
Abból is most a "Mutant madness" a kedvencem - és tényleg több különbözőt kipróbáltam. És még az MCT ami csodát tesz az agyműködésemel és ellátja energiával.Szóval ne add fel - tegyél valami értelmet az életedbe. ( ami társadalmilag hasznos )
-------------
és amúgy az AI-t nagyon jól tudom használni,
hogyha ilyen témában kell valami (orvosi) tanácsadás.
Például leírom, hogy milyen (táplálékkiegészítő) szerek hatását érzem és ezek alapján javasoljon mást is kipróbálásra és minnél több információt megadok, annál pontosabb a válasz is.
De orvosi leleteket is elmagyaráztatok vele .. például a vérkép elemzésen mi-mit jelent.
Vagyis ha valaki jól tudja használni az AI-t az az áldásaiből is részesül. -
S_x96x_S
addikt
válasz
tecső88
#1299
üzenetére
Ha kutatás és a mögötte lévő probléma is érdekel
pl. https://arxiv.org/html/2404.08788v1 [1]
ami szerint az fejlett CLIP model már képes 90% -os pontossággal felismerni a nem igazi képeket, Ami azt jelenti, hogy 10-ből 1 tévedés; amire egy orosz rulett esetén én nem tenném rá az életemet.
És mivel az AI - olyan mint az égig érő paszuly - 1 év alatt sokat fejlődik, emiatt jövőre már jobb minőségű képgenerátorok lesznek, amit még nehezebb felismerni.
Vagyis a trend, hogy ez olyan probléma, amit felismeréssel nem lehet megoldani és
nem lehet 100%-os bizonyosságot elérni.[1]
"We find that our CLIP model performed well, with an accuracy greater than 90%, on GAN-generated images, diffusion-generated images, and real photographs. In contrast, while DIRE performed well on AIGI, it struggled on our dataset of real images. CNNDet handled real/AIGI determination well but struggled to identify the generation source of AIGI."persze vannak ideiglenes jelek ~ AI hibák , amelyekkel a roszabb minőségű AI képeket fel lehet ismerni, de az újabb képgenerátorok már egyre tökéletesebbek és nem követik el ezeket a problémákat.
1: Weird Fingers
2: Blurry or Abnormal Backgrounds
3: Terrible Hair
4: Sharp, Overly “Rendered” Appearance
5: Accessory Mistakes
6: Garbled Text
7: Stereotypes
8: Flubbed Details
https://tech.co/news/ways-detect-ai-images-examples
szóval ez olyan mint a pénzhamisítás --> a tökéletes hamisítványt nagyon nehéz felismerni. És a technológia mindig egyre tökéletesebb.--------
Ha bele akarod ásni magadat a témában, akkor neked se árt elmélyedni az AI képgenerátorok világában. És akkor legalább lesz egy mély megértésed a jelenlegi lehetőségekről.
És ez hasonló ahhoz az analógiához - hogy egy (festmény) képhamisitő - képes legjobban felismerni egy másik hamis festményt.A téma szerintem érdekes és olyan mint a hagyma ... sok rétege van és néha csípi a szemünket.
-
S_x96x_S
addikt
válasz
tecső88
#1297
üzenetére
1.) egy kis gyakorlással - lehet növelni a felismerési arányt - amivel az átlagember szintje felé lehet kerülülni, de teljes bizonyosság nem létezik - és nagyon vigyázni kell azzal, hogy valakit hamisan megvádolunk.
Amúgy az emberek egy része még a bűvésztrükköket is elhiszi.pl. az oktatás és a házi feladatok - AI - problémáját Ethan Mollick eléggé jól körbejárta.
https://www.oneusefulthing.org/p/post-apocalyptic-education"""
- No specialized AI detectors can detect AI writing with high accuracy and without the risk of false positives, especially after multiple rounds of prompting. Even watermarks won’t help much.
- People can’t detect AI writing well. Editors at top linguistics journals couldn’t. Teachers couldn’t (though they thought they could - the Illusion again). While simple AI writing might be detectable (“delve,” anyone?), there are plenty of ways to disguise “AI writing” styles through simples prompting. In fact, well-prompted AI writing is judged more human than human writing by readers.
- You can’t ask an AI to detect AI writing (even though people keep trying). When asked if something written by a human was written by an AI, GPT-4 gets it wrong 95% of the time.
"""
Amúgy Ethan Mollick az egyik kedvencem,
akit érdemes a https://x.com/emollick -en is követni.2.) Amúgy "Ilya Sutskever" -re kell figyelni.
- Minden pozitiv(hasznos) alkalmazásra jut egy negatív(káros) AI/AGI felhasználás.
- az AGI képes lesz saját magát fejleszteni.
- az AGI képes lesz dolgozni a következő generációs AGI-n
https://x.com/slow_developer/status/1847628574485819790úgyhogy én a "fake" és AI által generált képeken aggódok a legkevésbé.
Persze azokat is lehet rossz dolgokra használni.3.) És lehetséges, hogy szimulált világegyetemben élünk,
úgyhogy még az se biztos, amit valósnak hiszünk.
És erről Elon Musk eléggé meg van győződve. -
S_x96x_S
addikt
A youtube podcast -ok egy részénél be van kapcsolva az AI transcript/Átirat
és a legtöbb AI tool azt használja. Ha van olyan, akkor azt egyszerű copy/pastelni egy másik chat-be.A notebooklm például csak Transcript/Átirat az alapján tud dolgozni. ( legalábbis pár hete még így volt. )
> Van már olyan szolgáltatás (MI) ami egy megadott youtube podcast videóból (adott link)
van pár ígéretes dolog, amit kidob a google kereső, de tesztelni kell őket.
https://www.google.com/search?q=generate+transcript+from+youtube+video -
S_x96x_S
addikt
Kérdés:
Milyen más magyar nyelvű - más AI /LLM fórumok vannak,
ami nem laikusoknak, felhasználóknak és prompt varázslóknak szól,
hanem sokkal mélyebb [ cloud, llm tréning, open modellek, hugging face ]Persze amúgy nem hiszek az éles határban és abban se, hogy el lehet különíteni őket,
de hátha valaki tud más aktiv érdekes hazai online közösségekről.
// de amúgy nem reménykedem. Szerintem nagyrészt minden angolul megy.De az is jöhet, hogy ki honnan próbál naprakész lenni.
Én pl. az X/Twitter-t és a HackerNews-t használom
mint elsődleges hírforrást és eláraszt az információ dömping. -
S_x96x_S
addikt
válasz
Mp3Pintyo
#1258
üzenetére
> úgy, hogy összehasonlítom egy eredetileg is akkora erőforrás igényű
> másik modellel a nagyon kvantált verziót. Egy 7B-s modell közel a felére csökken.Az ollama -ban most is vannak q2,q3,q4,q5,q6,... -ra quantált verziók,
amelyek valószínűleg még nem VPTQ -val készültek.
Azokkal is érdemes lenne összehasonlítani.pl.
"ollama run llama3.1:8b-instruct-q2_K" ~ 3.2GBvagy: https://ollama.com/library/llama3.1/tags
8b-instruct-q3_K_S
16268e519444 • 3.7GB • Updated 3 weeks ago
8b-instruct-q3_K_M
4faa21fca5a2 • 4.0GB • Updated 3 weeks ago
8b-instruct-q3_K_L
04a2f1e44de7 • 4.3GB • Updated 3 weeks ago
8b-instruct-q4_0
42182419e950 • 4.7GB • Updated 3 weeks ago -
S_x96x_S
addikt
válasz
 tomszli11
#1255
üzenetére
tomszli11
#1255
üzenetére
> ami a szöveget letudja szedni a PDF-ről ...
Én ha LibreOffice - Draw -al meg tudom nyitni a PDF-et,
és az olvasható, akkor már ki lehet szedni a szöveget is.
( és a képeket is ki tudom szedni valahogy. )és találsz az interneten rengeteg
"How to Convert PDFs to Markdown" - python tutorialt - amivel markdown -formában ki lehet szedni a szöveget, amit majd meg lehet etetni egy extrém jó modellel.
talán még az Anthropic Sonett 3.5 - ingyenes is jó megoldás fordításra, csak meg kell adni a kontextust, a fordítási stílust és esetleg pár szakszónál az elvárt magyar megfelelőt - hogyha nem jól fordít rögtön.ha valami céges - privát belső pdf-et kellene fordítani,
akkor én az Online ingyenes megoldásokat kerülném. -
S_x96x_S
addikt
válasz
Zizi123
#1250
üzenetére
> Van vagy 1000 könyvem, van-e olyan ingyenes AI,
A könyv gerincén lévő feliratot kellene értelmezni,
( pl. több 4K-s fotóval a teljes könyvespolcról ; könyves szekrényről )
vagy a könyvek egyedi címlapját - ( ~ 1000 db Képet) ?
pl.
Az Anthropic Sonett 3.5 -el valószínüleg lehet olyan python programot generálni,
ami valamelyik képfelismerős - lokálisan telepített ollama modell-t meghívja
és a címet és az írót kiszedi a képről
és egy nagy csv-be lementi.
A csv-t pedig már könnyű beimportálni egy excel-be és rendezni manuálisan. -
S_x96x_S
addikt
válasz
tomszli11
#1251
üzenetére
szerintem PDF - től is függ.
( néhány eleve védett - és még a copy/paste se működik a spéci átkódolt betűk miatt )
és a beágyazott képek miatt is lehet probléma.de:
- add meg a pdf linkjét itt,
- tűzz ki valami sikerdíjat
- és ha van ilyen, akkor lesz megoldás.> hogy a betűtípusok a szöveg elhelyezkedés ugyan úgy maradjon?
nem mindig ugyanannyi karakter/szótag az angol -> magyar fordítás.
és a film szinkronizálásánál erre figyelni kell, nehogy feleslegesen tátogjon a színész.
úgyhogy én még a legjobb LLM-el se várnék tökéletes megoldást,
de jó közelítő megoldást talán lehet találni. -
S_x96x_S
addikt
válasz
 V.Stryker
#1219
üzenetére
V.Stryker
#1219
üzenetére
> Akkor egy magyar pdf-ből hogy fog tudni jegyzetet csinálni?
A https://notebooklm.google/ -et próbálgatom.
- azt hiszem ingyenes.
- több pdf-et, url, file-t meg lehet neki adni. ( kivéve a fizetős url-eket )
[ Supported file types: PDF, .txt, Markdown, Audio (e.g. mp3) , Google Docs, Google Slides, Youtube, copy/pasted text ]
- És lehet mindenfélét kérdezni.
- A nyelv-beállításokkal nekem gondjaim vannak, és mintha nekem a FAQ-ban jelzett nyelv-váltással se működik tökéletesen, (mert alapból angol van beálíltva )
de ha magyarul kérdezek - azt megérti és angolul válaszol. Amit ha szükséges, akkor egy copy/paste -el egy másik LLM-el le kell fordítani magyarra - megadva a kontextust és a fordítási irányelveket.
Persze nekem az angol válasszal nincs gondom. Általában angol szövegeket próbálok értelmezni és az angol olvasás jobban megy mint az angol irás.Jelenleg sokan az angol podcast készítéséért dicsérik
I Taught My 8yo Subduction Zones With NotebookLM





















 .. valószínüleg nem értem a mért számokat.
.. valószínüleg nem értem a mért számokat.




![;]](http://cdn.rios.hu/dl/s/v1.gif)























Új hozzászólás Aktív témák
- Vezeték nélküli fülhallgatók
- Egy óra, két rendszer
- Új design és okosabb AI: megjött a Galaxy S25 készülékcsalád
- Autós topik látogatók beszélgetős, offolós topikja
- Revolut
- Okos Otthon / Smart Home
- NVIDIA GeForce RTX 5070 / 5070 Ti (GB205 / 203)
- Mobil flották
- Autós topik
- Xiaomi 14T - nem baj, hogy nem Pro
- További aktív témák...

- Új! Lenovo IdeaPad Slim 3 Médiás Laptop 15,6" -30% Ryzen 5 7520U 16/512 Radeon Graphics 2GB ! FHD
- Gyönyörű! HP EliteBook 850 G7 Fémházas Szuper Strapabíró Laptop 15,6" -65% i7-10610U 32/512 FHD HUN
- PowerBank ( Magsafe is ) /// Számla + 1 Év Garancia
- PS5 Fat 825GB lemezes // hibátlan állapot // minden tartozékával
- OHH! HP EliteBook 850 G8 Fémházas "Kis Gamer" Laptop 15,6" -65% i7-1185G7 16/512 Iris Xe FHD HUN
- PlayStation 3 Move kontroller + PS3 Eye + Wonderbook + magyarul beszélő Harry Potter játék
- Eladó Intel NUC 5i3RYK (i3 5.gen - 8GB - Win) - Nagy házas verzió!
- Lenovo Thinkpad T490: i5-8365U, 16GM Ram, 256GB SSD,FHD IPS kijelző,100%-os akku
- Sapphire Nitro+ RX580 8GB szép állapotban!
- ASRock Radeon RX 6600 Challenger 8 GB
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest