-

GAMEPOD.hu
OLVASD VÉGIG ALAPOSAN MIELŐTT ÚJ HOZZÁSZÓLÁST ÍRNÁL!!!

Új hozzászólás Aktív témák
-

leviske
veterán
Nem az Intel zavar, hanem mikor lesüllyed egy beszélgetés az "én apukám erősebb, mint a tiéd" színvonalra. Rengeteg forrása van a cégnek, ez vitathatatlan. Viszont kijelenteni egy meg nem jelent, sőt be sem jelentett megoldásról, hogy az bizony eladásokban állva hagyja a kb 1 hónap múlva milliószámra eladott ellenfelét (gondolok ez alatt a Kaveri csöndes startja mellett a konzolok kevésbé csöndes érkeztére), az erősen szemellenzős látásmódra utal.
"a HSA lenyegi resze tul konnyen lekoppinthato"
Egy nyílt rendszerben pont ez a csodálatos. Egészen más piaci helyzetet láthatunk magunk előtt, ha az Intel "lekoppintja", mintha a MIC alap elképzelése terjed el. Arról viszont még nem sikerült meggyőzni, hogy miért annyival jobb az Intel elképzelése, hogy véleményed szerint a semmiből letudná tolni az AMD évekkel korábban megjelent megoldását. Pont az általad említett X86-64 vs IA-64 helyzet a példa arra, hogy mennyire lényeges, hogy a fejlesztők mit látnak kifizetődőbbnek használni. A Larrabee buktája és az ARM-el vívott harc pedig arra szolgáltatnak példát, hogy nem tudnak belépni csak izomból egy piacra.
Külön jegyzem meg, hogy az nVidia-t a HSA-val szembeállítani egy kicsit korainak érzem, elvégre nem a Mantle-ről beszélünk, ami a GCN köré lett megírva. A HSA és az nVidia tervei aránylag egy irányba tartanak, ami az nVidia/Intel viszonyáról nem mondható el. Emellett a HSA kapcsán sem csak az AMD-t kéne megemlíteni, ha már nyitnánk egy ilyen topikot.
-

Fiery
veterán
válasz
 leviske
#13051
üzenetére
leviske
#13051
üzenetére
"be sem jelentett megoldásról, hogy az bizony eladásokban állva hagyja a kb 1 hónap múlva milliószámra eladott ellenfelét"
En csak az eddigi altalanos piaci trendeket emlitettem. Abbol kiindulva, hogy az Intel vs. AMD CPU reszesedes a PC-kben 3:1 vagy me'g inkabb a 4:1 aranyhoz kozelit, nem tul valoszinu, hogy a trend hirtelen megforduljon csak azert, mert jon a Kaveri meg majd jovore valamikor a HSA. Bar ugy lenne, en is orulnek egy erosebb versenynek, mindenkinek jobb lenne. Csak kozben a rideg valosag az, hogy az AMD me'g akkor sem tud eladni eleg sokat, amikor jo cuccot allit elo, ami adott esetben sokkal jobb, mint a konkurens megoldas(ok). Hol vannak peldaul a Temash tabletek? Hol vannak a Kabini alaplapok, Kabini miniPC-k? Vannak elso fecskek, oke, de a Trinity is igy indult, nyogvenyelosen, es a vegen sokkal tobbet adott el a konkurencia, sajnos

"Egészen más piaci helyzetet láthatunk magunk előtt, ha az Intel "lekoppintja", mintha a MIC alap elképzelése terjed el"
A ketto nem zarja ki egymast. Sot, adott esetben a Broadwellt is ki lehetne ugy egesziteni, meg lehetne ugy "patkolni", hogy OpenCL 2.0 kompatibilis legyen -- lehet, hogy az is lesz, ki tudja.
"Arról viszont még nem sikerült meggyőzni, hogy miért annyival jobb az Intel elképzelése, hogy véleményed szerint a semmiből letudná tolni az AMD évekkel korábban megjelent megoldását."
Mikor mondtam en olyat, hogy az Intel elkepzelese jobb? En csak azt mondom, hogy ha a MIC kicsit is jol sikerul, es megtamogatjak egy olyan processzel, ami cca. 2 generacioval az AMD altal hasznalt elott jar, akkor az eleg erdekes lehet. Nem mondom, hogy utoleri a GCN2-t vagy a Carrizot (bar, az se jelent me'g meg ... sot, a Kaveri se ...), de nem is mondanam azt, hogy teljesen eselytelenul indul. Ha a MIC a Trinityt befogja iGPU-ban, mar az se lesz egy rossz eredmeny SZVSZ, tekintettel arra, hogy honnan indult par eve az Intel (a beka s***e alol)

"A Larrabee buktája és az ARM-el vívott harc pedig arra szolgáltatnak példát, hogy nem tudnak belépni csak izomból egy piacra."
Ez igy igaz, de az Intel borzaszto szivos, kitarto, nehez elkepzelni, hogy ne erjenek celt elobb-utobb. Az ARM ellen is sokaig tartott, mire osszeraktak a Silvermontot, de odaig is eljutottak.
"Emellett a HSA kapcsán sem csak az AMD-t kéne megemlíteni, ha már nyitnánk egy ilyen topikot."
Azert irtam pont azt, hogy AMD vs. Intel+nVIDIA, mert nyilvan az AMD oldalan van mindenki, aki a HSA Foundation-be belepett. A kimaradt nevek vannak a HSA ellen (vagy csak erdektelennek gondoljak?), latszolag. Meg persze az Intel es az nVIDIA egyebkent is nagy AMD konkurencia, mar evtizedek ota.
[ Szerkesztve ]
-

Abu85
HÁZIGAZDA
Senki sincs senkivel a HSA alapítvány tagjai közül. Számos cég direkt konkurense a másiknak. Nem egymást akarják segíteni és főleg nem az AMD-t. Mindenki érdektelennek tekinti azt, hogy a Samsung vagy az AMD részesedése nő-e vagy csökken. Csak azért léptek be az érintett cégek mert olyat kínál a HSA, amit más még nem kínált fel, vagy önerőből túl időigényes lenne kifejleszteni. Úgy vannak vele a cégek, hogy lerakják a szoftveres alapokat közösen aztán majd hardverből versenyeznek.
A legfőbb probléma egyébként az Android szegmentáció. A Google az OpenCL-t nagyon nem akarja, de a HSA-tól nem zárkóznak el, mert nem okoz szegmentációt, illetve a saját Renderscriptjükhöz is nagyon illik a platform. Ez a fő oka amiért az ARM-os cégek zöme ott van.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-

dezz
nagyúr
Nos, akkor a "körítés" a Jaguar CPU magok és GCN(2) CU-k között lehet akár teljesen más architektúra is, mint ahogy más is.
"Ha kiegeszitik a HSA mas elonyeivel (gyors kernel launch, jobb queing, videodriverrol valo levalasztas), akkor szinte minden elonyet atveszik a HSA-nak, anelkul, hogy HSA-nak "kellene" hivniuk."
Szinte? Csak az egyik legfőbb összetevőt hagytad ki, a HSAIL-t és a hozzá tartozó virtuális ISA-t, amik biztosítják, hogy ugyanaz a lefordított bytecode más gyártók megfelelő termékein is futhat, mégpedig a rendszer kidolgozása által viszonylag optimálisan.
"Barki, aki nem akarja magat bezarni az AMD okoszisztemajaba"
He? Már a fél világ átvette a HSA-t, tucatnyi gyártó termékei készülnek hozzá/vele.
"Egyebkent ha a MIC tenyleg HSA-szeru lesz, akkor ha OpenCL-re programozol, akkor megkapsz mindent, amit a HSA-val kapsz, legfeljebb nem pont ugyanazt a teljesitmenyt a vegen (a GCN2-t nehez utolerni)."
Kisebb teljesítmény és/vagy jelentősen rosszabb telj./fogy. Az sem biztos, hogy az Intel HW-re fejlesztett OpenCL kód jól futna máshol és fordítva. Bár ahogy az Intelt ismerem, éppen erre építenének. Ami viszont visszafelé is elsülhet.
"eddig egyetlen esetben nem sikerult (AMD64)"
Hasonló a helyzet, az Intel megint utólag próbálna másokra erőltetni egy hasonló, de mégis más megoldást.
"Csak a source végén kompatibilis (OpenCL)"
Nem. Nézd meg, mire válaszoltam: "Viszont ha az Intel lekkopintja a HSA-t, akkor neki nem kell uj forditot irnia, hanem csak a drivereket: joval kisebb melo." - Akkor nem kellene új fordítót írnia, ha a HSAIL-t és a virtuális ISA-t is lekoppintaná. Amit persze nem tehet meg. (Csak ha belép a HSA Foundationbe és leszurkolja az árát.)
"QPI: mondjuk nezzuk meg, milyen piaci penetraciot ert el az egyik mára, es a masik."
Egyrészt az nem a QPI érdeme. Másrészt a QPI csak LGA2011 és Xeon vonalon is csak egyes szegmensekben található meg, így nem vagyok róla meggyőződve, hogy a millió számra eladott {minden, ami nem APU} nem veri eladásokban. Harmadrészt a QPI egyszerűbb, mint a HT.
"Sajnos a technologiai innovacio vegso ertekmeroje az eladasi darabszam ill. a realizalt profit. Ott pedig az Intel vs. AMD osszehasonlitast szinte sosem az utobbi nyeri."
Szerintem meg nem a pénz a végső értékmérő...
"A dGPU-kat egyebkent sem kellene direktben egy CPU-hoz hasonlitani, teljesen mas teszta"
Csak egy részegységről volt szó.
"Szoval SZVSZ boven eleg lenne a Skylake-nal, ha hoznak mondjuk a Trinity iGPU teljesitmenyet egy HSA-szeru, MIC vagy nem MIC alapu iGPU-val."
Kommersz PC vonalon valószínű így van (elég baj az), más szegmensekben nem feltétlenül.
(#13046) Abu85: Huh, hát ezt próbálják meg processzel ellensúlyozni...! Még a 14nm is kevés hozzá.
[ Szerkesztve ]
-

stratova
veterán
Én például éppen ebbe kezdek belefáradni. Nagyítóval kell keresni az igazán ütős AMD-s gépeket.
Amikor egyik nem notebookos topikban a régebbi generációk alapján beskatulyázott "AMD melegszik forró vacak, notiban inkább Intelt" felütésű hozzászólásra belinkeltem a Probook B-t, az volt a meglepetés a kedves fórumtárs számára, hogy ilyen gép egyáltalán létezik AMD-vel. Bár ez nem újdonság, Phenom II P650 (2 mag 2600 MHz, 45 nm, 25 W TDP) sem árasztotta el a piacot [azt is tán csak HP szerelte a gépeibe].
Igazán költhetnének az OEM partnerkapcsolatok ápolására, mert jó olvasni, hogy ilyen és amolyan fejlesztés és APU jött ki AMD-nél csak épp megvásárolni nem lehet Európa szerte a legütősebbeket. Erre a hazai forgalmazók csak rátesznek egy lapáttal
A HP meg Kaveri megjelenése előtt csak azért is (szvsz) elszúrja az új Elitebook/Probook szériát, de ne legyen igazam.
Ami engem kicsit meglepett egyik korábbi hozzászólásodban, hogy AMD a igény szerint bármikor integrálhat még több (>8) CU-t az APU-ba. Az odáig rendben van, hogy 4 Steamroller mag az asztalinál megszokott órajelen hozza 8 Jaguar teljesítményét, de nekem ez kissé hmm.. meredek. Mi lehet itt az a felső küszöb amit 4 Steamroller mag még kiszolgál, a PS4 18 CU-ja?
Esetleg arra lenne jó, hogy (GP)GPU oldalon megtartsa a teljesítménykülönbséget Boardwellhez képest (amit pletykák szerint nem is hoz asztali vonalra Intel).Említetted a az energiatakarékossági funkciók további javulását. Itt szerintem, azért is nehéz Intelt hajszolni, mert gyártástechnológiai lemaradásban vannak még AMD bérgyártói CPU/APU-k esetében.
2010 Intel 32 nm HKMG Bulk [Westmere - Nehalem-C]
2011 AMD 32 nm PD-SOI [Llano]
2012 Intel 22 nm tri-gate Bulk [Ivy Bridge]
2013-2014 AMD 28 nm HKMG Bulk [Kabini, Temash - Kaveri]
2014 Intel 14 nm tri-gate Bulk [Boardwell]Persze ezek mellett egyéb megoldásokkal is javította mindkét gyártó a telj/fogy. arányt, de jó lenne Carizzoval meglépni a 20nm FDSOI-t. GloFo-val kapcsolatos cikkekből ill. saját oldaluk alapján úgy vettem ki a 14nm-XM inkább a mobil SoC megoldásokhoz készül.
[ Szerkesztve ]
-
Fiery
veterán
"Szinte? Csak az egyik legfőbb összetevőt hagytad ki, a HSAIL-t és a hozzá tartozó virtuális ISA-t, amik biztosítják, hogy ugyanaz a lefordított bytecode más gyártók megfelelő termékein is futhat, mégpedig a rendszer kidolgozása által viszonylag optimálisan."
Mar leirtam, hogy ha valaki hazon belul akarja megoldani a HSA-t, akkor nem kell neki HSAIL, hiszen csak sajat maganak fejleszti a dolgokat. Hasznalhatja az Intel vagy barki mas a sajat meglevo IL-jet.
"He? Már a fél világ átvette a HSA-t, tucatnyi gyártó termékei készülnek hozzá/vele."
Az Intel (es az nVIDIA sem, mellesleg) akkor se az a fajta, aki atveszi mas megoldasait. Inkabb csinal sajatot, me'g ha az nagyon hasonlit is egy meglevo megoldasra.
"Az sem biztos, hogy az Intel HW-re fejlesztett OpenCL kód jól futna máshol és fordítva. Bár ahogy az Intelt ismerem, éppen erre építenének. Ami viszont visszafelé is elsülhet."
A HSA-nak pont az a lenyege, hogy azon a hardveren es ugy fut az OpenCL/Java/akarmilyen kod, amelyiken a legjobb, amelyiken optimalis. Ha a HSA-t koppintod, akkor ezt a hozzaallast is koppinthatod. Plusz, mar az OpenCL 1.x is ad lehetoseget gyartoi makrokra es egyeb optimalizacios megoldasokra, az OpenCL 2.0 / HSA is ugyanigy ad majd lehetoseget ilyenekre.
"Hasonló a helyzet, az Intel megint utólag próbálna másokra erőltetni egy hasonló, de mégis más megoldást."
Oket hibaztatod? Ha eddig szinte mindig bejott, miert kellene valtoztatniuk a viselkedesukon/hozzaallasukon?
"Akkor nem kellene új fordítót írnia, ha a HSAIL-t és a virtuális ISA-t is lekoppintaná. Amit persze nem tehet meg. (Csak ha belép a HSA Foundationbe és leszurkolja az árát.)"
Azt irtad, progamozol. Ha tenyleg igy van, akkor nem ertem, miert nem erted meg, hogy az OpenCL adott, azt nem is kell masolni, teljesen nyilt. A cucc masik vege meg az a driver ami kommunikal az iGPU-val es atadja a szamitasi feladatokat. Ha nem nyilt rendszert epitesz (ami a HSA), hanem egy HSA-hoz hasonlo, de zart rendszert, akkor **rvara mindegy, hogy a 2 veg kozott mi van, milyen koztes retegek, nyelvek vannak. Senkinek semmi koze hozza. Az Intel felugyeli az egeszet, elejetol a vegeig, kiveve persze az OpenCL-t. Az OpenCL viszont adott. A programozo dolga meg az, hogy OpenCL nyelven irjon egy, az SVM lehetosegeit kiaknazo progit, ami aztan ugyanugy fut HSA-n es az Intel-fele "HSA"-n is. A virtualis ISA (IL) eddig is el volt rejtve minden gyartonal, mert hazon belul ment az OpenCL-kod --> IL --> iGPU gepi kod forditas. Ha hazon belul maradsz, maradhatsz ugyanezen felallasnal, csak hozzapakolod a meglevo OpenCL megoldasodhoz az SVM tamogatast, meg levalasztod a video driverrol az egesz cuccot. De ez utobbi nem OpenCL-specifikus problema, csak a gyorsabb kernel launch miatt lenyeges.
"Szerintem meg nem a pénz a végső értékmérő"
Ha piaci versenyben kuzdo technologiai cegrol van szo, akkor a penz biztositja azt, hogy a kovetkezo technologiai innovaciora is legyen R&D. Nem minden a penzrol szol, de a mernokoknek, tudosoknak valamibol fizetest kell adni... Plusz anyagkoltseg, folyamatos beruhazasok, ami egy vertikalisan integralt CPU-gyartonal brutalis penz megint csak.
[ Szerkesztve ]
-
Fiery
veterán
válasz
 stratova
#13055
üzenetére
stratova
#13055
üzenetére
A plusz CPU CU-k integralasanak csupan 3 akadalya van:
1) Nagyon megugrik a CPU-resz TDP-je. Amit lehetne alacsonyabb orajellel ellensulyozni, de nem eri meg, mert:
2) Nem igazan skalazodik 4 mag felett a teljesitmeny, mert keves szoftver van, ami rendesen kihasznalja a 6 vagy tobb magot.
3) De a legnagyobb "baj" az, hogy az AMD a rendelkezesre allo tranzisztor, die area es TDP keretet inkabb az iGPU-ba tolja be, hogy tudja tartani a biztos tavolsagot az Intel-fele megoldasoktol (teljesitmenyben). Meg persze az egesz HSA arrol szol, hogy amit lehet, azt dobjon at a programozo az iGPU-ra, dolgozzon az a CPU-magok helyett. Ha a HSA berobban, es gombamodra szaporodni kezdenek az iGPU-t kihasznalo szoftverek, akkor me'g az sem elkepzelhetetlen, hogy egy 2 magos, de me'g erosebb iGPU-val megaldott AMD APU lesz a legtutibb valasztas.
[ Szerkesztve ]
-
Abu85
HÁZIGAZDA
A vISA a legfontosabb komponens, mert az biztosítja a kompatibilitást házon belül is. A HSAIL nem egyedi dolog. Minden cégnek van ilyen rendszere. Az NV-ét PTX-nek, az AMD-ét AMDIL-nek hívják stb. A HSAIL annyiban más mint ezek, hogy nem csak házon belül támogatott, hanem számos más gyártó által. Ez nem egy extra, hanem egy aktuális komponens lecserélése, amit ma is használ mindegyik OpenCL alkalmazás például. Az Intelnek is van ilyen, de az nagyon kimondhatatlan nevű, de a lényeg, hogy van.
A HSAIL annyi, hogy akik a HSA-t támogatják a saját vISA-jukat erre cserélik. Ezzel biztosítva egy igen alacsony szintű kompatibilitási réteget.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Fiery
veterán
En is azt irtam, amit Te irsz

"A HSAIL annyi, hogy akik a HSA-t támogatják a saját vISA-jukat erre cserélik. Ezzel biztosítva egy igen alacsony szintű kompatibilitási réteget."
Persze, ez egy tok jo dolog, ha masokkal egyutt akarsz mukodni. De ha lekoppintod a HSA-t, akkor maradhatsz a sajat IL-ednel, nem kell vacakolni ujjal.
[ Szerkesztve ]
-
Abu85
HÁZIGAZDA
válasz
stratova
#13055
üzenetére
A konzolokat semmilyen formában nem érdemes belekeverni a PC-s harcba. Ezeknek a gépeknek a dizájnja alapvetően játékokhoz van igazítva. A CPU és IGP aránya nem olyan kérdés, hogy van egy ideális szint. A konzolok azért ilyenek, mert a fejlesztők többsége nyolc pici magot kért, mert a szintén igényelt egységes virtuális memória mellett, amit eddig a proci elvégzett azt részben megcsináltatják az IGP-n. De ez speciális igény, és csak a játékfejlesztők igénye. Egy PC-n azonban nem csak játszol, tehát nem tudsz annyira ezekre az igényekre koncentrálni. Ezen a szinten a tervezés úgy zajlik, hogy mi az az ideális arány, ami a lehető legjobban lefedi a különböző fejlesztői igényeket. És igen az eltérő igények miatt nem lesz mindenki boldog, de ez a PC.
Fiery: Félreértettem. Sry.

[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
dezz
nagyúr
"Mar leirtam, hogy ha valaki hazon belul akarja megoldani a HSA-t"
Akkor most olvasd el annak a mondatnak a második felét is, amire válaszoltál...
"Az Intel (es az nVIDIA sem, mellesleg) akkor se az a fajta, aki atveszi mas megoldasait. Inkabb csinal sajatot, me'g ha az nagyon hasonlit is egy meglevo megoldasra."
Ez a legutálatosabb benne (NV azért nem viszi ennyire túlzásba), hogy folytonosan vérre menő harcot vív az egész világ ellen, minden téren. Mintha nem az emberiség része lenne, hanem egy idegen faj. Kooperációra képtelen.
"A HSA-nak pont az a lenyege [...]"
Ezt tudjuk. De ha az Intel megoldása csak hasonlít rá, de eltér tőle, akkor nem feltétlen biztosítható, hogy ugyanaz a kód ugyanolyan jól fut majd mindkét rendszeren.
"Ha eddig szinte mindig bejott, miert kellene valtoztatniuk a viselkedesukon/hozzaallasukon?"
Remélem, tanultak az AMD64 esetéből. És nem azt, hogy még alantasabb módon próbálják megfúrni az "ellenség" kezdeményezését.
"Azt irtad, progamozol. Ha tenyleg igy van"
Ha tudni akarod, 28 éve programozom, az idő nagy részében ASM-ben (többféle proci, de az x86 nincs köztük), kisebb részében C-ben. Referenciáimmal nem hozakodnék itt elő. De megkérnélek, hogy ne vond kétségbe a szavamat. Továbbá újfent megkérlek, hogy ne nézz hülyének. Ha a másik valamit nem ért, vagy úgy tűnik, hogy nem ért, annak félreértés is lehet a oka.
"akkor nem ertem, miert nem erted meg, hogy az OpenCL adott, azt nem is kell masolni, teljesen nyilt."
Ki beszélt az OpenCL másolásáról?
"A cucc masik vege meg az a driver ami kommunikal az iGPU-val es atadja a szamitasi feladatokat. Ha nem nyilt rendszert epitesz (ami a HSA), hanem egy HSA-hoz hasonlo, de zart rendszert, akkor **rvara mindegy, hogy a 2 veg kozott mi van, milyen koztes retegek, nyelvek vannak. Senkinek semmi koze hozza."
Ezt írtad korábban: "Viszont ha az Intel lekkopintja a HSA-t, akkor neki nem kell uj forditot irnia, hanem csak a drivereket: joval kisebb melo." - Itt nem arra gondoltál, hogy a HSAIL-hez ír drivert és arra való fordítást meghagyja másoknak (AMD vagy aki a HSA Foudation keretein belül ezzel kíván foglalkozni)?
Vagy, ha arra gondoltál, hogy a saját fordítóját használja tovább és csak a saját meglévő IL-jéhez készít új drivert: kötve hiszem, hogy ez az IL eleve, már jó előre a HSA új megoldásainak megfelelő lett volna... A végén még kitalálod, hogy az AMD másolta a HSAIL-lel és a vISA-val az Intel titkos IL-jét... Ne bohóckodjunk már...
A valóság talaján maradva, ha az Intel csak egy HSA szerű architektúrát akar kialakítani, akkor bizony (az új HW-ek mellett) új IL rétegre lesz szüksége (a régi ugyanis nem coherent+unified memory aware, nem támogatja a korábban nem létező fast context switchet és az újfajta queue rendszert) és az OpenCL fordítóját is ennek megfelelően, jelentősen módosítania kell. Azaz, koránt csak csak új drivert kell írnia.
"Ha piaci versenyben kuzdo technologiai cegrol van szo, akkor a penz biztositja azt, hogy a kovetkezo technologiai innovaciora is legyen R&D."
Ha képesek lennének megfelelő szintű kooperációra, nem kellene mindent saját maguknak (újra) kifejleszteni, ezzel jelentősen csökkenhetne az R&D budget, máris nem kellene vérre menő kűzdelmet folytatniuk az egész világ ellen, hogy azt előteremtsék.
[ Szerkesztve ]
-
Fiery
veterán
"Ezt tudjuk. De ha az Intel megoldása csak hasonlít rá, de eltér tőle, akkor nem feltétlen biztosítható, hogy ugyanaz a kód ugyanolyan jól fut majd mindkét rendszeren."
Ezt sosem tudod 100%-osan biztositani, hiszen az IL/HSAIL --> GPU gepi kod forditas mindig is egy valtozo lesz a kepletben, HSA-n belul is. A HSA-nak es a HSAIL-nek annyi elonye van, hogy legalabb a HSAIL-ig lemenve -- elvileg -- egyforma minden gyartonal a kod. Jelenleg meg ugye csak a legfelso szint (OpenCL kod) fix, onnantol lefele az IL is valtozo (gyartonkent mas a fordito), azutan meg a gepi kodra forditas plane valtozo.
Elnezest, ha felreertettuk egymast. Nekem csak kicsit furcsa, hogy nem erted meg, amit irok, pedig tobbszor, tobbfelekeppen leirtam. Talan meg kene probalnom osszeszedni elejetol a vegeig, es ugy leirni, mert lehet hogy a mondanivalom szettoredezik a sok postban, es nehez kovetni
Errol en tehetek, sorry. Egy pizza+sor/kola mellett egyszerubb dolgom lenne 
"Itt nem arra gondoltál, hogy a HSAIL-hez ír drivert és arra való fordítást meghagyja másoknak (AMD vagy aki a HSA Foudation keretein belül ezzel kíván foglalkozni)?"
Nem, te jo eg, me'g csak az kene
Pont ezzel szivatja magat a szerencsetlen AMD! Az AMD-nek vegre volt egy hasznalhato, egesz jo minosegu OpenCL --> IL (sajat, AMD-specifikus IL) forditoja, de a HSAIL miatt kenytelen azt ugy ahogy van kukazni, es nullarol irni egy OpenCL --> HSAIL (plusz mellesleg egy Java --> HSAIL) forditot Csupan emiatt csuszik a HSA konkret AMD implementacioja, ezert nem tart sehol a Kaveri szoftver stack Ha hasznalni tudná a regi, jol bevalt OpenCL --> IL forditot, mar kesz lenne a HSA implementacioval az AMD.Az Intel dehogy fog alkalmazkodni, miert tenné? Fogja a meglevo OpenCL --> IL (sajat, Intel-specifikus IL) forditojat, nem kell semmi kulonoset csinalni vele, hiszen az OpenCL 2.0 nyelvi szinten nem valtoztat semmi alapvetot. Egyszeruen ir egy uj drivert meg csinal egy megosztott memorias vasat a cucc ala (tudom, tudom, az nem olyan egyszeru...), es kesz a sajat "HSA"-ja. Ez a baj, ez egy komoly veszely lehet, en ettol feltem az AMD-t. Kitalaltak valami erdekeset, de tul konnyen koppinthato.
"kötve hiszem, hogy ez az IL eleve, már jó előre a HSA új megoldásainak megfelelő lett volna"
Az IL-t is lehet fejleszteni, fel lehet kesziteni a jovo kihivasaira. Plane mivel az AMD mar par eve lovagol az SVM teman, lepesrol lepesre halad elore, kozben az Intel siman megcsinalhatja/megcsinalhatta fu alatt, hogy az IL-jet felkesziti az SVM-re -- plane ha mondjuk menet kozben a vasat is keszitik hozza. _Ha_ keszitik.
"A végén még kitalálod, hogy az AMD másolta a HSAIL-lel és a vISA-val az Intel titkos IL-jét... Ne bohóckodjunk már..."
Kerlek ne adj a szamba olyat, amit soha nem mondanek. Az IL egyebkent sem feltetlenul annyira titkos
"új IL rétegre lesz szüksége (a régi ugyanis nem coherent+unified memory aware, nem támogatja a korábban nem létező fast context switchet és az újfajta queue rendszert)"
Ezt honnan tudod? Van konkret informaciod erre vonatkozoan? Es kulonben is, mi koze az IL-nek a context switch-hez meg a queue-hoz? Lehet, hogy en vagyok tajekozatlan, ebben az esetben kerlek kuldj nehany linket, ahol tajekozodhatok az IL + context switch + queuing relacioban.
"és az OpenCL fordítóját is ennek megfelelően, jelentősen módosítania kell"
Egyszerubb modositani, mint ujat irni (lasd AMD). Es nem kell modositani, hiszen a nyelv nem valtozik az SVM bevezetesevel. Az AMD-nek kell ujat irnia, de az a HSAIL miatt van, maganak csinalta a melot az AMD.
"Kooperációra képtelen"
+
"Ha képesek lennének megfelelő szintű kooperációra, nem kellene mindent saját maguknak (újra) kifejleszteni, ezzel jelentősen csökkenhetne az R&D budget, máris nem kellene vérre menő kűzdelmet folytatniuk az egész világ ellen, hogy azt előteremtsék."Tovabbra is azt mondom, hogy eddig mukodott naluk a dolog, minek maskepp csinalni... Majd ha eljutnak oda, hogy alig lesz profit vagy tartosan vesztesegbe fordulnak, akkor lehet, hogy atertekelik az eddigi hozzaallasukat. Addig aligha. Ne erts felre, szerintem is jobb lenne, ha maskepp csinalnak a dolgokat, de nem latok ra eselyt sajnos.
-
Abu85
HÁZIGAZDA
Mondhatjuk így is, de a HSAIL-re direkten kódot írni olyan mint assembly-ben programozni. Nyilván nem kizárt, hogy lesz olyan, aki ezt az utat választja, de a fejlesztők többsége valami magasabb szintű nyelvet használ majd.
(#13063) Fiery: Azért az OCL2.0 nem csak egy shared virtual memory és kész. Azért a dinamikus parallelizmus elég komoly queueing modellt igényel. Ezt eddig csak az AMD oldotta meg skálázható formában. Elsősorban azért, mert baromi nehéz. Az NVIDIA-nak van még ilyen parancsprocesszora, de nem skálázzák, hanem minden lapkába áttervezik. Az Intel még nem beszélt róla, hogy milyen queueing modellt csinálnak, ami aggasztó, mert az NV-nek és az AMD-nek már működik a gyakorlatban.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Fiery
veterán
"Azért az OCL2.0 nem csak egy shared virtual memory és kész."
Oke, de en feature szinten feszegetem azt a kerdest, hogy mennyire koppinthato a HSA. Ha lemasolod a HSA-t, de kicsit lassabb, kevesbe skalazhato lesz, az me'g mindig jobb, kivanatosabb lehet vegeredmenyben, mint a mostani OpenCL 1.x-es megoldasok. Ugy is mondhatnam, egy masolt HSA teljesitmenyben a mostani OpenCL-es programok es az "igazi" HSA-s megoldasok koze eshet.
-
dezz
nagyúr
Persze, hogy nem, de az sem mindegy, mennyire lehet megközelíteni a 100%-ot. A HSA a HW-rel szemben is meghatároz egy sor követelményt.
"Talan meg kene probalnom osszeszedni elejetol a vegeig"
Szükségtelen, csak egy ponton volt félreértés.
"Nem, te jo eg, me'g csak az kene"
Miért? Akkor másokra hárulna az OpenCL, Java, stb. fordítók elkészítése, az Intelnek - a többi gyártóhoz hasonlóan - csak a HSA Finalizert kellene elkészítenie a HW-eihez...
"Fogja a meglevo OpenCL --> IL (sajat, Intel-specifikus IL) forditojat, nem kell semmi kulonoset csinalni vele, hiszen az OpenCL 2.0 nyelvi szinten nem valtoztat semmi alapvetot."
1. Már ha jelenleg van bármilyen IL-e az Intelnek, nem pedig csak valami sokkal egyszerűbb low-level GPU driver. (Az AMD jelenleg elvileg közvetlenül GPU ISA-ra fordít OpenCL-ről.)
2. Attól, hogy OpenCL szinten nem sokat változik a szintaxis, egyebek, az IL szintjén jelentős változások lehetnek.
3. Nem hiszem el, hogy csak úgy sitty-sutty implementálni tudnák az OpenCL 2.0-át, mindezt HSA szerű alapokon. Ha ez csak így menne, már beelőzték volna az AMD-t."Ezt honnan tudod? Van konkret informaciod erre vonatkozoan?"
Csak a józan ész.
"Es kulonben is, mi koze az IL-nek a context switch-hez meg a queue-hoz?"
Ez erősen attól függ, hogyan vannak és lesznek ezek alacsony szinten megvalósítva. CPU-knál is jöttek be új utasítások pl. gyorsabb context switchre, stb. Még összetettebb dolog lehet az SVM, cache koherenciával kapcsolatos esetleges műveletek, stb.
"Egyszerubb modositani, mint ujat irni (lasd AMD)."
Honnan tudod, hogy az Intelnek nem kell? (Lásd fent.) Vagy hogy az AMD-nek milyen szinten kell átírnia? Jelenleg az sem biztos, hogy volt valamilyen IL. (Lásd fent.) Ha volt, akkor kétfelé kell bontani (OpenCL->IL, IL->GPU ISA), az IL szintaxisát módosítni, a meglévők mellé új funkciókat beilleszteni. A HSAIL-t alapvetően az AMD dolgozta ki, nyilván építettek a meglévő IL-re is, ha volt olyan.
A dinoszauruszok is sokáig uralták a Földet, de aztán változások álltak be, amihez nem tudtak alkalmazkodni (mert megszokták, hogy addig nem kellett semmihez), szépen ki is haltak. Az x86 sokat veszített a befolyásából, és elég kicsi az esély, hogy ezt az egészet az Intel az ellenkezőjére fordítja.
[ Szerkesztve ]
-
#13068
 FireKeeper
nagyúr
batt
#13067
FireKeeper
nagyúr
batt
#13067
FireKeeper
nagyúr
nem vagy szemtelen, de ez még mindig nem az a topic. tuningos, BIOS-os, vagy általános kérdéses topikokba írj. ott nagyobb eséllyel kapsz választ.
steam, GOG, uPlay: @petermadach || HotS: PeterMadach#2675 || Xperia 10 V || Ultrawide & SFF masterrace || Unofficial and unpaid VXE R1 shill
-

lee56
őstag
Szerintem iGPU CU-ra gondolt, tehát a radeon core tömbökre, amikből a PS4-ben 18 lesz elvileg.
Az a hozzászólás viszont nem tudom melyik lehetett amire utalt, de szerintem hosszútávon beszélhettél erről, vagyis hogy majd be tudnak építeni többet is, majd a Carizzo-ban és később. Ezért jó a moduláris felépítés, könnyebben tudnak újratervezni, ha esetleg még nagyobb die area kell az iGPU-nak. Amúgy a Jaguar magok (8) azért annyira nem erősek, nem? Desktop Kaveri 4 magja simán nagyobb teljesítményt fog adni, más kérdés hogy bizonyára nagyobb fogyasztás is fog járni e bónusz mellé.És itt nem is értem amit kérdezett strati ;
"Mi lehet itt az a felső küszöb amit 4 Steamroller mag még kiszolgál, a PS4 18 CU-ja?"
Ez PC-n a majd (lentebb) említett programozóktól függ igazán, meg a szoftverkörnyezettől amit az APU-k alá görgetnek a gyártók; lásd mantle. Konzolon a relative kisebb Jaguárok teljesítménye sem jelent gondot, mivel nem kell pl. a DirektX rétegeivel megküzdeni. És ugye azért van az erős iGP benne hogy azt piszkálják inkább, tehát ha már amúgyis ez volt a (játék)fejlesztők kívánsága, akkor essenek is neki és használják azt ki minél jobban. Tehát mire desktopon a PS4 szintjén fognak járni iGP-ben,már talán lesz elég tapasztalat is a témában.Na igen, amit írsz a végén az lenne a nonplusz ultra, a fusion utópia megvalósulása, szerinted mégis hány év telik el mire ez kökemény reality nem lesz, gondolva főként a globális elterjedés és a szoftverprogramozók felnövéséhez a feladathoz?
(#13055) stratova : Igen ez tényleg érdekes, állítólag kellően jó PR-al még a sz@rt is el lehet adni, de furcsamód - ahogy Fiery is írta - AMD-nek ez néha akkor sem ment, amikor tényleg minden tekintetben jobb cuccot árult mint a konkurencia. Bár ha a sok kék szemüveges bolti eladóra, meg a kékek jópár aljas húzására gondolok, akkor már azért érthetőbb hogy nem olyan egyszerű versenyezni velük.
Az meg hogy gyártósorok is néha megszivatják őket, és nem gördül le elég termék hogy elárasszák a világot, csak a hab a tortán. No Comment
-
#13070
FireKeeper
nagyúr
lee56
#13069
FireKeeper
nagyúr
nyilván rajtam enyhe-piros szemüveg van, de szerintem a sajtó telehányása, vagy a gyártók kínálatának manipulálása (laptopok, OEM gépek) közül az utóbbi a gusztustalanabb. nyilván kezd irritáló lenni ez a PR-os dolog is, de ezt könnyebb ignorálni, mint az igazságtalan termékkínálatot.
nem szeretnék flame-et generálni, ha valaki úgy látja ez mégis sikerült, töröltesse modikkal, meg amúgy is ír ide egy-pár házigazda

steam, GOG, uPlay: @petermadach || HotS: PeterMadach#2675 || Xperia 10 V || Ultrawide & SFF masterrace || Unofficial and unpaid VXE R1 shill
-
stratova
veterán
Akkor én félreértettem a korábbi bejegyzésedet, ezért is lepődhettem meg rajta.
Max. 8-at, igy van Persze ha lesz ra igeny, akkor barmikor tud az AMD 8-nal tobb GCN2 CU-t integrálni a Kaveri 2 CPU-modulja mellé, csak annak sajnos a TDP-keret látná kárát.Ugyanis én GPU CU-ként értelmeztem (ahogy lee56 is értelmezte a hsz-emet). Azért is hasonlítottam a legnagyobb teljesítményű konzol APU-hoz - Abu válaszára reagálva - mert korábbi híradások szerint ott a GPU CU-k nem csak grafikai számításokat végeznek. Ebből gondoltam arra, mi a legnagyobb GPU CU szám, amit a 2 CPU modul kiszolgálhat PC-n GPGPU-s felhasználás esetén.
AMD már HD 7000 megjelenésekor azt reklámozta, hogy az GCN mennyivel alkalmasabb ilyen területre a korábbi megoldásnál:
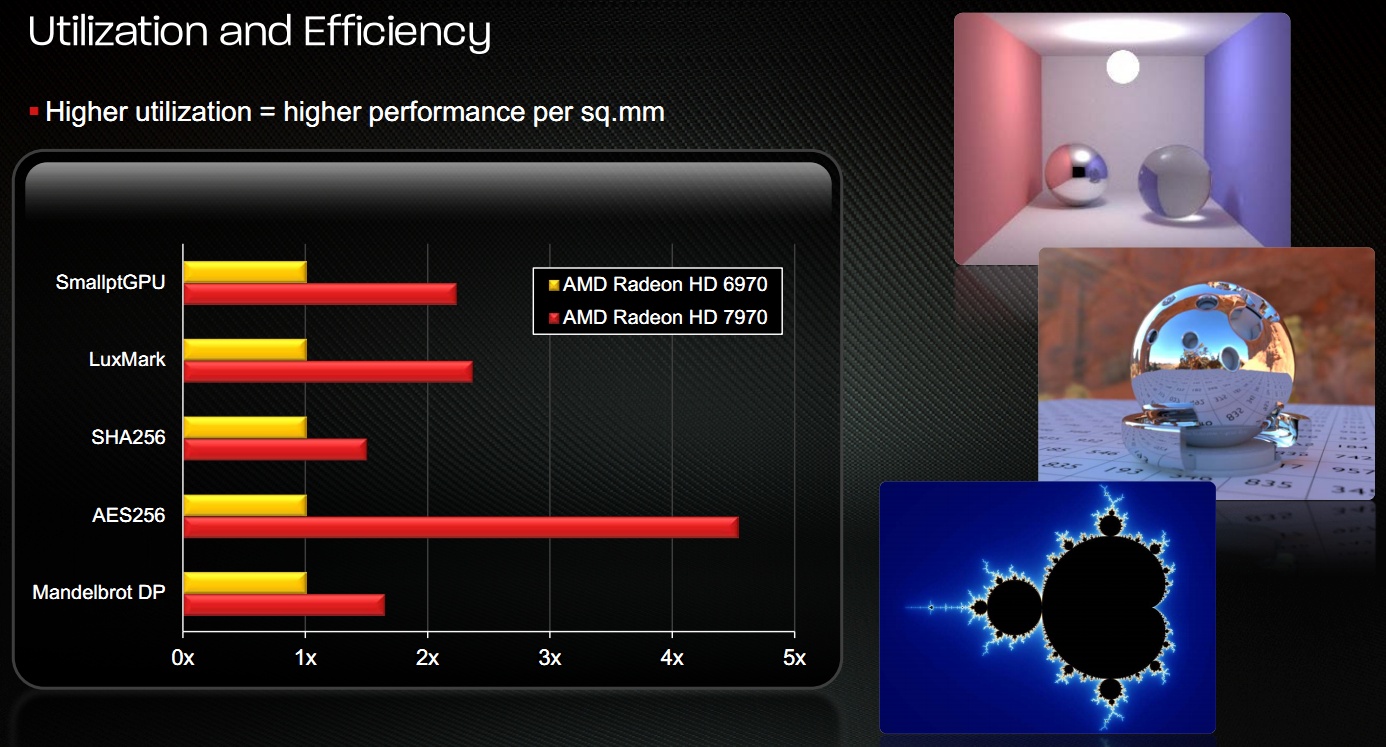
-
Fiery
veterán
"Miért? Akkor másokra hárulna az OpenCL, Java, stb. fordítók elkészítése, az Intelnek - a többi gyártóhoz hasonlóan - csak a HSA Finalizert kellene elkészítenie a HW-eihez"
Mert akkor csatlakozniuk kene a HSA Foundation-hoz... Azt meg nem akarjak. Ha meg mar nem csatlakoznak, akkor miert eroltessek magukra a HSAIL-t? Szuksegtelen.
"Már ha jelenleg van bármilyen IL-e az Intelnek"
Van nekik. Naluk is 2 lepcsos a forditas OpenCL 1.x-nel, azaz elso lepcso: OpenCL --> Intel IL, masodik lepcso: Intel IL --> iGPU gepi kod.
"Csak a józan ész"
A jozan esz azt diktalja, hogy az IL szintjen ne kelljen foglalkozni az utemezessel. Az x86 sem arrol szol, hogy mikepp utemezed a kodot, hogyan futtatod le (in-order, pipelined in-order vagy out-of-order). A nyelv szintjen nem kell ezekkel foglalkozni, plane ha queuing megoldasrol van szo.
"Ha volt, akkor kétfelé kell bontani (OpenCL->IL, IL->GPU ISA), az IL szintaxisát módosítni, a meglévők mellé új funkciókat beilleszteni."
Nem kell az IL-t modositani. De ha kell is, akkor sem akkora kaland modositani, mint atallni a forditokkal (mert ugye 2 forditorol beszelunk) egy teljesen uj IL-re.
"A HSAIL-t alapvetően az AMD dolgozta ki, nyilván építettek a meglévő IL-re is, ha volt olyan."
Van nekik is, ezt Abu is leirta fentebb. Mindharom gyarto ugyanazt a felepitest hasznalja, amit anno az nVIDIA kitalalt (ha o talalta ki). Nem tudom, az AMDIL es a HSAIL kozott milyen relacio van, de az biztos, hogy a jelenlegi OpenCL 2.0 --> HSAIL --> Kaveri iGPU gepi kod fordito megoldas teljesitmenye eleg messze van az OpenCL 1.2 --> AMDIL --> Kaveri iGPU gepi kod forditoetol
Ergo, vagy az AMD benazik, vagy a HSAIL teljesen mas mint az AMDIL. A logikai es az eddigi tapasztalatok azt diktaljak, hogy az utobbirol van szo."A dinoszauruszok is sokáig uralták a Földet, de aztán változások álltak be, amihez nem tudtak alkalmazkodni (mert megszokták, hogy addig nem kellett semmihez), szépen ki is haltak. Az x86 sokat veszített a befolyásából, és elég kicsi az esély, hogy ezt az egészet az Intel az ellenkezőjére fordítja."
2006-ban azt se gondolta volna senki, hogy a Nokiat par ev alatt el lehet soporni
 Az Intel pedig mar azert ott van a "szeren" 30 eve (akarcsak az AMD, mellesleg), az x86 pedig eddig bizonyitott. A Silvermont baromi jol sikerult (akarcsak a Jaguar). 10 colos full passziv huteses slim profile tablet = 12-14 ora egy feltoltessel, 4 magos Bay Trail-T procival -- ezt is ki gondolta volna 2-3 eve? Hidd el, az x86-ban me'g nagyon sok minden van. A MIC talan nem valtja meg a vilagot, de rengeteg otlet van me'g a fiokok mélyén ill. a mernokok fejeben. Nekem is lennenek naiv otleteim, pl. hogy mikepp lehetne kivaltani az iGPU-t CPU-val, de majd az Intel _talan_ megcsinalja, amig az AMD a HSA-t nyomatja. Izgalmas lesz a kovetkezo 2 ev.
Az Intel pedig mar azert ott van a "szeren" 30 eve (akarcsak az AMD, mellesleg), az x86 pedig eddig bizonyitott. A Silvermont baromi jol sikerult (akarcsak a Jaguar). 10 colos full passziv huteses slim profile tablet = 12-14 ora egy feltoltessel, 4 magos Bay Trail-T procival -- ezt is ki gondolta volna 2-3 eve? Hidd el, az x86-ban me'g nagyon sok minden van. A MIC talan nem valtja meg a vilagot, de rengeteg otlet van me'g a fiokok mélyén ill. a mernokok fejeben. Nekem is lennenek naiv otleteim, pl. hogy mikepp lehetne kivaltani az iGPU-t CPU-val, de majd az Intel _talan_ megcsinalja, amig az AMD a HSA-t nyomatja. Izgalmas lesz a kovetkezo 2 ev. -
Fiery
veterán
"Amúgy a Jaguar magok (8) azért annyira nem erősek, nem? Desktop Kaveri 4 magja simán nagyobb teljesítményt fog adni, más kérdés hogy bizonyára nagyobb fogyasztás is fog járni e bónusz mellé."
Nehez direktben egymashoz hasonlitani a Jaguar es a Piledriver/Steamroller (Trinity/Richland, Kaveri) magokat, foleg az utobbiak modulos felepitese miatt. De ha mindenkepp egymashoz hasonlitod oket, mondjuk core-for-core, clock-for-clock alapon, akkor eleg sz*rul jon ki a Piledriver/Steamroller
A Jaguar ugyanis egy jobb, hatekonyabb, gyorsabb architektura osszessegeben, es ha megfeleloen fel tudjak skalazni orajelben, akkor siman az lehet a jovoje az AMD mainstream desktop/mobil platformjanak is. A Kaverit (a CPU-reszt) elnezve, en amondo vagyok, a Carrizo lehet az utolso a Family 15h (Bulldozer, Piledriver, Steamroller, Excavator) vonalon, es utana a kovetkezo mainstream APU mar inkabb a Family 16h (Jaguar) architekturara epitkezhet. Hasonloan, mint amikor a Pentium M-bol lett vegul a Core 2 (Conroe) az Intelnel, a P4 vonalat pedig kukaztak. De ez csak egy sejtes a reszemrol."szerinted mégis hány év telik el mire ez kökemény reality nem lesz, gondolva főként a globális elterjedés és a szoftverprogramozók felnövéséhez a feladathoz?"
Ha atall az AMD minden vonalon a Jaguarra, akkor 4 Jaguar mag teljesen jo lehet egy eros iGPU mellé. A 2 magot / 1 modult a jelenlegi architektura eseten ertettem, Jaguarbol "elfer" 4 mag is.
-
Fiery
veterán
válasz
stratova
#13071
üzenetére
"Ebből gondoltam arra, mi a legnagyobb GPU CU szám, amit a 2 CPU modul kiszolgálhat PC-n GPGPU-s felhasználás esetén."
Ennek nincs igazandibol felso korlatja. Manapsag is, ha veszel egy OpenCL 1.x-et kihasznalo szoftvert, akkor tolhatsz ala 2 iGPU CU-t (Brazos), vagy egy brutal dGPU-t (Tahiti peldaul), sok-sok CU-val, es mindet meg tudja hajtani a CPU-d. Az megint mas kerdes, hogy milyen fajta szoftverre tervezed a vegeredmenyben eloallo APU-t, milyen felhasznalasra, mekkora TDP keretre, stb. Ha a HSA berobban, akkor az AMD fel fogja terkepezni, hogy milyen szoftverek hasznaljak ki a HSA-t, megbecsuli, hogy a kozeljovoben elkeszulo szoftverek milyen igenyekkel allnak elo, es az alapjan fogja pakolni be az iGPU CU-kat a CPU-magok kárára adott esetben.
[ Szerkesztve ]
-
-
Én konkrétan remélem, hogy így lesz.
Nekem az is jó, ha a Jaguarral rakják össze a GCN3-at, kihagyva az FPU-t, tulajdonképpen a lényeg, hogy minden területen legyen értelmes alternatívája az intel prociknak az AMD-től.
pl. nem tudom, hogy mivel lehetne maghajtani 2db, netán 4db 290X GPU-t.[ Szerkesztve ]
Eladó régi hardverek: https://hardverapro.hu/apro/sok_regi_kutyu/friss.html
-
#13078
 Mahrenburg
senior tag
Fiery
#13026
Mahrenburg
senior tag
Fiery
#13026
Mahrenburg
senior tag
Köszönöm!
Jól értem, hogy lehetne nagyobb (pl. 3 GHz körüli) órajelű Jaguar-változatot is kihozni (persze magasabb TDP-vel) ? És egy ilyen változat már elképzelhető, hogy "Intel-közeli" magonkénti teljesítményt nyújtana? (Ráadásul, ha jól sejtem, a kis lapkaméret okán még így is nagyon jó fogyasztási értékeket hozna.) Az is elképzelhető, hogy csak azért nem álltak át Jaguarra, mert a Carrizo már "készen van"? Az is eszembe ötlött, hogy (szintén a kis lapkaméretet alapul véve) lehetne 4 Jaguar-mag+GPU, s tisztán CPU, azaz 2x4 Jaguar-magos verzió is... (Persze lehet, hogy túlgondoltam/félreértettem valamit...
)"Egy fel nem használt Phenom II matrica olyan mint egy nap ami sosem kelt fel, egy múló szerelemről szóló dal amit sosem énekeltek, egy harcos szív amely sosem dobbanhatott..!" by Habugi
-
#13079
 letepem
aktív tag
Mahrenburg
#13078
letepem
aktív tag
Mahrenburg
#13078
letepem
aktív tag
válasz
 Mahrenburg
#13078
üzenetére
Mahrenburg
#13078
üzenetére
Alapvetően a Jaguár tervezése során a kis méret és alacsony fogyasztás volt a szempont így, ha jól olvastam, ~ 2 GHZig jól skálázodik a rendszer. Utána a töblet fesz + órajel négyzetes és lineáris fogyasztásnövekedésre gondolva, igen elszállhatnak azok a bizonyos wattok
.[ Szerkesztve ]
látok, hallok, érzek és gondolkodom.
-
válasz
 letepem
#13079
üzenetére
letepem
#13079
üzenetére
Eleinte a Pentium-M sem ment 1,5GHz-nél gyorsabban - ha jól csalnak az emlékeim.
Szerintem, ha tényleg ez a cél, akkor ezt meg fogják oldani.
Bár, ennek ellent mondd, hogy a Llano CPU-ja is jobb IPC értékkel bírt, mint a Bulldozer és leszármazottai, mégis kukázták. Igaz, az még kevevset sem fogyasztott, a Jaguar meg igen.
Szóval, ki tudja?[ Szerkesztve ]
Eladó régi hardverek: https://hardverapro.hu/apro/sok_regi_kutyu/friss.html
-
dezz
nagyúr
"Mert akkor csatlakozniuk kene a HSA Foundation-hoz... Azt meg nem akarjak."
Mert? Ennyire derogál nekik az, ami a világ más nagy elektronikai cégeinek nem?
"A jozan esz azt diktalja, hogy az IL szintjen ne kelljen foglalkozni az utemezessel. Az x86 sem arrol szol, hogy mikepp utemezed a kodot, hogyan futtatod le (in-order, pipelined in-order vagy out-of-order)."
Nem utasításütemezésről van szó, hanem a (rész)feladatok ütemezéséről.
"A nyelv szintjen nem kell ezekkel foglalkozni, plane ha queuing megoldasrol van szo."
Ehhez képest az AMD kifejlesztett v. implementált egy bizonyos Architected Queuing Language-et (AQL). [link]
De más okai is vannak az IL szükségszerű megváltoztatásának:
- Többféle magas szintű nyelv támogatása az OpenCL-en kívül (C++, Java, C++ AMP, .NET, stb.).
- Másféle, önállóbb queuing, AQL, user-mode dispatches to HW, dispatch API-k.
- Unified memória modell, közös pointerek a CPU-val.
- Cache koherens és nem koherens területek.
- Önálló context switch, preemtion.
- stb.Nem tudom, miért gondolod, hogy az Intelnek csak minimális változtatásokat kellene eszközölnie az IL-jén egy HSA-szerű rendszer, illetve az OpenCL 2.0 kiszolgálásához? Vagy hogy az AMD nem próbált annyit átemelni a HSAIL-be a korábbi IL-ből, amennyit lehetett? Vagy hogy a fentiek és pár egyéb dolog implementálása és kiszolgálása szinte semmiség (az Intelnek)?
(#13073): Ez azért furcsa, mert a Brazos/Jaguar az tulajdonképpen a K8/K10 lebutítása, sok tekintetben. Ebből fakad az is, hogy nem tudnak jelenleg még 2 GHz fölé sem igazán menni vele. Valószínűleg jelentős változtatásokra lenne/lesz szükség ahhoz, hogy ez megváltozzon.
[ Szerkesztve ]
-
#13083
Fiery
veterán
Mahrenburg
#13078
Fiery
veterán
válasz
Mahrenburg
#13078
üzenetére
A Carrizoval azert maradnak a jol bevalt Family 15h vonalon, mert azzal akarjak befejezni az elkezdett munkat (HSA). A Kaveri ugyan HSA-compliant hardver, de me'g nem teljes sebessegen megy, es me'g nincs benne 1-2 kiegeszito feature (pl. QoS). Ezeket me'g a Carrizoval megoldjak, es csak utana valtanak Jaguarra -- ha valtanak.
A Jaguar lehet, hogy "csak" cca. 3 GHz-ig skalazodik jelenleg, de kis modositasokkal mehet az feljebb is, csak legyen ra TDP-keret. Jelenleg a TDP-keret alacsony, de ha mas celokra is kell a Jaguar, kis faragassal mehetnek feljebb orajelben siman. A Banias, Dothan es Yonah sem olyan orajelekre lett tervezve, mint amit vegul a Conroe es utodai elertek. (Szerk.: kozben latom, ezt Bici is megirta) A valtas csak elhatarozas kerdese.
iGPU nelkuli, hagyomanyos CPU-t mar nem igazan fog az AMD piacra dobni. Legfeljebb mikroszerverekbe lenne ertelme, de oda meg inkabb ARM-ot kuld az AMD.
[ Szerkesztve ]
-
lee56
őstag
Igen, a célt tekintve logikusnak hangzik, mert jelenleg látszólag is nagy gond nekik a CPU részt kipofozni, miközben az IGP-t is hízlalják azért, hogy nyeregben maradjanak legalább iGPU fronton.
Ha a fusion álá HSA valóban sikeres lesz, nyugodtan csökkenthetik is akár a CPU részt az elkövetkező generációknál.De azért ez még nagyon a jövő, az átmeneti időkben pedig egyre jobb CPU nélkül nem tudom mi lesz velük.
Ugyanakkor izgalmas lesz tényleg ha az Intel végül mégis más utat választ (bár látszólag most ők is az IGP-jükre fókuszálnak inkább), érdekes dolgok jöhetnek ki azért.
No Comment
-
#13085
 kriszpontaz
veterán
kriszpontaz
veterán
kriszpontaz
veterán
Arra van valami esély hogy a Kaveri APU-ba esetleg bekerül a TrueAudio DSP?
-

#24650752
törölt tag
"A Jaguar ugyanis egy jobb, hatekonyabb, gyorsabb architektura osszessegeben, es ha megfeleloen fel tudjak skalazni orajelben, akkor siman az lehet a jovoje az AMD mainstream desktop/mobil platformjanak is."
Izgalmasan hangzik. Engem azóta foglalkoztat ez a kérdés, mióta kiderült, milyen processzor lesz az új konzolokban.
-
Abu85
HÁZIGAZDA
válasz
 #24650752
#13086
üzenetére
#24650752
#13086
üzenetére
Bármelyik GCN-es grafikus vezérlőbe berakható a TrueAudio blokk. Akár IGP-be is. De fontos, hogy csak GCN grafikus vezérlő mellett működik, mert a Windows audio stack-je nagyon korlátozott, így az AMD a hangfeldolgozást a WDDM-en keresztül csinálja.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-

Oliverda
félisten
Én egyelőre nem látok ekkora jövőt a Jaguarban. Még nem volt szerencsém saját kezűleg tesztelni, így csak más eredményeiből tudok kiindulni. Az 1,5 GHz-es, négymagos A4-5000 1,5 pontot ért el CB 11.5 alatt. Optimistán számoljunk tökéletes skálázódással az órajel emelésével párhuzamosan, így egy 3 GHz-es modell elméletben kereken 3 pontot kapna.
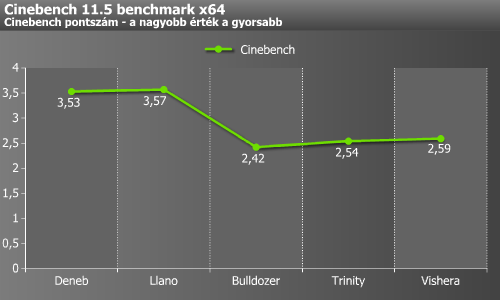
A fenti eredmények minden esetben négy, 3 GHz-re állított maggal születtek, így jól összevethető a teoretikus Jaguarral.
A Vishera-nál így elméletileg 16%-kal lenne gyorsabb azonos órajelen illetve magszám mellett a Jaguar egy olyan területen, ami (eddig) a BD-alapú megoldások egy elég gyenge pontjának mutatkozott ([link]).
Egyetlen 32 nm-es Bulldozer modul 2 MB az L2 cache-sel együtt 30,9 mm2, ami 28 nm-en kb. 24 mm2 lenne. Két darab 28 nm-es Jaguar mag 6,2 mm2, 2 MB L2 pedig saccra ~10 mm2 lehet, ami összesen 16 mm2. Ez ugyan 8 mm2-rel kisebb, de azt még mindig nem tudjuk, hogy mennyivel kéne megtoldani a magokat ahhoz, hogy 3,5-4,0 GHz-es frekvenciára is képesek legyenek, illetve hogy a komolyabb, 2P-4P szervereknél is megállják a helyüket. Egy szó mint száz, én még egyáltalán nem vagyok biztos abban, hogy ezzel együtt más területekre is olyan jó alternatíva lehet ez vonal. Time will tell.
[ Szerkesztve ]
"Minden negyedik-ötödik magyar funkcionális analfabéta – derült ki a nemzetközi felmérésekből."
-
Fiery
veterán
válasz
 Oliverda
#13089
üzenetére
Oliverda
#13089
üzenetére
"Ez ugyan 8 mm2-rel kisebb"
Vagyis a Jaguar 33%-kal kisebb, mint a BDZ, de kozben gyorsabb nala. Vagy a BDZ 50%-kal (!) nagyobb, mint a Jaguar, mikozben (clock-for-clock) lassabb nala. A 8 mm2 kicsinek tunik, de itt az arányokat erdemes nezni.
"illetve hogy a komolyabb, 2P-4P szervereknél is megállják a helyüket"
Az AMD mar egy ideje lenyegeben kiszallt a 2P-4P szerverek piacarol, tehat a Jaguar legfeljebb 1P szerverben kell hogy jol teljesitsen.
[ Szerkesztve ]
-
stratova
veterán
Ehhez képest az Opteron 6300-as vonal (Pieldriver) Warsaw réven még úgy néz ki kap egy frissítést (gondolom, kb olyat mint Trinity/Ruchlanddel).
miklosss2012 bár a kérdés nem nekem szólt, AM3+ Socket C32-vel egyetemben egy ideje már kikerült a szerver útitervből, pedig ott még több értelme van a több mag kisebb órajel melletti felállásnak, mint asztali vonalon. Szvsz AM3+ nyugdíjazva lett.
[ Szerkesztve ]
-
Oliverda
félisten
Igen, de ezzel most nem sokat érnének a felsőbb kategóriákban, mert a Jaguar nem tud ~4 GHz-et, ha pedig átterveznék a magasabb órajelnek megfelelően, akkor kétlem, hogy megmaradna ez a kis méret.
Egyébként reális(abb) összehasonlítást majd a Steamrollerrel lesz érdemes csinálni, mivel ugye hasonló gyártástechnológiával fog készülni.
Nem tudok róla hogy kiszálltak volna a 2P-4P-ről, vagy hogy ez bárhol is szóba került volna. Most Inkább épp oda lenne érdemes összpontosítani, hisz míg a desktop szegmens egyre zsugorodik, addig a szerver folyamatosan növekszik. Ha igaz a pletyka akkor 2015-ben új platform jön SR-alapú CPU-kkal.
"Minden negyedik-ötödik magyar funkcionális analfabéta – derült ki a nemzetközi felmérésekből."
-
Fiery
veterán
válasz
Oliverda
#13093
üzenetére
A magasabb orajel elerese azert nem annyival tobb tranzisztort igenyel. A kerdes az, hogy a jovot az AMD a modulos felepitesben latja, vagy a Jaguarban. Majd kiderul.
A 2P/4P szerver szegmensben, valamint a HEDT szegmensben az AMD egyre kevesbe kompetitiv, sajnos. Mar a Sandy Bridge-E/EN/EP elleneben sem állták a sarat, az Ivy Bridge-E/EN/EP pedig még jobban elhuzott. A Nehalem-EP idejeben me'g hellyel-kozzel mukodott az MCM-es strategia (azaz plusz magokkal potoltak a "hianyt"), de mostanra mar azzal egyutt is nagyon keves az, amit az Opteronok nyujtani tudnak. Az APU-s, HSA-s mokazas pedig -- egyelore -- hidegen hagyja a szerveres sracokat, nekik nyers ero kell(ene). Az AMD pedig nem a nyers eroben latja a boldogulasa kulcsat, ugyhogy ebbol az konnyen lederivalhato, hogy a HEDT es a 2P/4P szegmensbol is effektive kiszalltak. Nyilvan ezt nem fogjak nyiltan beismerni, de a hivatalos termek tervekbol jol latszik, hogy maximum alibizesre (Warsaw) futja az erejukbol, igazi uj HEDT/szerver core nem jon jovore sem, azutan sem. A pletykak meg hiaba kapnak szarnyra, semmi alapjuk nincs, sajnos. Az AMD most pont azon dolgozik, hogy kiszalljon azokbol a teruletekbol, ahol nem kompetitivek (HEDT, 2P/4P szerver), es ahol elorelathatolag sosem lesznek ujra azok; es inkabb azokra a szegmensekre fokuszalnak, ahol latnak eselyt a feltamadasra (Kaveri), vagy ahol mar most is erosek (Jaguar). Meg persze a custom APU-k (konzolok).
[ Szerkesztve ]
-
Oliverda
félisten
Ha ez valóban így van akkor miért erőlködnek a Warsaw-val? Hiába nem új lapka, ennek a forgalomba hozása sincs ingyen, ergo valamiért még invesztálnak ebbe a szegmensbe.
Elvileg novemberben elérhetővé válik az új roadmap. Abból remélhetőleg már pontosan lehet látni az irányokat.
[ Szerkesztve ]
"Minden negyedik-ötödik magyar funkcionális analfabéta – derült ki a nemzetközi felmérésekből."
-
Fiery
veterán
válasz
Oliverda
#13095
üzenetére
Egy facelift me'g mindig sokkal egyszerubb, mint egy zsir uj CPU-t tervezni. Raadasul me'g azt sem lehet tudni, hogy a Warsaw pontosan mennyi ujdonsagot fog hozni. Me'g az sem kizart, hogy kevesebb kulonbseg lesz az elozo "generaciohoz" kepest, mint a Trinity --> Richland valtasnal. Lehet, hogy csak emelnek 100-200 MHz-et az orajelen, es kap egy uj kodnevet. Lasd videokartyak, ott is mukodik az atnevezosdi
(Zarojelben jegyzem meg, hogy mar volt egy komplett AMD szerver CPU generacio, ami a kukaban vegezte, me'g az sem kizart, hogy a Warsaw-bol sem lesz semmi...)
[ Szerkesztve ]
-
Abu85
HÁZIGAZDA
válasz
Oliverda
#13095
üzenetére
Egy rakás SM15000 szervert szállítanak, amiben aktuális Opteron van. Azt később az ügyfelek lecserélik majd az új Opteronra. Például a Verizon rengeteg ilyen szervert rendelt. Az AMD megerősítette, hogy az eladott gépekben mostani Opteron lesz. A Verizon ezeknek később megduplázza a memóriáját, majd második fázisban lecserélik a procikat új Opteronokra. Ezért éri meg ebből még egy kört csinálni.
Utána csak APU lesz. A szerverpiac ugrott rá leginkább a HSA-ra. Ott a GPU-s gyorsítással rengeteget lehet megspórolni.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
-
Abu85
HÁZIGAZDA
Azt tudom megmondani, hogy a szervereknél a tradicionális feladatokat próbálják gyorsítani GPU-val. Ezt már ma is csinálják. A Facebooknak rengeteg Radeonja van a memcached technika offloadjára, csak nagyon megnő a fogyasztás, és nem gyorsul lényegesen. De nyilván ezen az integráció és főleg a közös memória sokat segít majd. Ez egy tipikus munkafolyamat, amire nagyon jó a GPU és sokszoros gyorsulás érhető el.
De van még a Hadoop és SQL gyorsítása, suffix tömb gyorsítása, Java GPGPU opciók, szimulációs feladatok. Ezekre mind jó a HSA, és nagyon tipikus munkafeladatok az adott szerverekben. A gyorsulás mértéke pedig sokszoros lehet.
A HSA nem a direkt verseny miatt érdekli a cégeket, hanem amiatt, hogy ugyanazt tizedannyi fogyasztásból megcsinálják.Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Mi internetes képátvitellel kezdtünk el dolgozni az utóbbi években, és mi is GPU-val kezdtük a fejlesztést, mert 1,5-2,5-szeres ár/teljesítmény és teljesítmény/fogyasztás adat jön ki bármilyen x86-hoz képest a jelenlegi kódunkkal. Mondjuk mi nV-CUDA társaság vagyunk, mert az AMD linux alatt szoftveresen nem elég megbízható jelenleg sem, és a fejlesztőkörnyezetek sem olyan jók. Windózra meg nem akarunk váltani emiatt. Azóta már vannak GCN-es Radeon-ok, és folyamatosan napirenden van a váltás vizsgálata, de eddig mindig voltak szoftveres gondok, amik miatt nem lenne megbízható döntés, hiába izmosabb a GCN-es hardver.
[ Szerkesztve ]
Eladó régi hardverek: https://hardverapro.hu/apro/sok_regi_kutyu/friss.html






















 Az Intel pedig mar azert ott van a "szeren" 30 eve (akarcsak az AMD, mellesleg), az x86 pedig eddig bizonyitott. A Silvermont baromi jol sikerult (akarcsak a Jaguar). 10 colos full passziv huteses slim profile tablet = 12-14 ora egy feltoltessel, 4 magos Bay Trail-T procival -- ezt is ki gondolta volna 2-3 eve? Hidd el, az x86-ban me'g nagyon sok minden van. A MIC talan nem valtja meg a vilagot, de rengeteg otlet van me'g a fiokok mélyén ill. a mernokok fejeben. Nekem is lennenek naiv otleteim, pl. hogy mikepp lehetne kivaltani az iGPU-t CPU-val, de majd az Intel _talan_ megcsinalja, amig az AMD a HSA-t nyomatja. Izgalmas lesz a kovetkezo 2 ev.
Az Intel pedig mar azert ott van a "szeren" 30 eve (akarcsak az AMD, mellesleg), az x86 pedig eddig bizonyitott. A Silvermont baromi jol sikerult (akarcsak a Jaguar). 10 colos full passziv huteses slim profile tablet = 12-14 ora egy feltoltessel, 4 magos Bay Trail-T procival -- ezt is ki gondolta volna 2-3 eve? Hidd el, az x86-ban me'g nagyon sok minden van. A MIC talan nem valtja meg a vilagot, de rengeteg otlet van me'g a fiokok mélyén ill. a mernokok fejeben. Nekem is lennenek naiv otleteim, pl. hogy mikepp lehetne kivaltani az iGPU-t CPU-val, de majd az Intel _talan_ megcsinalja, amig az AMD a HSA-t nyomatja. Izgalmas lesz a kovetkezo 2 ev.













Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
Az ide nem illő hozzászólások topikja:[link]
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva.

