Új hozzászólás Aktív témák
-

Abu85
HÁZIGAZDA
válasz
 Raymond
#37963
üzenetére
Raymond
#37963
üzenetére
Minden egyes képtömörítésnél (lényegében a textúráknál is erről van szó) az a kérdés, hogy a tömörítéssel vesztett minőséget megéri-e elbukni a tömörítésből származó előnyért cserébe. És itt azért nincs egzakt érték, mert projektfüggő, hogy ez konkrétan mit jelent a gyakorlatban. Minden esetben, minden projekt igényeit felmérve lehet találni egy olyan köztes pontot, ami a minőség és a tömörítés szintje szempontjából még éppen megfelelő az adott felbontásokra vonatkozóan.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#38032
Abu85
HÁZIGAZDA
->Raizen<-
#38031
Abu85
HÁZIGAZDA
válasz
 ->Raizen<-
#38031
üzenetére
->Raizen<-
#38031
üzenetére
jólmegszívattak
![;]](//cdn.rios.hu/dl/s/v1.gif)
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Valójában fingunk sincs, hogy mi a hiba, akkora a hírzárlat erre vonatkozóan. Ha van hiba egyáltalán, és nem csak arról van szó, hogy túl sok a komponens, ami a megszokotthoz képest megnövelte a bedöglő hardverek számát.
(#38337) .Z. : Nem a Frostbite motor a lényeg, hanem a verziószám. A BFV-nél a legújabb verzió dolgozik, míg az Anthemben még a BF1-nél is régebbi. Most ettől ne várjatok BFV sebességet.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#38371
Abu85
HÁZIGAZDA
Petykemano
#38370
Abu85
HÁZIGAZDA
válasz
 Petykemano
#38370
üzenetére
Petykemano
#38370
üzenetére
Igen. Lassan megmaradok.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Az NV soha nem cáfol vagy erősít pletykát. Ez alapvetően egy protokoll. Ebből még nem következik semmi. A Micron azért érdekes feltételezés, mert akkor az azt jelentené, hogy a legyártott RTX-ek fele rossz, mert kb. ilyen arányban látja el a Micron és a Samsung a rendeléseket. Ezért nem valószínű a Micron. Sokkal valószínűbb egy másik komponens, ugyanis vannak pletykák, hogy egy kínai gyár egy rakás rosszul specifikált VRM-et adott el a VGA-gyártóknak. De ez is pletykaszintű dolog, viszont itt annyi háttér van, hogy nem a Redditen írta Pista, hanem a TUL manapság külön kiemeli az OEM-ek felé, hogy ők nem vesznek bizonyos gyáraktól. Ugye mi értelme ezt kiemelni, ha nem lenne valami para bizonyos komponensekkel, amiket valószínűleg már sokan nem vesznek. De biztosat itt sem lehet tudni. Én elhiszem, hogy a Micron egy könnyű célpont, csak ma is tömegével gyártják vele a VGA-kat.
A hivatalos egyébként az a szöveg, hogy nincs semmi gond, minden a legnagyobb rendben a meghibásodási aránnyal. [link]

Ki kellett venni két fogamat, mert nekimentek volna a jobb alsó hatos gyökerének. Ez viszont nekem kell, így beáldoztuk a 7-8-ast. Viszont ezek be voltak nőve a csontba, legalábbis nagyrészt, így nem volt őket egyszerű kivenni. A műtét után influenzás lettem, ami nem jó kombináció, így be is gyulladt a seb, amit most kezelnek, de már annyira van bennem élet, hogy átaludjam az éjszakákat, és ne kelljen ehhez túladagolnom magam Diclofenacból.

[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 PeTeR_33
#38404
üzenetére
PeTeR_33
#38404
üzenetére
Igen. Az AMD most azt csinálja, hogy az eredetileg tervezett részletesség fölé rendel egy még nagyobb részletességet. Ezért kapott például a Far Cry 5 is egy textúracsomagot a megjelenés után, csak mostanában már a megjelenésre, vagy kicsivel utána hozzák a textúracsomagot a partnereik. Nagyon egyszerű az oka annak, amiért ezt csinálják. Az NV-nek nincs HBCC-je. Valójában az a részletesség, amit adnak az extra textúracsomag leginkább 4K-ban számítanak. Full HD-ben elég az egyel kisebb beállítás, amivel eleve érkezett volna a játék, ha az AMD nem rendelné a nagyobb részletességet.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 TTomax
#38413
üzenetére
TTomax
#38413
üzenetére
Nem kell ezt ennyire mellre szívni gyerekek. Ha az AMD nem fizet azokért a textúrákért, akkor be se kerülnek a játékba. Szóval, akinek ez nem tetszik kiválasztja az Ultra helyett a High részletességet, és menni fog. Aki pedig nagyon érzékeny a legapróbb részletekre is, vesz olyan VGA-t, amin van elég VRAM.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
TTomax
#38416
üzenetére
Az egész VRAM kezelése nem normális PC-n, ez tökre látszik a HBCC-n, ami akár negyedannyi fizikai memóriával is működik, mint a játék követelménye. Egyszerűen nagyon magas a pazarlás, tipikusan kétszeres-háromszoros. Szóval a probléma igazából nem a valós igénye a játéknak, hanem a WDDM-en belüli, rendkívül rossz hatásfokú erőforrás-kezelés. Ezt nem lehet megoldani szoftveresen. Hardveresen kell fellépni a allokációk kezelésénél keletkező probléma ellen.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Raymond
#38420
üzenetére
Egyik játéknál sem az igazi. Amíg konzolon sokkal hatékonyabban bánnak a memóriával a programok, addig PC-n nincs közvetlen hozzáférés az erőforrásokhoz. Az más kérdés, hogy nem is lehet, mert sokféle konfiguráció van, de ettől még nem volt jó az a modell, ami a rendelkezésre állt. Ezért jöttek az explicit API-k, amiknél a jó hír, hogy megoldottuk az allokációk törlésének a problémáját, ezért jár a pacsi, viszont eközben átestünk a ló túloldalára, ami már túl bonyolulttá teszi a fejlesztőknek a memória hatékony kezelését. Tehát effektíve megoldottunk egy problémát, de közben teremtettünk egy újat. Elméletben kezelhetőt, de egy pénz mozgatta világban a gyakorlat mást fog mutatni.
A HBCC teljesen más tészta. Ez nem szoftveresen akarja kezelni az egyes problémákat, hanem gyökerestül új megoldást kínál, aminél a jelenlegi problémák már a működésből eredően nem is létezhetnek.
Az persze igaz, hogy az ok ugyanúgy az volt, hogy a mai programok elpazarolják minimum a memória felét: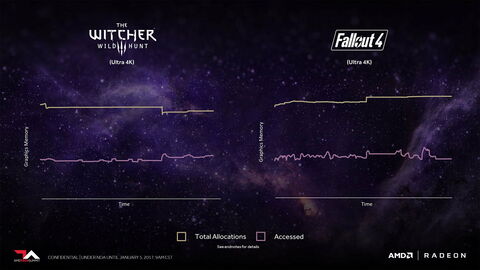
De a megoldás tekintetében hardveresen alakította át az egész rendszert az AMD.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
atok666
#38432
üzenetére
A GPU memóriáját. A sárgás vonal a fizikailag lefoglalt allokáció a VRAM-ban, a másik pedig azok az allokációk, amelyekhez tényleg hozzá is nyúlt a hardver, és nem csak a helyet foglalják.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
atok666
#38434
üzenetére
Úgy kell elképzelni, hogy a VRAM-ba allokációk kerülnek. Mondjuk van egy adat, ami kell, de az nincs benne a VRAM-ban, akkor az API-n keresztül megkereshető, és az az allokáció, amiben van az adat a rendszermemóriából átmásolható a VRAM-ba. De mindegy, hogy mennyi adatra van belőle szükséged. Ha csak 4 kB-ra, akkor is másolni kell a teljes allokációt, ami lehet akár 100-400 MB is. Tehát 4 kB-ért elpazarolsz akár 400 MB-ot. Ez egy extrém eset, de lényegében erről van szó. Nyilván egyébként az adott allokációkból nem csak 4 kB fog kelleni, de eléggé tipikus, hogy nem kell majd az összes, sokszor még az 50%-a sem, de muszáj másolni, mert másképp nem nem működik a mostani rendszer.
Az AMD pont ennek a gyökerébe nyúlt bele a HBCC-vel. Ez a rendszer lapalapú. Azt mondja, hogy ha csak az a 4 kB kell, akkor másold csak azt, ne rakjál emiatt 400 MB-ot a VRAM-ba, ami aztán úgyse kell.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
TTomax
#38436
üzenetére
Csak API szinten nem lehet. Nem a lapalapú menedzsmentre találták ki a rendszert. Új WDDM-mel és egy ahhoz írt teljesen új API-val megoldható lehetne, de annyira nagy változás szükséges hozzá, hogy megint dobni kell a kompatibilitást. A legegyszerűbb módja ennek a hardveres megoldás, vagy hardveresen asszisztált, amivel a Microsoft az OS szintjén kezelné azokat a hardvereket, amelyeknél az x86/AMD64 licenc hiánya probléma. De nem biztos, hogy mondjuk az NV nem nyomná kapásból a nagy piros NEIN gombot, mert az AMD és az Intel teljesen hardveres tud lenni, ők pedig egy szoftveres rétegre lennének utalva. Nekik sokkal inkább az lenne a jó, ha a Microsoft beemelné az ARM-ot az ökoszisztémába, és kivégeznék a picsába a Win32-t, aztán mehet minden a Store-ról.
(#38437) HSM: Azok az adatok picik méretileg. Ezért nincs igazából ebből probléma, feltéve, ha nincs nagyon elbaszva a motor streaming rendszere.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
atok666
#38439
üzenetére
Az allokációk lehetnek eltérő méretűek, de nem célszerű mondjuk nagyon kicsi allokációkat csinálni, mert eléggé eltérő az, ahogy az AMD, az Intel és az NV drivere kezeli a memóriát.
DX12-ben (és Vulkan API-ban is) nem a nyers mennyiség határozza meg igazán a működést, hanem a memória strukturális felbontása:
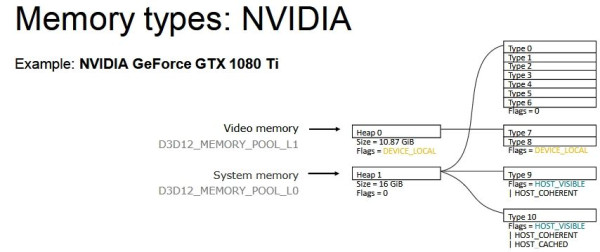
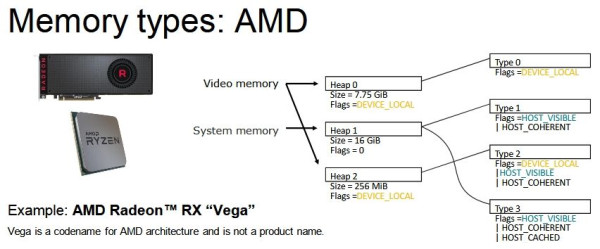

Na most egy olyan megoldás kell, ami jól működik a fenti három struktúrán belül. Tehát az nem elég jó, hogy működik AMD-vel, mert akkor az Intel és az NV szopni fog. Egy közös többszöröst kell keresni.Ha ez megvan, akkor ott a töredezettség problémája, vagyis vagy ugyanolyan méretű lesz minden allokáció, ami nem túl szerencsés, vagy végül a sok allokáció cseréje miatt fragmentált lesz a VRAM egy idő után. Tehát előfordulhat, hogy van szétszórtan 200 MB szabad hely, de nincs egybefüggően, tehát mindenképpen törölni kell egy allokációt, hogy egy új 200 MB-os beférjen.
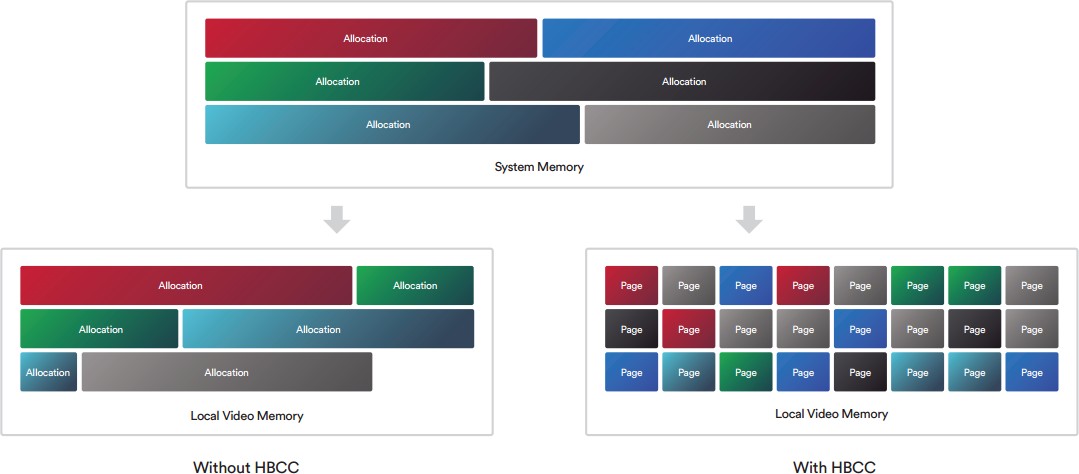
Itt láthatod, hogy ha azt a fekete allokációt a rendszermemóriából be akarod másolni a VRAM-ba, akkor egyszerűen nem tudod megtenni, mert nincs annyi egybefüggő szabad hely. Ki kell törölni mondjuk a pirosat és a zöldet. Ugye itt a HBCC is látható, ami lényegében azt valósítja meg, amit kvázi elgondolsz. Ne is másold az allokációt, hanem csak a szükséges lapjait. Mindegyik lap ugyanakkora, tehát a töredezettség kizárva, illetve mindig az van a memóriában, ami kell. De a jelenlegi API és WDDM kombinációja ezt a megoldást nem támogatja. Nem erre tervezték a rendszert. Meg lehetne oldani, viszont akkor nulláról kell kezdeni az egészet, vagyis új API, új display model, új meghajtók, új hardverek, új OS.(#38440) mormota79: Nem annyit használ, hanem jóval kevesebbet, de mivel a WDDM-et nem tervezték ilyenre, ezért az AMD meghajtója egy trükköt alkalmaz. Amikor bekapcsolod a HBCC-t, akkor keletkezik egy olyan erőforrás, aminek a fedélzeti memóriája megegyezik a beállított HBCC szegmenssel. Legyen az mondjuk 24 GB.
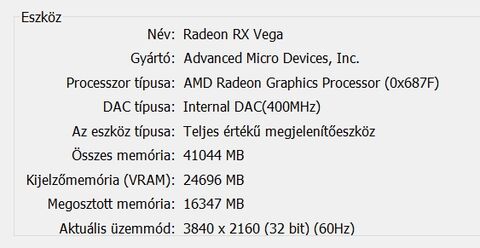
Ilyenkor az OS felé és a programok felé az egész VGA úgy néz ki, mintha egy 24 GB VRAM-mal rendelkező hardver lenne. Ez alapvetően befolyásolja a programok által kiolvasott adatokat, hiszen a meghajtónak el kell rejtenie mindent, ami a háttérben történik ahhoz, hogy az OS felé gyakorlatilag tudjon hazudni a valós hardverről, amin fizikailag nincs 24 GB-nyi memória. Na most ezt még az AMD saját eszközei sem tudják mérni, mert nyilván hazudnia kell az adatokról a meghajtónak, hogy a háttérben a HBCC működhessen, és az AMD profilozói is ezeket a hazugságokat látják csak, ahogy például egy 3rd party program is csak ennyit tud elérni, plusz a Windows is csak ennyit lát. Egyébként létezik egy külön hardver, amit a fejlesztők igényelhetnek. Ez lehetővé teszi, hogy a HBCC mód valós működését kiolvashassák, de ehhez nem lehet hozzájutni átlagemberként. Szóval mi csak azt láthatjuk, amit a driver hazudik.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 hokuszpk
#38580
üzenetére
hokuszpk
#38580
üzenetére
DLSS és DXR külön jön. Valószínűleg két cikkben, de ezt még nem tudom megmondani.
(#38583) Petykemano: Nem. Mi ezt a tesztplatformot október első felében raktuk össze. Azóta nem változtattunk rajta.

(#38584) b. : Nem eldöntöttük. Vannak mérések a mérnöki mintáról. Ezeket ugyan nem árulhatjuk el, de az AMD például nyilvánosságra hozta a CES-en, hogy az új EPYC-ből egyetlen CPU fog annyit tudni teljesítményben, mint az Intelből két csúcs-Xeon (és ez egyébként egy low power modell lesz, tehát jön nála gyorsabb). Ez most egy Athlon 64-es sztori lesz megint. Két gyártástechnológiai lépcső előnye már meglátszik.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Nem sok köze lehet ezekhez. Az NV részvényei a jövőképért voltak felárazva. Az automotive és cloud gaming vitte előre, mert ebbe raktak egy csomó pénzt. De a cloud gamingből a nagyok nem igazán az NV megoldásait választják, míg az automotive esetében is lassan jönnek a konkrét sikerek. Ezzel együtt most kezdődött visszacsúszni a felülárazás a kriptodöglés hatására, így most érdemes kiszállni. Valószínűleg pozitívban vannak. Ha lemegy újra a részvény 30-40 dollárra, akkor újra vásárolnak egy csomót. Ez üzlet számukra, nem kell sokat belelátni. A pénzt befektetik olyan cégekbe, ahol a részvényár a hegyre felfelé megy, és nem lefelé jön onnan.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Régen tudtál. Valószínűleg a Softbank sokat vett ennél olcsóbban is. Most jött el az a pont, amikor megéri kiszállni, és átülni egy másik részvényre. Majd visszaszállnak, ha újra olcsón tudnak NV részvényt venni. Általában egy befektető a gyengén árazott részvényt keresi a jövőképpel, mert azon lehet sokat nyerni. Ha a völgyben vagy, akkor onnan csak felfelé van út, de ha a hegyen, akkor csak lefelé. Ilyen ez a részvénypiac, rosszul hangzik, hogy kiszállnak, de túl nagy jelentősége azért nincs.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 #04430080
#38793
üzenetére
#04430080
#38793
üzenetére
Az Extreme csak a shading rate-et növeli 200%-ra, ami azért hülyeség, mert miért is kellene natív felbontás feletti árnyalás, ha közben a felbontásod igazából nem nő?
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Nem a shading rate miatt más a Guru3D, hanem a benchmark miatt. Annak a terhelése worst case. Azért van úgy megcsinálva, mert ha ott megvan a 60 fps, akkor a játék összes részén meglesz, míg ha csak sima gameplay-t nézel, akkor azt is be tudod lőni mondjuk 60-ra, de lehet, hogy a megterhelő részeken abból lesz 40-50 is. Direkt vannak így csinálva a benchmark részek a játékoknál, hogy reális legyen a legrosszabb eshetőségre.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Igazából lehetne értelmet találni, csak annyira nem költenek rá erőforrást, hogy kvázi használják az NV kidolgozott cuccait, amelyek talán nem is illeszkednek jól az adott motorba, stb.
Most lehet, hogy megköveztek, de én simán használnám fizikailag korrekt hangleképzésre.
Ez független a grafikától, tehát a motornál a raszterizációhoz meghozott döntésekkel nem kellene megküzdeni (amivel jelenleg eleve nem küzdenek, hagyják úgy ahogy van, aztán olyan lesz amilyen a DXR, a lényeg, hogy az NV fizessen).Amire amúgy simán jó lenne az a valós idejű lightmap. Oké, piték még a mai hardverek erre, de három év múlva már elég gyorsak lesznek.

Szerk.: A különbség látszik, csak a képek felén az RTX off tetszik, a másik felén az RTX on.
Jó lenne ez egyébként, csak az a baj, hogy igazából mindent a motorban a raszterizációhoz szabtak, és arra csak úgy ráengedni az RT-t, hát nem túl okos dolog. Érdemes lenne ehhez külön is dizájnolni, de én úgy gondolom, hogy kb. úgy megy ez az adott stúdiónál, hogy építsük szimplán be, karoljuk fel a pénzt, aztán viszlát.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
-
Abu85
HÁZIGAZDA
Az early access a kísérleti funkciókat jelöli az UE4-ben. Ezek általában egy verzióval később lesznek véglegesek. Mondjuk az igaz, hogy ennél a motornál ez mindegy, sokszor a végleges funkciók sem működnek.
(#38815) b. : Érdekes, hogy a PhysX-hez kapcsoló van rendelve. Végül csak a PhysX cloth maradt a játékban, annak is van DirectCompute back-endje, és alig terhel. Akkor lenne értelme a kapcsolónak, ha nem vették volna ki a particles és a destruction effekteket.
(#38817) Raymond: A Vulkan még mindig Early Access, pedig már ott volt a 4.20 Previewben. Még a 4.22-ben is marad Early Access egyébként. Ezért is tértem át Unity-re, mert fájdalmasan lassan kap végleges státuszt valami. Egy, de inkább két verzió mire az összes engine komponenssel kompatibilis lesz. Persze az igaz, hogy a Vulkan is használható a 4.20 óta, de csak limitációkkal.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 GodGamer5
#38946
üzenetére
GodGamer5
#38946
üzenetére
Az Anthem az DX11. Mint írtam egy nagyon régi, nagyjából három+ éves Frostbite verziót használ. Még az első Star Wars Battlefront is újabb Frostbite-tal ment. Ebbe amúgy bele lehet műteni a DX12-t, de az nem lesz igazán jó, mert nagyon-nagyon régi a parancsgenerálásra vonatkozó kód. Legalább a Battlefield 1 Frostbite verziójára át kellene állni a normális DX12-höz, de az meg eléggé nehézkes, mert pont olyan területeken történt változás, ami nem teszi kompatibilissé a régi motorverziókkal a megfelelő működést.
Ezért sem fut igazán jól a hardvereken, mert hiába kevésbé komplex a grafikai szint, mint például a Battlefield V esetében, akkor is évekkel régebbi a motor, és ez a sebességén látszik.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#38953
üzenetére
A release szám csak akkor ér velemit, ha a Frostbite Teamhez kapcsolódik, de mivel a Frostbite-ot az EA-n belül több stúdió is megkapja, így némely leányvállalat külön fejleszti a Frostbite Teamtől. Ezért nincs benne DX12, hiszen maga a motorverzió még az MEA közvetlen továbbfejlesztése, de nem emelték át bele a Frostbite Team újabb leképezőit, amelyek azért sokkal gyorsabbak, mint amit anno kapott a Mass Effect.
A Bioware elkérheti a legújabb leképezőt is a Frostbite Teamtől, de ez csak a 2016-os parancsgenerálással kompatibilis, vagyis a Frostbite Team 2015-ös alapjaira építő motorba nem építhető bele, így nem kompatibilis az Anthem által használt rendszerrel. Hiába írod a release mögé a 2017-et, az már a te mellékágad, és nem a Frostbite Teamé. Át kell állni legalább a 2016-ös főverzióra!, hogy működjön. Onnantól kezdve viszont nagyon könnyen beépíthető akár a Battlefield V DX12-es leképezője is, hiszen a kompatibilis alapok megvannak hozzá. Viszont az Anthemhez ez nem jó, így oda egy különálló DX12 leképező készült, csak nem igazán működik. Még...A motorverzió a DX12 szempontjából mindegy. Az alapvető követelmény a 2016-os Frostbite főverziójának parancsgenerálása, és ahhoz használható a 2016-ös, 2017-es, vagy 2018-as DX12 leképező is. Ezek között nincs olyan hatalmas különbség egyébként. Majd a 2019-es változik inkább, ott jön a régóta ígért Tiled Light Trees: [link]
(#38954) Puma K: Semmi baja nincs magának a DX12 API-nak, de akkor működik igazán, ha a parancsgenerálás is ehhez van szabva. Ez a váltópont a Frostbite-nál a 2016-os verzió volt. Abban egy csomó dolgot bevezettek még, shader intrinsics, compute culling, egy rakás GPGPU-s trükk. Ez mind hiányzik a Bioware motorverziójából, tehát az ezek által nyerhető +70-80% teljesítmény sincs ott. Persze a Bioware eléggé különc az EA-n belül, nekik fontosabb a fejlesztőeszközeikkel való kompatibilitás megőrzése, míg a DICE azért sokkal gyorsabban lépked előre. Az is igaz persze, hogy sokkal több erőforrásból.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
#85552128
#38956
üzenetére
A Bioware a Mass Effecthez igényelt motort még 2013-ban. Azt fejlesztik azóta is. Eléggé külön haladnak a Frostbite Teamtől, hiszen teljesen más fejlesztőeszközöket használnak.
A Frostbite Team esetében az a probléma, hogy nagyon gyorsan fejlesztenek, mert nekik lényegében csak ez a koncepció. Emiatt annyira töredezett a Frostbite használata az EA-n belül, mert amíg a Frostbite Team lényegében a kompatibilitást is megvágja a sebességért, ez azért egy játékon éppen dolgozó stúdiónál nem realitás. A legtöbben egyszerűen csinálnak maguknak mellékágakat abból a verzióból, amelyet még régen elkaptak, de újakra csak ritkán állnak át. A Bioware pedig ennek a legextrémebb példája, ők egyszerűen minimálisan sem hajlandók megvágni a kompatibilitást, így ők azok, akik a legtöbb limitációt szenvedik el ettől.
Lényegtelen, hogy valami open world vagy nem. Előbbi inkább a tesztelést bonyolítja, de a mai motorok már alapvetően streaming rendszerek, tehát a működés szintjén édesmindegy, hogy a játéktér mekkora, mert ugyanúgy nem tölti be a teljes pályát, hanem csak a játékos közelében lévő részeket, és ugyanez igaz a nem open world játékokra is. Nem ez számít igazán, hanem az, hogy a leképező hogyan vágja ki a fényeket, a nem látható háromszögeket, stb. Ebben több a 2016-os Frostbite verzió, amit a Frostbite Team tervezett meg, és nyilván a GPGPU culling nagyon sokat segít, hiszen ennek a hatékonysága egésze extrém szintet üt meg. A fények jobb kivágása még várat magára, mert maradt még a deferred+, illetve a 2018-as verzióban a clustered deferred, de 2019-ben jön a Tiled Light Trees. [link] - ezen a videón látható, hogy látványosan hatékonyabb. Ebből is simán nyernek +20-30%-ot.
(#38957) TTomax: Bezony. A GPGPU culling célja az volt, hogy hatékonyabb legyen a nem látható háromszögek kivágása. Mivel a Frostbite rendszere az eredeti cullinghoz képest sokkal több nem látható háromszöget is képes eltávolítani még a leképezés megkezdése előtt, így sokkal kevesebb munka hárul a GPU-ra. Nyilán az eredeti megoldással is ugyanaz lesz a képkocka, csak ott akkor dobod el a nem szükséges adatokat, amikor már a hardver mindent kiszámolt rájuk. Ezért vezették be ezt az újdonságot, hogy még a számítások előtt váljanak meg a nem szükséges adatoktól.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
TTomax
#38960
üzenetére
A compute culling compute shadert követel, nem muszáj hozzá DX12.
(#38961) Szaby59: A PBR bármibe bele lehet rakni. A forráskódot ismerik szóval nem nagy kunszt. Ennek a nehézsége nem igazán a programkód megírása.
Nem tudom igazából, hogy milyen stabilitási dologról van szó. A compute culling kikapcsolhatatlan. Nincs szállítva mellette a legacy culling path. Túl körülményes lenne megoldani ezt egy végtermék szintjén.
Senki sem beszélt a DX12-ről. Ez egy API, de az eljárások alatta API-tól függetlenek. A leképező az egyetlen különbség, de az kb. kétezer kódsor, ami a teljes motorhoz képest igazán elhanyagolható. Funkcionális szempontból viszont a DX11 és a DX12 ugyanarra képes, csak utóbbival van explicit párhuzamos parancsgenerálás.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#38969
Abu85
HÁZIGAZDA
Petykemano
#38968
Abu85
HÁZIGAZDA
válasz
Petykemano
#38968
üzenetére
Milyen culling sztorinak?
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#38971
Abu85
HÁZIGAZDA
Petykemano
#38970
Abu85
HÁZIGAZDA
válasz
Petykemano
#38970
üzenetére
De ez miért érdekes a Windows szempontjából? Ezer éve benne van a driverben. A Linuxon azért történnek ilyenek, mert a Windows erőforrások huszadából készül a támogatás. Nem mellesleg a GPGPU culling a motorba építve sokkal hatékonyabb, nem véletlen, hogy oda rakják be.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 Milka 78
#39014
üzenetére
Milka 78
#39014
üzenetére
Az FRTC-t és a Chillt együtt felesleges használni. Az FRTC csak egy legacy fícsőr. Azért maradt benne a driverben, mert az implementáció jellege miatt nem kell karbantartani, de a funkciót teljesen ki tudja váltani a Chill, ráadásul sokkal jobban.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
TTomax
#39047
üzenetére
Az Intel nem úgy képzeli ezt el, hogy majd te választasz a proci mellé VGA-t, hanem odarakják a dedikált GPU-t a tokozásra, és kifizettetik veled, akkor is, ha neked nem kell. Ilyen szempontból az OEM-eket már megnyerték, mert ők aztán tuti nem raknak majd VGA-t a gépekbe, ha közben az Intelnek muszáj fizetni ezért +200-400 dollárt.
Az AMD is ugyanezt fogja csinálni. Látod, hogy már felkészültek rá az I/O lapkával, ami mellé nem csak CPU chipletet rakhatsz, hanem ugyanúgy beköthetsz IF-en keresztül egy dedikált GPU-t is. És onnantól kezdve az OEM-ek döntésének megint harangoztak, mert nyilván nem éri meg az extra VGA-val jelentős többletköltségbe verni magukat.
Szóval nem, nem abból lesz piaci előny, hogy leraknak valami "dulva" cuccot az asztalra, hanem abból, hogy eldöntik, hogy ezt veheted meg és kész. Aztán verheted az asztalt, hogy neked kurvára nem kell, de ez a kínálat, szóval vagy fizetsz érte, vagy veszel konzolt.Azt veszi amúgy itt az Intel számításba, hogy ha az OEM-eket kiüti a VGA-piacról, akkor olyan szinten megdrágul a VGA-k gyártása, hogy luxuskategória lesz az egész szegmens, és ezzel gyakorlatilag mesterségesen kihúzzák a piac alól a jelenlegi vásárlóbázis 80%-át. Így nagyon könnyű ám piacot nyerni.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#39065
Abu85
HÁZIGAZDA
zovifapp111
#39048
Abu85
HÁZIGAZDA
válasz
 zovifapp111
#39048
üzenetére
zovifapp111
#39048
üzenetére
Egyáltalán nincs szükségük arra, hogy az NV-nél és az AMD-nél jobbat csináljanak. Az Intel a processzoraira fog építkezni. Ezzel kiszolgálják a teljes PC-s piac 70-80%-át, és azt fogják mondani az OEM-eknek, hogy a CPU-k mellé jár majd a tokozáson a dGPU. Az OEM kérdezheti, hogy nincs-e csak CPU, de az Intel majd mondja, hogy nincs. Fizesd ki a dGPU-jukat, és kapcsold ki, ha akarod, de ez ugye akkora extra költség, hogy épeszű OEM úgy sem kapcsolja ki, tehát meg is nyerték a piacot. Rohadt nehéz ám vásárlóként választani hardvert, ha közben nincs választék.
A következő időszak csodafegyvere az árukapcsolás lesz. Hiába törvénytelen, az Intel és az AMD már aktívan alkalmazza. Nézd meg a cloud gaming területét. Az NV taposta ki az egészet, mégis az AMD és az Intel platformjaira kötik a nagyok (Microsoft, Google, Tencent) a szerződéseket, mert az NV nem tud csomagot kínálni processzor hiányában. És az Intel most lényegében úgy nyeri meg a Tencentet, hogy gyakorlatilag nincs is jelenleg hardvere, amit tudnak szállítani nekik, de annyira jó a csomagajánlat, hogy az NV versenyképtelen, hiába tudják azt mondani, hogy gyerekek nekünk működik is, ők meg csak papírokat mutogatnak. Még az AMD sem kínált az Intel alá a Tencentért, amiben persze az is lehet, hogy nekik ott a Google, illetve az Amazonra koncentrálnak inkább, de a komplett platform kínálata borzalmasan nagy fegyvertény, mert olyat tudsz ajánlani a partnereknek, amivel képtelenség platformszintű megoldás nélkül versenyezni.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#39066
Abu85
HÁZIGAZDA
Petykemano
#39053
Abu85
HÁZIGAZDA
válasz
Petykemano
#39053
üzenetére
Nem. A Radeon Software az Sasa Marinkovic érdeme. Ő az aki levezényelte az egész váltást, az ötletek nagy része is tőle származott. A ROCm Gregory Stoner érdeme volt, most már James Edwards viszi.
Raja leginkább az SSG-t, illetve a professzionális vonalat (hardver/szoftver) futtatta fel. Az SSG kétségtelenül egy pokolian nagy húzás volt.(#39058) Devid_81: Az Intel visszabutított 10 nm-es node-ja most már látszólag működik. Azzal nem lesz gond. Ahol problémás ezzel az eljárással, az a magas órajelek elérése, de egy GPU-nál ez amúgy sem kritikus, mert nem nagyon járnak 2 GHz fölött.
(#39061) pengwin: Az a peche az Intelnek, hogy az AMD is átdolgozta a Vega 20-ra a parancsprocesszort. Aláz is a Forza Horizon 4-ben, ahol a többi hardvernél ez a limit: [link]
Az NV is át fogja dolgozni, hiszen ehhez már évek óta nem nyúltak, tehát pont időszerű.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#39068
Abu85
HÁZIGAZDA
Petykemano
#39067
Abu85
HÁZIGAZDA
válasz
Petykemano
#39067
üzenetére
Persze. Nem azért adják ki ezeket, mert annyira jó, hanem mert így el tudják adni azt a pár százaléknyi selejtet is, amit máskor kidobnak, mert a normál gyártási folyamatokkal is ki tudják elégíteni a keresletet.
Az Intelnek elég, ha meggyőzi az OEM-eket, hogy ne vegyenek több VGA-t, jó az amit ők raknak majd a tokozásra a CPU mellé. Ha ezt megteszik, akkor a VGA-piac magától átmegy egy olyan áremelkedésen, hogy beesik a luxusszintre. A DIY nem kicsi, de nem lényeges piac, így ami jó az OEM-eknek, az jó a DIY-re is. Attól, hogy neked nem tetszenek az elérhető hardverek, még nem tudsz mást választani.
Az AMD sem fog csak CPU-val foglalkozni egy idő után. Egyszerűen nekik is lényegesen kedvezőbb, ha az OEM-eket nem kell győzködni a Radeonok megvásárlásáról, hanem megy a holmi csomagban a procin. Az Intel se véletlenül kezdett el erre fejleszteni, az ilyen megoldások nagyon veszélyesek ám rájuk is, viszont ha kínálnak ők is alternatívát, akkor simán jól kijönnek belőle.Teljesen mindegy, hogy mit játszol a memóriával. Az egészhez két komponens kell, egy memóriakoherens interfész a CPU és a GPU közé, illetve egy hardveres memóriamenedzsment. Az AMD-nek már megvan mindkettő, IF és HBCC ugye. Az Intelnek is megvan az első, ez az UPI, míg egy HBCC-hez hasonló megoldást nekik nem nehéz összehozni.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#39071
Abu85
HÁZIGAZDA
zovifapp111
#39069
Abu85
HÁZIGAZDA
válasz
zovifapp111
#39069
üzenetére
Az AMD tud ugyanúgy platformot kínálni, mint az Intel. Az IEDM-en felvázolták már ezt, hogy miképp fog kinézni az egész: [link]
Az, hogy most kié lesz jobb? Ezek hosszabb távú tervek, leginkább 2021-2022 környéki. Nem tudja senki, hogy a következő generációs gyártási eljárásokra hogyan állnak át a cégek. Rövidtávon biztos előnyben vannak a 7 nm-rel, de ez maximum 2021-ig dönti el a versenyt. Az Intelnek is lesz 7 nm-je, már arra koncentrálják az erőforrást, az AMD-nek is át kell majd állnia 5 nm-re, de vannak olyan pletykák, hogy ki akarják hagyni, és rögtön 3 nm-re ugranának, az meg nem veszélytelen, mert ott már GAAFET van, szóval sok a kérdés.
Az biztos, hogy az Ice Lake a jelenlegi adatok alapján nem túl veszélyes. Az AMD 3 TFLOPS-os rendszerchipet csinál, míg az Ice Lake az 1 TFLOPS-ot lép csak át. A Gen11-nél az a kérdés, hogy az 1 TFLOPS hogy jön össze, mert az Intel IGP-k dizájnban beragadtak egy igen régi szintre, vagyis 4+4 co-issue kell a kihasználásukhoz. Erre tudsz jól fordítani egy elavult leképezőt használó programnál, de egy újnál szinte lehetetlen, és akkor az 1 TFLOPS-ból rögtön 0,5 TFLOPS lesz.
A Gen12-es architektúra már érdekesebb, de az ellen a Navi jön. Hosszabb távon pedig a GPU-k nem így fognak ám kinézni, mert szükség lesz a dinamikus regiszterallokálásra, vagyis nagy áttervezések jönnek hamarosan. A jó ég tudja, hogy azt ki csinálja meg a legjobban. Az Intelnek és az AMD-nek a CPU-s üzletágból biztos sok tapasztalata van ebben, de CPU-t tervezni azért más.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 xEon1337
#39072
üzenetére
xEon1337
#39072
üzenetére
Nekik a kezükre játszik a Microsoft, tehát ARM-mal is mehetnek a piacért, ahogy a Qualcomm teszi. Csak azt kell megvárni, hogy a Microsoft kilője a Win32-t teljesen, vagy átköltöztessék a futtatást az Azure-ba.
(#39073) Petykemano: Nem nagyon érdekli az ARM a szerverpiac szereplőit. Lehet, hogy később érdekelni fogja, de egyelőre nem sok jel mutatkozik erre.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 tom_tol
#39075
üzenetére
tom_tol
#39075
üzenetére
Csak úgy tudnak részesedést szerezni, ha árút kapcsolnak. Ennyi az egész. Vagy így csinálják, vagy nem éri meg ebbe invesztálni.
(#39076) Zsébernardo: Nem a TDP a gond. Azzal, hogy a VGA-piac elvesztette a bányát, kapásból egy iszonyatosan durvát drágult. Ahogy elvesztik az OEM-eket, az egész luxusszintre fog kényszerülni. Innentől kezdve a TDP mindegy lesz, mert a VGA-k vételára egészen új szintekre megy majd fel. Oda az Intel is tervezni fog VGA-t, mert naná, hogy megéri 1000-2000 dolláros szintet kiszolgálni, de ettől a tömegpiac nem fogja tudni megfizetni.
Láthatod most is, hogy az AMD sem akar itt versenyezni. Szépen beárazták a Radeon VII-et a 2080-ra. Nekik ez így nagyon jó, és az új generáció sem lesz ám olcsóbb, sőt. A 7 nm-es node az drágább, szóval felfelé fognak menni az árak. Egy területen tudod ezt megfogni, ha a tokozásba rakod a CPU mellé a GPU-t. Ilyenkor a CPU-n meglévő, egyébként jellemzően bődületesen nagy profit elég, és a GPU-t adhatod előállítási költségen.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
atok666
#39080
üzenetére
Az Intelnek ~70% a GPU-piaci részesedése, és ez nagyrészt abból van, mert az OEM-ek ezt rakják a gépekbe. Szerinted most érdekli őket, hogy ez a felhasználóknak jó-e? Másrészt a felhasználókat érdekli, hogy van jobb? Az a helyzet, hogy a piacnak a jelentős része nem igazán tudja, hogy az Intelt, az NV-t és az AMD-t eszik vagy isszák-e.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
tom_tol
#39083
üzenetére
Most nem igazán fizettetik ki az IGP-t. Nézd meg a Ryzen 5 2400G-t. Annak az ára lényegében a processzor teljesítményéhez van szabva. Az IGP gyakorlatilag grátisz, jó nyilván nem, de effektíve nem kerül semmibe, mert hasonló teljesítményű négymagos csak Ryzen CPU-t is hasonló áron vehetsz.
Na most a dGPU proci mellé tokozásával már kifizettetik majd a dGPU-t. Az OEM vagy kéri a csomagot, vagy nem tud venni semmit. És akkor ha a dGPU ~200-300 dolláros árát felszámolják, akkor egészen más kérdés már az OEM részéről is, hogy vegyen-e mellé még ~200-300 dollárért egy hasonló teljesítményű VGA-t. Ez valóban nem a csúcskategória lesz, hanem a középszint, de ha Jon Peddie jelentése alapján a piac ~96%-a 300 dollár alatti GPU-t vásárol. Ha innen kirakod a VGA-kat, akkor azok luxusszintre esnek, hiszen annyira kiszeded alóluk a piacot, hogy nem lesz értelme középkategóriás VGA-kat csinálni, vagyis a generációváltások költségeit a high-endben kell kitermelni. Ezt csak úgy lehet, ha annyira megdrágítod a VGA-kat, hogy az a ~3-4%-nyi extrém igényekkel rendelkező user ki tudja fizetni a fejlesztéseket. Ezért is olyan magabiztos az Intel, hogy nagy részesedésre fognak majd szert tenni. Hát persze, ha nem hagynak az OEM-eknek választási lehetőséget, akkor ez nyilván nem nehéz. Persze lehet jönni azzal, hogy így is rendelhetnek VGA-t az OEM-ek, mert nem tart pisztolyt az Intel a fejükhöz, de valójában igen, árazópisztollyal segítik nekik a "jó" döntések meghozatalát.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
#00137984
#39086
üzenetére
A TDP azért nem igazán kritikus gond, mert korlátozott a hardver teljesítményének kihasználhatósága. A következő lépésben az új generációs EPYC 64 magot fog kínálni 180 watton belül. Ebből ugye nyilván nem csak a mag fogyaszt, hanem a körítés is, de jelenleg ott tart a dolog, hogy a Zen 2 lazán működik 2-5 wattos magszintű fogyasztással, függően az órajeltől. Egy PC-be pedig eléggé felesleges 16-nál többet építeni, tehát egy 3,5 GHz hozható vele 65 watton belül. Egy 8-magos verzió 35 watton is játszva megoldható, és akkor a következő generációs GPU-k sem olyanok, mint régebben, egyre több dolgot átvesznek az ultramobil szintről, és ezeket igen erősen fejlesztik is. Jó persze az AMD, az NV és az Intel azért annyi ideje ezzel nem foglalkozik, mint egy Imagination mondjuk, tehát hatékonyságban le vannak maradva, de ez csak azt jelenti, hogy sok tartalék van még, amit ki lehet használni. És akkor ott a memória, amiből lehet menni HBM-re, ami mérföldekkel takarékosabb, mint a hagyományos megoldás. Az Intel és az NV előtt még ott az AVFS. Az AMD ezt már használja, de nyilván ez is fejleszthető. Szóval a TDP most jelenleg az egyik legkisebb gond. A legnagyobb probléma aktuálisan a költség, ugyanis ahhoz, hogy az új gyártástechnológiák alapjait a gyártók ki tudják fejleszteni, gyárakat kell építeniük. Egyre többet, ez viszont egyre nagyobb költség, a szükséges berendezések sem olcsók, főleg az EUV, aminél a hatékonyság elég rossz, emiatt hatalmas hőt termel, ami miatt a gyár hűtésigénye egészen extrém pénzmennyiségbe kerül. Mindezt úgy biztosítják a bérgyártók, hogy az új node-okon a waferek nem csak drágák, hanem kurva drágák, vagyis hiába mész egyre kisebb csíkszélre, hiába csökken a lapkaméret, a gyártási költség egyre csak növekszik. Ilyen anyagi feltételek mellett nem biztosítható a Moore-törvény hagyományos módszerekkel történő alkalmazása, vagyis új lehetőségeket kell találni az előrelépésre.
Az Intelnél a Sunny Cove is 2-3 wattos szinten működik. 4-5 watt azért nincs, mert nem igazán stabil a mostani stepping 3 GHz felett, de ha ezt megoldják, akkor valószínűleg 4-5 watton belül a 4 GHz elérhető itt is.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
#00137984
#39088
üzenetére
Az órajel önmagában ma már nem sokat ér. A mai motorok az explicit API-kkal explicit párhuzamosan generálják a parancsokat. Tehát az órajel és a magok száma együtt számít.
A Raytracing árnyékok lényegében csak a memória-sávszélességtől függnek. Ugye itt az a buktató, hogy a raszterizációval ellentétben a memóriaelérések sugárkövetésnél eléggé véletlenszerűek, vagyis nem lehet rá optimálisan építeni a gyorsítótárakkal, miközben azért a raszerizálásnál azért viszonylag jellemző, hogy a lokalitási elv érvényesül. A Raytracing árnyékoknál különösen a sávszélesség a döntő fontosságú, hiszen nincs árnyalási munka, ami a többi effektnél inkább meghatározza a teljesítményt.
A játékok sebessége nagyban függ a leképezőtől. A motorok régóta olyan megoldások felé mennek, amelyek jelentősen javítják az árnyalás hatékonyságát. A tiled light tree, illetve a texel shading lesz a vezető irányzat a következő generációban, amelyek lényegesen gyorsabbak a mai, sokszor light culling nélkül deferred shadinghez képest.
Az API csak egy interfész, amivel elérhetsz a hardverhez. De maga az API nem igazán határozza meg a leképeződ munkáját.
A mai motorok egészen extrém szinteken skálázódnak. A mag igazából már nem probléma. Ez addig volt gond, amik a legacy API-k feldolgozási modellje egy száltól tette függővé a leképezést. De pont emiatt hoztuk az explicit API-kat. Dobáljuk is a magokat a procikba, mert innentől kezdve ez többet fog írni, mint az órajel.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 korcsi
#39093
üzenetére
korcsi
#39093
üzenetére
Attól függ, hogy milyen dedikált. Egy GeForce MX200 sorozat igen olcsó, miközben gyorsabb az Intel IGP-jénél. De érdekes lesz majd látni a Ryzen Mobile 3000-et. Ott már az AMD rárakja a pénzt azt a 30-50 dollárt IGP-re, és így például a Lenovo nem rak mellé dedikált GPU-t, mert most már fizetni kell az IGP után is.
Nagyban meghatározza az OEM-ek döntéseit, ha az IGP-s prociknál az ár úgy van szabva, hogy az IGP ajándék legyen, vagy úgy, hogy azt a cég felszámítja. Utóbbi esetben nem igazán van lehetőség dedikált GPU-ra, még akkor sem ha befér, mert a Ryzen Mobile 3000 alaplapja kb. akkora, mint az Intel Coffee Lake U-s modelleké. És az is lényeges, hogy az AMD szokott csomagot kínálni, alig 20 dollár a legkisebb Radeon, ha valaki vesz egy mobil Ryzent, tehát még ez a 20 dollár sem éri már meg a gyártóknak, ha az IGP-ért az AMD azt mondja, hogy most már fizetni kell. Képzeld mennyire sikítva tenyerelnek a NEIN gombra, ha nem 20, hanem 200-300 dolláros extra kiadásról lesz szó.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 pengwin
#39096
üzenetére
pengwin
#39096
üzenetére
Nem olyan nehéz ez. Kínálnak valamit x pénzért, de ami kellene a partnereknek azt nem kínálják fel kevesebb pénzért. Antikompetitív? Az hát. Hogyan tudsz védekezni ellene? Maximum nem veszed meg a terméket, de az sem megoldás, mert valamit árulni kell, tehát belekényszerítenek és kész.
El tudják látni a piacot. Ha az eladás garantált, már csak amiatt is, mert az OEM bele van kényszerítve a megvásárlásába, akkor nyilván nem gond többet gyártani.
A második foglalat az nem jó. Azzal az a gond, hogy drága lenne. Senki sem akar drága megoldást, mert azon kevés lenne a haszon. Sokkal célszerűbb oda berakni a CPU mellé a tokozásba. Ehhez már minden technológia adott. Régen nyilván nehézkes volt, mert maga a tervezés nem chipletek szintjén zajlott, de ma már átálltak. Az AMD mindenképpen, és az Intel is át fog, mert sokkal hatékonyabb ez a megközelítés.
(#39098) atok666: Nézd meg azokat a motorokat, amelyek erre vannak kitalálva. Például a Nitrous. Ott nagyon szépen skálázódik a sok mag. Ezért is lépdel az AMD és az Intel is inkább a magok növelésének az irányába. Idén az AMD-nél 12 mag lesz a mainstream maximum, bár nyilván csinálhatnának 16 magot is, de nem fognak, mert a 12 mag is túl sok lesz a 10-magos Comet Lake-nek. Az viszont tisztán látszik, hogy merre mennek. Nem az órajelet hajkurásszák, hanem a magokat öntik bele a lapkákba, mert összességében sokkal hatékonyabb, és természetesen tudják azt, hogy az új motorverziók már úgy vannak megírva, hogy ezeket a magokat ki is használják. Ha nem így lenne, akkor nem ilyen hardverek jönnének, de magát az alapproblémát a Microsoft és a Khronos kezelte egy-egy új API-val.
(#39102) Zsébernardo: Azt számítsd bele, hogy se az Intel, se az AMD nem az aktuális játékokra készíti az idei csúcsprocesszorát. A 10-magos Comet Lake, illetve a 12-magos Matisse a 2019-es címekre jön. Azokra a címekre, ahol egyébként nem egy el fogja hagyni a DX11-et, így meg lehet válni a legacy feldolgozási modellektől. De egyébként lehet, hogy lesz 16-magos, mert az id tech 7 azt mutatja, hogy skálázódna rá, csak az AMD nem annyira rajong az ötletért, mert a Threadripperek piacát enné a cucc, és az Intelnek úgy sincs a 12-magosra sem válasza. De persze a Bethesda nagy partner, nyilván van némi beleszólásuk, hogy csinálnak-e nekik egy külön szupererős mainstream procit. Ha nagyon nyalnak, akkor talán megteszik.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
atok666
#39106
üzenetére
A mai rendszereknél a magszám növelésével nem igazán kell hozzányúlni az órajelhez. Maga a hardver elintézi ezt, ha nem tudja tartani az adott fogyasztási kereten belül. Egyszerűen fel van rá készítve, hogy a megfelelő szintre vegye vissza, ha az adott munkafolyamat ezt megkívánja. Például bizonyos AVX módoknál még a közölt alapórajel alá is visszamehetnek a procik. Nem probléma, mert stabilitási gondokat nem okoz, tehát nyugodtan meg lehet adni a specifikációra a magas órajeleket, a hardver majd eldönti, hogy mit állít be magának.
Simán meg tud verni egy 12-magos egy hatmagost egy NUMA-aware motorban, amely nem tartalmaz legacy pathot az öreg API-kra. Ilyen motorok készülnek most. Nyilván a fejlesztők is tudják, hogy az órajelben már nem bízhatnak. Ezt az Intel is folyamatosan kommunikálja nekik. Már csak azért is, mert a 10 nm-es Ice Lake mintája 3 GHz fölött nem stabil. Ezen persze még lehet növelni, de a 10 nm-es node-ot nem a magas órajelre tervezték, hanem egy rendkívül low-power optimalizált megoldás annak érdekében, hogy annyi magot lehessen a lapkába rakni, amennyi van a dinnyében. Ezért sem lesz Ice Lake asztali szinten egy jó darabig, de egyébként készül oda egy 20-magos verzió, csak egyelőre jobb a Comet Lake, viszont 2020-ban már jöhet a sok mag, mert bőven skálázódnak majd az új játékok.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Samsung Low Cost HBM. Az 200 GB/s-ot tud nagyjából, per stack ugye. Ez nem szabványos, sokban különbözik a JEDEC HBM-től, például csak 512 bites a busz, nincs pufferlapka, nincs ECC, más a struktúra, illetve sokkal kellemesebbek az interposerre vonatkozó igények. A Samsung-féle Low Cost HBM előnye, hogy érezhetően olcsóbb a JEDEC HBM-nél, viszont hátrány, hogy többet fogyaszt. Persze a HBM szintjén mérve, tehát ha még 50%-kal nő is a fogyasztás, az is eléggé lófütyi kategória.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 Yutani
#39130
üzenetére
Yutani
#39130
üzenetére
2-3 watt körül van. Órajeltől függően.
(#39131) Petykemano: Csak az eDRAM az Intelnél sem volt több dísznél. Xbox One-ba jó. Oda rátervezik a játékot. PC-be nem az, maximum csak dísznek jó.
A Low Cost HBM elsődlegesen azoknak jó, akiket a HBM bonyolultsága tartott vissza az implementációtól. Azért 1024 bites TSV-t stackenként tervezni nem egyszerű ám. 512 bitet sokkal könnyebb.
Az AMD-nek a tervezés szempontjából valószínűleg mindegy, mert nekik azért elég nagy itt a tapasztalatuk, viszont egy APU-nál a hely azért korlátozott, így más tényezőket is meg kell vizsgálni. Például a Si-less interposert opcióként.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#39134
Abu85
HÁZIGAZDA
Petykemano
#39133
Abu85
HÁZIGAZDA
válasz
Petykemano
#39133
üzenetére
Az Intelnél az eDRAM leginkább sehogy sem működik. Nagyon régi leképezőknél ad előnyt, de az újabb GPGPU-s cullingot alkalmazóknál már semmi haszna. Annyira sok a modern leképezőknél a feldolgozandó adatmennyiség, hogy gyakorlatilag nem tudsz építeni a nagyon aprócska tárkapacitásra. Nem véletlen, hogy az Intel is Counter Strike-kal demonstrálta és nem Battlefielddel.
Az Xbox One-ban az ESRAM azért működhet, mert közvetlen elérése van rá a fejlesztőknek, tehát például tudnak olyannal trükközni, hogy a back buffer color és depth targetjeit használod az egyes effektek számításánál. Viszont ha nem trükköznek, akkor ugyanúgy nem ér semmit. PC-n meg erre nincs semmi, az Intel eDRAM egy mezei L4 cache, így a hatásfoka fényévekkel van a közvetlen elérhetőséget biztosító Xbox One ESRAM mögött, már ha utóbbit használod ugye. Szimpla cache-ként ez sem valami hasznos. Az Xbox One X-ből ügye ezt ki is vették, illetve a rendszermemóriából emulálják ha szükség van rá. Egyszerűen ezek a kicsi, de gyors memóriás konfigurációk a Counter Strike-hoz jók ugyan, de a mai motorok nem így működnek.A Samsung mondta a Low Cost HBM-re, hogy mindenképpen olcsóbb a JEDEC HBM-jüknél. Bár azt nem írták, hogy mennyivel. 0.X-et írtak.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
A jövőben ezek a gyártók nem tudnak mit kezdeni egymás hardvereivel. Megmarad ugyan a PCI Express, de ki lesz egészítve. Az AMD-nél PCI Express with CCIX lesz. A Rome platform már támogatja, és innen nyilván hozhatod asztaliba is, viszont marhára nem lehet mit kezdeni a CCIX képességével, ha nem CCIX hardvert raksz bele. Az Intel azért nem lépett be a CCIX-be, mert zárt kiegészítést hoznak a PCI Express-hez. Tehát amit veszel majd hardvert az Inteltől GPU-ban, az sokkal többet fog tudni, ha az Intel CPU-ja mellé rakod, mintha egy AMD GPU-t raknál a gépbe. Ezzel szemben az AMD GPU-ja sokkal többet fog tudni, ha AMD CPU mellé rakod, mert működni fog a CCIX képesség, szemben az Intel GPU-jával, ami saját UPI kiegészítést használ a memóriakoherencia problémájára.
Ha tehát egy cég vásárolni akart, az már nem tud, mert az AMD az IF és CCIX, az Intel a UPI, míg az NVIDIA az NVLINK protokollt dolgozta ki a memóriakoherencia kezelésére. És persze a PCI Express mint alap csatoló meglesz, de ha például egy CCIX-es hardvert nem CCIX-es PCI Express vezérlőhöz raksz, akkor a CCIX képesség nem fog működni. És ugyanez van más protokollokkal is. A hardver működni fog gyártói keveréssel, de a tudás egy részét bukod.
Annyira előrehaladottak már ezek a fejlesztések a gyártóknál, hogy ha hirtelen megvennék a másik divízióját, akkor négy évet buknának, mert át kellene tervezni a hardvereket. Vagy a CPU-kat vagy a GPU-kat.Egyébként a CCIX ugyan szabvány, tehát mindenki mehetne erre, de az Intel és az NVIDIA különcködik. Ők úgy érzik, hogy elég erősek ahhoz, hogy saját zárt rendszerrel arra kényszerítsék a vásárlóikat, hogy az Intelnél a CPU-khoz Intel GPU-t vegyél, míg az NVIDIA-nál a GPU-khoz, NVLINK-et támogató CPU-t vegyél.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.



![;]](http://cdn.rios.hu/dl/s/v1.gif)

























Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
Megbízhatatlan oldalakat ahol nem mérnek (pl gamegpu) ne linkeljetek.
