Új hozzászólás Aktív témák
-
#3734
 Petykemano
veterán
Cathulhu
#3732
Petykemano
veterán
Cathulhu
#3732
Petykemano
veterán
válasz
 Cathulhu
#3732
üzenetére
Cathulhu
#3732
üzenetére
két megjegyzés:
1) Természetesen az Arm "lassulása" is érezhető. Legalábbis az utolsó, 5nm-re és nyilván legkorábban jövőre tervezett A78 már nem hozott nagymértékű IPC emeledést. Helyette az X1 hozott, ami az A78-hoz képest viszont nagyobb és energiaigényesebb lesz.2)
A konkrét példák viszont előttünk vannak
az amazon Graviton 2-je A76/Neoverse N1 alapú, az ARM-ról ilyen már tavaly kapható volt. És versenyképes teljesítményt nyújt. (Az összehasonlítás persze még Naples-szel van)
És elvileg lényegesen kevesebbet fogyaszt.Ott van az Apple nagy magja, ami jó, egy kicsit más tészta, mint a szerver, de azonos órajelen 70%-kal jobb eredményt ad specint-ben, mint az intel.
Vannak, amik slide-okon léteznek:
A Marvell bejelentette a 60c/240t ThunderX3, állítólag idén év végén elérhető lesz ()
És a Ampere is bemutatta már a 80c Altra családot szintén év végi elérhetőséget ígérveJó, ezek persze egyrészt majd a Milannal kell versenyezzenek. Abban igazad van, hogy a ThunderX3 96 magja tűnt volna igazán veszélyesnek, de az majd csak 2021-ben debütál.
És akkor ott van a Nuvia, ami szintén egy ígéret, ezért azt most hagyjuk is.
Arról van szó, hogy a Naples => Rome => Milan váltások generációs hozadéka kisebbnek tűnik, mint az Arm-os konkurensek utolsó néhány generációja és az ismert vagy még nem ismert terveik ugyanezekből az időkből.
Charlie (S|A) viszont ezt írja: AMD is going to Celeron Intel’s Xeon margins
Ez viszont azt sejteti, hogy többet kellene hoznia a Milannak, mint 10-20%Találgatunk, aztán majd úgyis kiderül..
-
#3736
Petykemano
veterán
Cathulhu
#3735
Petykemano
veterán
válasz
Cathulhu
#3735
üzenetére
Azzal egyetértek, hogy önmagában az ISA nem szentgrál.
Olvastam egy olyat is, hogy az x86 és arm IPC nem összehasonlítható, mivel az arm jobban Risc, ezért érthető módon több egyszerűbb.utasítást.tud egy órajelciklus alatt végrehajtani.
Ott látok különbséget, amire és ahogy használják. Ebben talán valóban nem annyira van szerepe az isának, lehet, hogy ha megnyitnák az X86-ot, ugyanezek a szereplők most abban terveznének.
Mire is gondolok?
Abu el szokta mondani, hogy a magas frekvencia elérése tranzisztorokba kerül.
Ebből a szempontból az, hogy az amd ugyanazt a designt,.sőt lapkát használja desktopra és szerverbe, lehet,.hogy hátrányt jelent. Feltételezem, hogy ha egy. Matisse ccd nem kéne 5ghz körüli értéket elérjen, kisebb is lehetne. Nem tudom, ez nincs-e összefüggésben azzal is, hogy az arm szerver üzemi frekvencián alacsonyabb fogyasztással kecsegtet.Találgatunk, aztán majd úgyis kiderül..
-
#3747
Petykemano
veterán
Cathulhu
#3744
Petykemano
veterán
válasz
Cathulhu
#3744
üzenetére
Azt mondod fake?
Én csak arra utaltam, hogy megjelent. Ha tesztelik, néhány hónap múlva piacra kerülhet.
Az "ryzen 5k" következtetés:
Felreppent a pletyka, hogy csak a Renoir lesz 4000, a Vermeer (vagy a tök tudja mi fog megjelenni zen3 magokkal hamarosan) viszont már 5000 lesz. Én azt mondtam, ennek csak akkor látnám értelmét, ha annyira közel van a Cezanne, hogy szinte egyszerre jelenik meg a desktop procikkal. Az lehet tényleg zavaró lenne, ha az ősz folyamán megjelenne a desktop ryzen 4000, és röviddel utána (tehát nem 2021Q1-ben) a Cezanne Ryzen 5000 néven.Találgatunk, aztán majd úgyis kiderül..
-
#3750
Petykemano
veterán
Cathulhu
#3749
Petykemano
veterán
válasz
Cathulhu
#3749
üzenetére
Miért? A cikkben van racionális indoklás:
ST-ben segít az egy mag számára elérhető dupla L3$. Ebből MT-ben majdhogynem semmilyen előnyt nem jelent ha szálfüggetlen programban teszteltek.
És valószínűleg segíthet az is, hogy magonkénti feszültségszabályozás jöhet. Viszont az összes mag terhelése esetén valószínűleg ez se jelent semmit.Ezek az adatok a Milanra vonatkoznak. Desktopon lehet, tudtak alacsony magszámon turbó frekvenciát is növelni.
Az én várakozásom az általam ismert információk alapján az, hogy a zen3-nak nagyobb lesz az impactja a játékokban, mint a Datacenterben.
[ Szerkesztve ]
Találgatunk, aztán majd úgyis kiderül..
-

S_x96x_S
őstag
válasz
Cathulhu
#3876
üzenetére
> uhhh, egyre pofatlanabb claimekkel jonnek mindenfele bizonyitek nelkul,
persze az apróbetűs részben van a titok ..
A Ryzen 4700U -t benchmarkolták.
https://nuviainc.com/blog/performancedeliveredanewway
amúgy a Dell is a befektetőjük .. https://nuviainc.com/investors"The data shows that both AMD and Intel demonstrate higher peak performance than the ARM CPU but at much higher power. The Ice Lake and Zen 2 curves are neck-in-neck with no clear leader. That higher power can be anywhere between 6x to 11x the power of the ARM core comparing peak to peak operating points; however, the X86 solutions are only 40-50% faster. The design philosophies are also clearly contrasted. The x86 CPU cores are designed to run at very high operating points, and the perf/W curve clearly enters a flatline area where every last bit of performance is extracted, at the expense of disproportionately higher power consumption. In stark contrast, the ARM CPU cores have very steep curves.
Once the Apple A13 and A12Z curves are added, it becomes clear that a well-designed custom ARM CPU can achieve higher performance than even the best x86 designs and at a much lower power. The combination of high performance at low power is the critical characteristic required to achieve leadership in any SoC that is power constrained."
a zen2-nek ( zöld) és a sunnyCove -nak (kék)
mintha hasonló görbéje lenne.A Nuvia arra spekulálhat, hogy egy adott Watt keretbe - több magot és teljesítményt tud belesüríteni. Persze a többi ARM-es chiparchitektúra is erre megy ..
"When measured against current products available in-market in the 1W-4.5W power envelope (per core), the Phoenix CPU core performs up to 2X faster than the competition."
persze a skálázás és valóság már más ..

Amit tudunk, hogy az ARM hosszú távon veszélyes ..
A NUVIA csak ráblöfföl egy picit erre ..
Aztán majd meglátjuk.
( A verseny általában jó; és remélhetőleg az Intelből és az AMD-ből is a legjobbat hozza ki .. )Mottó: "A verseny jó!"
-
#4079
Petykemano
veterán
Cathulhu
#4078
Petykemano
veterán
válasz
Cathulhu
#4078
üzenetére
De akkor a Bulldozer érában hogy boldogult az Intel? Mindenkinek az 5Ghz-es bulldozert (piledriver) kellett volna venni, hiszen az 5Ghz, nem suta 3.5 meg 3.7Ghz-ek. Veszítenie kellett volna az 5Ghz-től megbabonázott vásárlók miatt.
Azonban mégis mindenki tudta, hogy
AMD => szar magok + 5Ghz => kazán
Intel => elképesztően hatékony magok => teljesítmény, energiahatékonyság
De mondok mást:
Miért nem próbálják meg azt, ami az ARM X1/A78-ban jött, hogy hát van egy alap design, amit még fel lehet turbózni itt-ott?Az intelnek sikerült a Turbo Boost 3 technológiával azt megoldani, hogy minden magról tudja a a rendszer (a szoftver), hogy meddig tud turbózni és a legmagasabb turbóra képes magra osztja a legdurvább ST feladatokat.
"Intel Turbo Boost Max Technology 3.0 is a feature used by some Intel CPUs to improve performance of lightly- or single-threaded applications by pushing those workloads to the processor’s two favored (or fastest) cores. Using both hardware and software, Intel claims Turbo Boost Max Technology 3.0 delivers “more than 15% better single-thread performance.” "
Az AMD eddig csak az L3$ méretével játszott
De miért nem csinálja azt az AMD, hogy minden CCX-be betesz +1 magot, ami mondjuk 32 helyett 64KB L1$, 512KB helyett 2MB L2$ (csak hogy ne szaladjunk egyből messzira) és most hogy már a CCX közös L3$-t használ, akár ezt is rá lehet csatlakoztatni a 32MB megosztott L3$-re.
Valamit csak számít. +15-20% IPC úgy, hogy mondjuk annak az egy szerencsétlen magnak a fogyasztás 2x nagyobb és a mag mérete is 2x nagyobb. Nagyjából ezt látjuk az A78/X1 esetében is.Hiába hogy a szervereknél több a MT workload, Amdahl törvénye ott is él, vannak szűk keresztmetszetek ott is, amit ST erővel lehet legyőzni.
[ Szerkesztve ]
Találgatunk, aztán majd úgyis kiderül..
-

Yutani
nagyúr
válasz
Cathulhu
#4080
üzenetére
Teljesen igaz. Még ha sz@r is volt a Netburst (az volt), akkor is azt vették a népek (és főképp az OEM-ek), mert Intel (meg az egészséges versenyt lehetetlenné tévő tisztességtelen ajánlataik).
Ugyanakkor az Bulldozer azt adta, amit az áráért el lehetett tőle várni, mégis szar volt. Gyengébb volt egy 8 magos Dózer egy i7-nél? Igen. Sokkal olcsóbb is volt? Igen. Akkor meg? Ja persze, a győztesnek könnyű szurkolni és leszólni a vesztésre állót.
Most meg? Van AMD oldalon régóta jó ajánlat, de sokan hallani sem akarnak róla, csak az Intel, bármi áron!

Szerk: Áttettem OFF-ba.
[ Szerkesztve ]
#tarcsad
-

HSM
félisten
válasz
Cathulhu
#4123
üzenetére
Persze, ez abból jön, hogy Intelnél minden magnak tudnia kell az adott esetben igen magas turbó órajelet, AMD-n nem. Erre akartam rávilágítani. Persze, Intelen amikor minden magot jól megterhelnek a maximális turbón, akkor fog fogyasztani, de ez nehezen összehasonlítható a másik oldal "kevésbé szigorú" turbójával.
Egyébként képes rá a 3600-asom, kb. 1,23V-on használom több hónapja allcore 4,2Ghz-en, és nincs vele stabilitási probléma. Ehhez képest gyárilag 1,35V-ok magasságában járt, néha 1,4V felett is, órajelben pedig inkább 4Ghz körül, 4,2-t szinte sosem láttam. Ezért is állt tőle égnek a hajam, sok feszültséggel, melegedéssel és fogyasztással hozott így rosszabb teljesítményt, mint minden magot fixen beállítva 4,2Ghz-re és finoman beállítva hozzá a megfelelő üzemi feszültséget....

-
-
#4243
Petykemano
veterán
Cathulhu
#4242
Petykemano
veterán
válasz
Cathulhu
#4242
üzenetére
hát igen, csak azért a Xilinx tulajdonosainak (bárki is volt) el kellett fogadnia az AMD részvényt fizetségként - nyilván abban a reményben tették ezt, hogy az AMD részvény
- magasabb tőkejövedelmet biztosít (függetlenül attól, hogy azt osztalék vagy részvényérték formájában teszi)Igazából azt nem tudom, hogy miért kellett felvásárolni.
- olcsóbb lesz így a wafer?
- ha feltételezzük, hogy a biznissz megy tovább, akkor az egy pontra fókuszálható fejlesztési kapacitás ettől nem lesz több, mert más üzletben utaztak együtt.
- A szinergia magasabb lesz, mintha külön cégként teszik össze amijük van?
- ellenséges kivásárlás megakadályozása?Kiváncsi vagyok, mire fogják használni az FPGA-kat, amihez a felvásárlás szükséges vagy érdemes volt.
Találgatunk, aztán majd úgyis kiderül..
-
#4317
Petykemano
veterán
Cathulhu
#4316
Petykemano
veterán
válasz
Cathulhu
#4316
üzenetére
Lehet, hogy igazad.van, ám abu a nyáron még arról cikkezett, hogy 5 és 3nm-en is dupláz az AMD. De a roadmapek persze változhatnak. A warhol beékelődése például nehezen illeszkedik abba, amit 14-15 hónapos kiadási ciklusok alapján várunk.
Amúgy persze mind a desktop, mind a szerver magszámmal kapcsolatban igazad van, utóbbinál cikk is született arról, hogy inkább az alacsonyabb magszámú termékekre van nagyobb kereslet. A SzerverMérnök szerint azért, mert a cégek a biztonsági parák miatt átálltak 7 helyett 3 éves csereciklusra. 3 évre meg nem éri meg drága, magas magszámú procit venni. Az alacsonyabb magszámú termékeken viszont vékonyabb a marzs, ezért csökkent az Intel marzsa. És ugyanez miatt jön az abu által emlegetett kicsi Epyc.
És ha ez igaz,.akkor valóban lehet vonzóbb egy 24 magos, ami jövőre 15 helyett 25%-kal nagyobb IPCt hoz, mint ha 48 magos lenne, amire a licenc is drágább.
Hát majd meglássuk.
Találgatunk, aztán majd úgyis kiderül..
-

BiP
nagyúr
válasz
Cathulhu
#4316
üzenetére
Nem ismerem az AMD erre vonatkozó terveit, de még csak most ugrottak a CCX-enkénti 4-ről 8magra, szóval talán ez jó ideig megmarad, ebből bármit össze lehet legózni, ami desktopra nagyon sokáig elég lesz. Emellett az IPC is ugrott ~20%-ot, szóval ilyen téren sincs gond.
Az 5950x 16mag,32szál desktopra már tényleg olyan, hogy nincs játék, vagy hobbi otthoni felhasználás aminek több kell, talán nem lépnek feljebb egy ideig. Már így is olyan szintet állítottak be ezzel, ami pár éve még HEDT vonalon sem volt. -

paprobert
senior tag
válasz
Cathulhu
#4325
üzenetére
Az, hogy ma hogy terhelnek a szoftverek, azt a Jaguar CPU szabta meg.
Ha van erőforrás, az lesz költve, ne aggódj. Egészen 30 fps target-ig, mert alatta refundolnak az emberek.
GPU limites a next-gen, valóban, de ez nem ok arra hogy ne írjanak CPU-heavy kódot.
[ Szerkesztve ]
640 KB mindenre elég. - Steve Jobs
-
paprobert
senior tag
válasz
Cathulhu
#4338
üzenetére
A multiplatform játékokat a Jaguar-limit figyelembe vételével tervezték meg eddig. Ezentúl ez egyre többször nem így lesz.
Vizsgáld meg a single- és multicore eredményeket a tesztelt CPU-knál, vesd össze az Athlon 5150-nel, akkor megérted miért futhatnak itt-ott jól a címek.
Nextgen-ben a Zen2 lesz a mérce, az lesz a 30 fps nagyon sok esetben. Call of Duty-ban, ahol a 60 a minimum mindig, ott rendben lesz a PC. Lassabb játékmenetű, 30 fps-re készült, CPU-heavy címeknél viszont esélytelen.
Most nem az alig észrevehető X360 - Jaguar átmenetről van szó, hanem egy közel 10 éves ugrás lesz technológiában.Lesz itt meglepődés, úgy gondolom.
#4339 TESCO-Zsömle
Na igen, de amikor 720p-ben is 30-60 fps között teljesít a géped, az onnantól egy kikerülhetetlen probléma.[ Szerkesztve ]
640 KB mindenre elég. - Steve Jobs
-
paprobert
senior tag
válasz
Cathulhu
#4344
üzenetére
#4332 -t olvasd el újra szerintem.
1. helyzet: A legelső játékok, úgy az első 1-2 évben biztos hogy csak az RDNA2-t használják ki teljesen. Azaz az általad is említett GPU limit lesz eleinte konzolon.
2. helyzet: Azonban ne légy naiv, + egykét év eltelik, és vegyes limit irányába fognak haladni a fejlesztők az érkező új motorokkal a konzolon.1. helyzet: RDNA2 a 30fps mérce-> már most van sokkal gyorsabb GPU PC-re, nem lesz túl nagy gond PC-n a grafikával. (a Jaguar szintet már bőven meghaladtuk.) Mindenki boldog.
2. helyzet: Zen2 CPU és RDNA2 GPU is 30fps mérce egyszerre-> gond lesz PC-n a processzorlimittel, hiába lenne erős GPU elérhető, 60 alatt marad az fps számláló, bármilyen GPU-t raksz mellé bármilyen felbontáson.[ Szerkesztve ]
640 KB mindenre elég. - Steve Jobs
-
paprobert
senior tag
-
#4350
Petykemano
veterán
Cathulhu
#4348
Petykemano
veterán
válasz
Cathulhu
#4348
üzenetére
A ps4 és ps4 pro cpuja 100-130gflops teljesítményt tudott.
Az AT mérései alapján az ps4 megjelenésekor már elterjedtnek mondhat 2500k is legalább másfélszer nagyobb cpu teljesítményt jelentett. Single threadben 2x is
[link]Tehát a ps4 megjelenésekor az elterjedt mainstream cpuk erősebbek voltak, mint a konzol CPU.
Ennek köszönhető az, hogy sok esetben egy mai 4/8 elegendő lehet egy játékra. És ennek köszönhető az is, hogy 8 teljes értékű magnál többet felvonultató CPU esetén nagyítóval kell keresni az előnyöket. Mert 7-8 mag a target.Én azt mondom, hogy 2-3 év múlva a 4/8, a 6/6 esetén biztosan és talán a mai 8/8 és 6/12 magos cpuk esetén is enyhén érezhető lesz, az a fajta lemaradás, amit ma a 2/4, 4/4 cpuknál tapasztalunk.
Azt senki nem mondja, hogy egy 8/16-os, későbbi generációs 8/8, 6/12 ne Lehetne elég a játékra,de ugyanolyan belépőszintnek fog minősülni, mint ma a 4/8.
Találgatunk, aztán majd úgyis kiderül..
-
-
#4393
Petykemano
veterán
Cathulhu
#4391
Petykemano
veterán
válasz
Cathulhu
#4391
üzenetére
Szerintem az ábra ellenére ez csak egy koncepció, amit bármelyik szinten be lehet vetni.
Azt nem tudom, hogy érdemes-e csak egy közbülső szinten bevetni? Csak L2 esetén, de L1és L3 esetén nem.De a koncepció azért érdekes, mert a késleltetés romlása elkerülhetetlen.
A zen esetén már az L2 esetén látható, hogy a második szelet 256KB késleltetése rosszabb. Ugyanez igaz a legtávolabbi L3 szeletre.A cache kapacitását növelni kell. Eldöntheted:
1) a cache méretét növeled? Ennek valószínűleg lineárishoz közeli lesz tranzisztor- és fogyasztásköltsége és minél nagyobb/távolabbi a cache szelet, annál inkább romlik a késleltetés.
2) beépítesz egy fixfunkciós tömörítő egységet. Ennek is lesz tranzisztorköltsége és fogyasztásköltsége is és bizonyosan rátesz valamekkora késleltetést is.Tehát mindenképpen lesz tranzisztorköltség, fogyasztás és késleltetés. Az a kérdés, hogy vajon melyik megoldással mennyi a nyereség és mennyi a költség?
Az L4$-ről:
Egyetértek. Ugyanakkor most elgondolkodtam.
A zen3 nagy újítása az, hogy 2db 4magos CCX-et egyesített 1db 8magos CCX-ben ezzel megduplázva az 1 mag számára elérhető L3$ méretét és eliminálva azt a kényszert, hogy 1 CCD-n belül elhelyezkedő CCX-ben levő magok az IOD-on, vagy leginkább a memórián keresztül legyenek kénytelenek adatot megosztani. Ez az elmélet.Egyébként az anandtechnek erre vonatkozóan voltak is mérései:
https://www.anandtech.com/show/16214/amd-zen-3-ryzen-deep-dive-review-5950x-5900x-5800x-and-5700x-tested/53950X vs 5950X
Nagyon szépen látszik, hogy már nem csak 4, hanem 8 mag között zöld a késleltetés.
De ami még érdekesebb, a zöld már nem 30ns-ot, hanem 17ns-on jelent két egy CCX-be tartozó mag között. Ez óriási előrelépés!És akkor a kérdés:
Rendben van, hogy ha ez az óriási előrelépést jelentene egy 6-8 magos generációváltás esetében. De Ha a játékokban tapasztalt intelhez képest gyengébb teljesítményt az inter-CCX kommunikáció okozta (ami ugye a 6-8 magos Vermeer lapkákon megszűnik), akkor miért nem tapasztaljuk ugyanezt a teljesítmény-regressziót az 5900X/5950X esetén, ahol továbbra is van CCX-CCX kommunikáció?Ha innen nézem, nem is biztos, hogy olyan sokmindent megoldana egy hatalmas L4$ az IO lapkán
Találgatunk, aztán majd úgyis kiderül..
-
-
S_x96x_S
őstag
válasz
Cathulhu
#4527
üzenetére
> Vennem kellene egy ilyet (dolgozni fokent),
> szerintetek majus fele kaphato lesz ertelmes aron?A CES után picivel többet tudunk ...
de elsőként amúgy is a játékos laptopok jönnek. a jó hír.. hogy már párat be is áraztak ..."Acer Nitro 5 with Ryzen 7 5800H and RTX 3080 for 1950 EUR"
https://videocardz.com/newz/acer-nitro-5-notebook-with-ryzen-7-5800h-and-geforce-rtx-3080-listed-for-1950-eur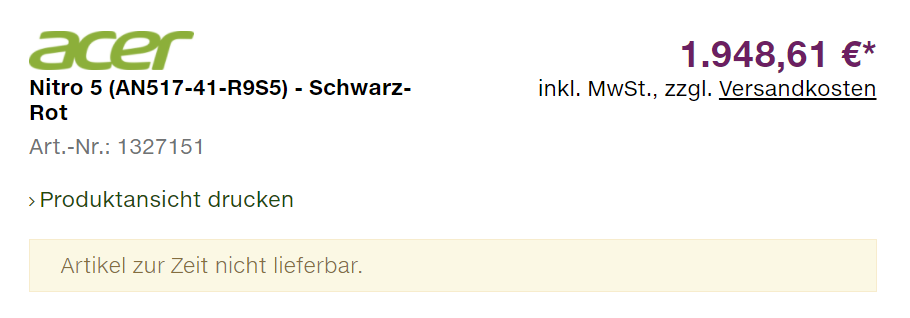
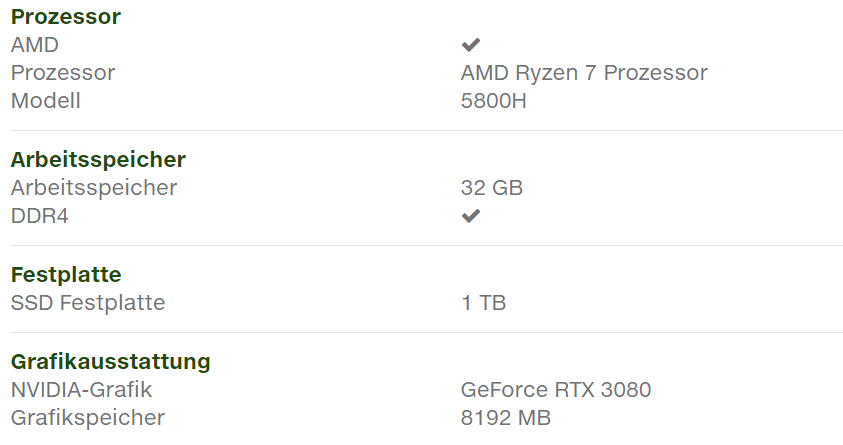
egy másik verzió
Acer Nitro 5 2020 ..
vagyis lesz olcsóbb GPU-val is.
Mottó: "A verseny jó!"
-
-
S_x96x_S
őstag
válasz
Cathulhu
#4552
üzenetére
> FPGA ... szerintem csak a szuperszamitogepek piacan lehet igazan impactja.
Én azért bízom benne, hogy a "jövőben" a szűk keresztmetszeteket
"nagyrészt" át lehet tolni az FPGA-s részre ...A xilinx ilyen példákat emleget:
- LZ4 Compression ( 2X sebesség a CPU -hoz képest )
- Haversine Distance (10x sebesség )
- Regex Overlay ( 18x sebesség )
- ...
De már egy egyszerű adatbázis gyorsítás ( PostgreSQL, REdis, Appache Arrow,... )
is sokat fantáziáját beindithatja,
https://www.xilinx.com/applications/data-center/database-data-analytics.htmlpersze a jövő a CPU + GPU + FPGA fúziója ...
szerintem

Mottó: "A verseny jó!"
-
válasz
Cathulhu
#4603
üzenetére
Játékban még léphetnek előre ph írás alapján, csak kell hozzá alacsonyabb csíkszélesség:
"A problémát az adja, hogy a mag dizájnját alapvetően 1,25 MB-os L2 cache-re tervezték, de ennyit a 14 nm-es node-on nem lehetett beépíteni, így kényszerűen be kellett érni az 512 kB-os kapacitással. Úgy tudjuk, hogy ennek csak a játékokban lehet valóban mérhető korlátozó hatása, de a mai, többszálú feldolgozásra tervezett címek esetében ez egészen minimális."solfilo
-
-
válasz
Cathulhu
#4607
üzenetére
Ennyi elég szerintem a célközönségnek, hogy ne akarjanak AMD-t venni. Meg hát látjuk, hogy fontos a játékos korona, AMD is erre hegyezte ki a bemutatót.
Meg amúgy is 8 mag vs 12, marketingből ötös, bár nincs odaírva, úgyhogy ezt mégse akarták kidomborítani.[ Szerkesztve ]
solfilo
-

TRitON
aktív tag
válasz
Cathulhu
#4603
üzenetére
"Ehhez meg Zen4-sem kell, egy Zen3 refresh eleg lesz es honnan fogjak majd tudni onnan tartani a lepest?"
Ez lesz a Warhol.
BTW, rendkívül kíváncsi lennék, hogy egy 5800X-szel szemben (1CCD, vagyis kisebb core to core késleltetés) mit megy ez a processzor, azonos magszámmal.Mi az? 3 lába van mégsem tranzisztor? - ??? - Traffipax...
-

Busterftw
veterán
válasz
Cathulhu
#4607
üzenetére
Csak kozben elkeszult a 10 superfin, ott talan mar megoldottak.
Az Intel szerint az Alder Lake-ben levo Golden Cove 50%-al jobb IPC-ben mint a Skylake, viszont azt nem tudjuk melyik, mert ugye a Comet Lake is Skylake.Aztan hogy ez mire lesz eleg a valosagban, majd kiderul.
Intelnek most az volt a fontos, hogy viszaerjen az AMD melle/fele (ahol tud).Na meg az az atlag 15% IPC is nagyon jol hangzik a generaciok kozott, de ne felejtsuk el, hogy volt honnan novekedni. Most a 4. gen Ryzen hagyta le az Inteleket pl ha jatekot nezzuk, 7nm-en, kb fel evig, ha az Intel Rocket lake leakek igazak.
Az Intelnek a legfontosabb az ido. Addig kell kibirni amig ok is helyrehozzak a gyartasi gondokat. Mar a Rocket lake sem tunik rossznak, az Alder Lake szerintem a Windows-on fog inkabb bukni (big.little miatt).
Az sem garantalt, hogy az AMD tudja evekig tartani a tempot. Mar lattuk, nagyon sok minden valtozhat par ev alatt.[ Szerkesztve ]
-
#4613
Petykemano
veterán
Cathulhu
#4612
Petykemano
veterán
válasz
Cathulhu
#4612
üzenetére
Elég semmi volt ez a CES keynote megint.
Úgy tűnik, mintha én is, és Lisa Su is izgatottabb lett volna az első zen bejelentésekor, amikor még volt valami a zsákban. Csak én érzem azt, hogy hogy én is és Lisa Su is egyre kevésbé lelkes úgy, hogy szinte semmi nincs a zsákban?
Tényleg olyan volt, mintha úgy állt volna ki, hogy hoznék én nektek mindent, csak semmit nem tudunk legyártani és piacra vinni. Tehát most az a high end notebook Cezanne vajon hány eladást fog produkálni? 100-200e?
Találgatunk, aztán majd úgyis kiderül..
-
S_x96x_S
őstag
válasz
Cathulhu
#4653
üzenetére
> Nem nagy érvágás szerintem, aki desktop APUt vesz, annak nem kell a latest and greatest,
Azért a konkurenciától ( = Intel ) is függ ...
Az Intel az új 8 magos prociját - gpu-val ( ~ kvázi APU kategória )
márciusban kezdi nyomniHa az AMD csak a Q2 leges legvégén kezdi kihozni az új deskop APU-kat,
akkor az egy pici előny az Intelnek.
Ha már Április elején - akkor legalább lesz egy kis verseny - ami jót tesz az áraknak is.De hát ez van ... szűk gyártási kapacitás ... és el kell dönteni, hogy melyik ujját harapja meg az AMD .. Ezek a nehéz döntések.
Mottó: "A verseny jó!"
-
S_x96x_S
őstag
válasz
Cathulhu
#4659
üzenetére
> A desktop APUk ... altalaban csak irodai vagy netezos gepekbe mennek
<spekulálok>
akár ... megváltozhat ez is, ha az integrált GPU és a külső Radeon GPU -t együttmüködését mégjobban kigyurják[1]
és tényleg igaz lesz az, hogy az új APUk megközelítik az X-es konfigokat.[2]
VAGYIS ha az 5700G ilyen jó [2] .. akkor milyen lehet majd az 5800G ?szerintem benne van a pakliban ... van rá esély ...
[1]
"AMD Radeon™ Dual Graphics is an innovative technology exclusive to AMD platforms that allows AMD APUs and select AMD Radeon™ discrete GPUs to work together. When combined, the platform delivers stunning quality and performance capabilities that are better than either device alone." [link][2]
AMD Ryzen 7 5700G 8 Core Cezanne APU Performance Leaks Out, Overclocked To 4.75 GHz & Faster Than Ryzen 7 5800X
https://wccftech.com/amd-ryzen-7-5700g-8-core-cezanne-apu-performance-leaks-overclocked-to-4-75-ghz/Mottó: "A verseny jó!"
-

hokuszpk
nagyúr
válasz
Cathulhu
#4806
üzenetére
lehet nemerimeg aputgyartani, viszont ha nemtudsz az igpmentes procidmellé valami normalis vgatvenni, akkor elobb-utobb eladhatatlanok lesznek az asztali procik.
// nezd milyen f*sza gepem van, csak kepet kellene belole fakasztani !
oke ; dobjukki, vegyunk Intelt, abban legalabb van igp... //Első AMD-m - a 65-ös - a seregben volt...
-
hokuszpk
nagyúr
válasz
Cathulhu
#4808
üzenetére
ezzel adtak a sz* -nak egy pofornt. még így is megéri.
nomeg ha eddig a Vegara meg mindenre is bányászbiosokat hekkeltek, akkor majd pont erre nem. Egy regi drivertelepitoben modositanak 1-2 szamjegyet, aztan megy majd ez is maxigázzal.
szvsz az lenne a megfejtés, hogy kb. grafkártya árban 1.5-2x bányászteljesítményű vasakat adni nekik, akkor előbb-utóbb azt vennék, mert jobban megéri. Programozhato FPGA vasakat a banyaszpiacra ![ Szerkesztve ]
Első AMD-m - a 65-ös - a seregben volt...
-
S_x96x_S
őstag
válasz
Cathulhu
#4906
üzenetére
> a little endiannak amugy is tobb ertelme van,
> az ARM meg mar vagy 30 eve bi-endian architectura, nem latom itt az apple nagy ujitasat.jó kérdés .. de mintha a kód és az adat endián eltérne.
"Note that ARM does not support big endian code. Code is always little endian - only data accesses can be big endian."Egy emulációnál - az önmagát újrairó trükkös kódoknak - programvédelmeknek is futnia kell.
de egy InfoQ cikk - ezt igy fogalmazta meg:
"One major concern with Rosetta is performance. With the transition from PPC to x86, one factor slowing down Rosetta was the different byte ordering used by the two platforms, with PowerPC being a big-endian architecture, and x86 little-endian. While byte ordering is not a problem for the transition from x86 to ARM, another issue related to memory, namely the memory consistency model total store ordering (TSO), could hamper performance in this case. To prevent this from happening, Apple added support for x86 memory ordering to the M1 CPU, as Robert Graham noted on Twitter."de pontosítsál/cáfoljál .. mert már nagyon megkopott és régi a hexa tudományom.
( ami nagyjából azt jelenti, hogy ARM szinten laikus vagyok )Mottó: "A verseny jó!"
-
S_x96x_S
őstag
válasz
Cathulhu
#4929
üzenetére
> Hova kapkodjanak most a Zen4-gyel.
elméletileg ~ ősszel jön ( vagy inkább csak bejelentik )
az Alder Lake-et ( ami már Gen5, DDR5 -is tudhat)
és jövőre jöhet a Sapphire Rapidshoz hasonló HEDT cpu - Alder Lake alapokon ( akár HBM + CXL-el )és az Év végén /Jövő év elején az Intelnek ki kell hoznia az első DDR5-ös konfigját .. mert a memóriagyártók nem fognak csak úgy gyártani a raktárnak.
Mottó: "A verseny jó!"
-
-
#4941
Petykemano
veterán
Cathulhu
#4929
Petykemano
veterán
válasz
Cathulhu
#4929
üzenetére
"Hova kapkodjanak most a Zen4-gyel."
Az AT tesztjeiben most és a Milan esetében is jelen volt a 80 magos Ampère altra, és nem is szerepelt rosszul. Pedig az abban levő mag nem kifejezetten friss, az A76 szerver varinsa, azóta meg már van A77 és A78/X1
(Abból persze termék ugyanúgy nem lesz, amíg nem tudJák 5nm-en gyártani.)Szerintem már egy N2-re épülő szerverprocesszor is csúnyán bekavarna nem is beszélve arról a lehetőségről, hogy a Qualcomm által felvásárolt Nuvia épp ide fejlesztett. És akkor még nem is beszéltünk az armot felvásárló nvidiáról.
Sokaknak szimpatikus az SVE is, mert a programkód nem függ a hardverben található feldolgozó szélességétől szemben az AVX/2/512 szerteágazó implementációival.
Azt mondják persze, hogy idővel a CPU jelentősége csökkenni fog és át fog helyeződni a.hangsúly arra, milyen gyorsítókat tudsz mellérakni. De ebben meg az nvidia és az Intel sincs lemaradva.
Találgatunk, aztán majd úgyis kiderül..
-
hokuszpk
nagyúr
válasz
Cathulhu
#4960
üzenetére
a fabricbol abban a szuperize kompjuterben mar mukodik a 3.0 -s verzio, ha oda jo lesz, akkor az EPYCbe sem lehet olyan rossz. ÉS lehet rosszultudom, de a HBM ugy eri el azt a brutal savszelt, hogy 4096 bites busszal operal, a 8 csatornas DDR5 az meg talan 1024 bitre jon ki ?
[ Szerkesztve ]
Első AMD-m - a 65-ös - a seregben volt...
-
#4962
Petykemano
veterán
Cathulhu
#4960
Petykemano
veterán
válasz
Cathulhu
#4960
üzenetére
Kezdetben csak 42GB/s, kétirányú volt, 1333Mhz-en: [link]
Azóta ezt sikerült feljebb vinni a Renoir esetén már 2200Mhz-ről beszéltek, ami már majdnem 70GB/s: [link]
Ez persze talán nem teljesen ugyanez, de A Radeon VII esetén arról, hogy 2db egyenként 84GB/s kétirányú link van rajta.
Abu meg 100GB/s-ről beszélt itt: [link]Ezzel az AMD is kísérletezget: [link]
Én sem értem, hogy fogják hasznosítani. Ha mondjuk dupláznák a linkeket, még az is legjobb esetben 150GB/s lenne / CCDEgyébként itt egy mérés: [link]
Azt valaki el tudja nekem magyarázni, hogy hogy lehet, hogy a 8 memóriacsatornából csak 100GB/s jön ki?
Azért van, mert egy mag tényleg csak a hozzá legközelebb eső memóriavezérlőt tudja használni?Na mindegy, attól függetlenül azt akartam mondani, hogy az ábra szerint ilyen 40GB/s érhető el egy magnak. Ha ezt fel tudnák emelni 150GB/s-ra már az is nagy előrelépést jelenthet.
Találgatunk, aztán majd úgyis kiderül..
-
S_x96x_S
őstag
válasz
Cathulhu
#4960
üzenetére
> Az az 1TB/s brutalisan soknak tunik.
és akkor az 1.6TB/s ?
Ez a cél a 72x Arm Neoverse Zeus - magos SiPearl-nél
ami már a TSMC N6-ján készül és 2022Q4-re tervezik kihozni.
https://sipearl.com/index_en.php
" a Rhea SoC could feature up to 96 GB of HBM2E at 1.6TB/s as well as up to 6TB (using 8-Hi 16Gb-based DDR5 stacks) or 12TB (using 16-Hi 16Gb or 8-Hi 32Gb-based stacks) of DDR5 memory using two modules per channel."SiPearl's 72-Core Rhea HPC SoC to Be Made Using TSMC's N6 Node"
https://www.tomshardware.com/news/sipearl-rhea-n6-open-silicon-research ( 2021Feb)
https://www.anandtech.com/show/16072/sipearl-lets-rhea-design-leak-72x-zeus-cores-4x-hbm2e-46-ddr5 ( 2020September8)Igazából az Intel 1TB/s - lehet, hogy kevés is lesz
 ..
..
Főleg ha az AMD az Epyc Zen4- el is hasonlót tervez ( ~ 1.6TB/s )Mottó: "A verseny jó!"
-
S_x96x_S
őstag
válasz
Cathulhu
#5171
üzenetére
ennek az APU-nak elméleti maximuma ~ 2.048 TFLOPs
vagyis elég gyenge a DDR4-es GPU teljesítménye.> Mennyi is az, 1? 1.2? Valahogy úgy.
"With the base model PlayStation 4 being capable of 1.84 TFLOPS and the PS4 Pro being capable of 4.2 TFLOPS, the PS5 is dramatically ahead of both with its recently-revealed capacity for 10.28 TFLOPS " [link]
Mottó: "A verseny jó!"
-
S_x96x_S
őstag
válasz
Cathulhu
#5262
üzenetére
> de a v-cache-t is a TSMC fogja gyartani?
igen ; spéci TSMC 7nm -es integráció - TSMC's CoW (Chip-on-Wafer)
Anandtech:"The TSV interface is a direct die-to-die copper interconnect, meaning that AMD is using TSMC’s Chip-on-Wafer technology. " [link]
-->
https://www.tsmc.com/english/dedicatedFoundry/technology/platform_HPC_tech_WLSI
> Az nem mehet 12 nanon a GF-nel?minden lehetséges, de szerintem nem éri meg.
ráadásul úgy, hogy még az idén meg is jelenjen a közös integráció ..és extrém bonyolult lenne.
egyben kellene látnia és kezelnie a rendszernek
a TSMC-s 7nm -es belső L3Cache -t a GF12nm-es ráépülő L3Cache-el.
Mégha együtt is tudna müküdni, még a sebességnek is hasonlónak kell lennie. Ráadásul több pontos - függőleges integrációval
és hogy ez müködjön a két cég mérnökeinek nagyon együtt is kellene dolgoznia, gyártási titkokat kellene megosztani, ...
és ha nem müködik, ki a felelős?
Most a TSMC felel érte .. Ha az AMD erösködik, hogy legyen benne a GF is a buliban .. akkor az AMD lesz a felelős .. a TSMC és a GF egymásra mutogat majd ..
sőt szerintem a TSMC akarja a jövőben az I/O Die-t is gyártani N6-on!
"Zen 4 chips are stated to feature two Zen 4 CCD's based on the TSMC N5 process node and a CIOD (I/O die) based on the TSMC N7 process node however the latest reports suggest that the I/O die has been moved to a 6 nm process node." [link]ráadásul most úgy tünik, hogy a GloFO eléggé
elhanyagolta a fejlesztéseket.
friss hír: Az IBM már perelni akarja.
"WHY IBM IS SUING GLOBALFOUNDRIES OVER CHIP ROADMAP FAILURES"
https://www.nextplatform.com/2021/06/10/why-ibm-is-suing-globalfoundries-over-chip-roadmap-failures/amúgy a cikkben van egy AMD - GF spekuláció is.
"What we don’t know is if AMD decided to jump over 10 nanometer processes to 7 nanometer processes to get an edge on Intel or if it really had no choice to do so because GlobalFoundries was pulling the plug to focus on its dual-prong 7 nanometer effort. We think AMD was hit by the same 10 nanometer surprise that IBM was, but AMD never said anything about that and put the best spin on it. Much as IBM did with the difficulties that GlobalFoundries apparently had bringing 14 nanometer processes and IBM never said much at all about 10 nanometer issues. AMD, of course, used 14 nanometer processes from GlobalFoundries for its first generation “Naples” Epyc 7001 chips and still uses 14 nanometer processes in the I/O and memory hub at the heart of the Rome and Milan server processor packages. The Rome and Milan cores are etched by TSMC in 7 nanometers, and Infinity Fabric links hook hub and the cores together in a single package."
[ Szerkesztve ]
Mottó: "A verseny jó!"























 ..
..Új hozzászólás Aktív témák

- Asus V8460 Ultra ( Geforce 4 Ti 4600 )
- HP Prodesk 600 G5 DM, Tiny i5-9500T , 8-16GB DDR4 , 256GB NvME , 2 év gari , AAM számla
- DOBOZOS Lenovo ThinkPad T14s Gen 3:R7 PRO 6850U,32GB DDR5,2TB,vil.HU bill,Radeon680M,400nit 100%sRGB
- Ricoh Theta Z1 360 fokos kamera
- IPhone 14 128GB gyári független 2026.11.09. Apple garancia
Állásajánlatok

Cég: Ozeki Kft.
Város: Debrecen

Cég: Alpha Laptopszerviz Kft.
Város: Pécs