Új hozzászólás Aktív témák
-

S_x96x_S
őstag
ISA architektúrák .. X86 vs. ARM
RISC vs. CISC Is the Wrong Lens for Comparing Modern x86, ARM CPUs
https://www.extremetech.com/computing/323245-risc-vs-cisc-why-its-the-wrong-lens-to-compare-modern-x86-arm-cpusAGner Fog
"
ISA is not irrelevant. The x86 ISA is very complicated due to a long history of small incremental changes and patches to add more features to an ISA that really had no room for such new features…
The complicated x86 ISA makes decoding a bottleneck. An x86 instruction can have any length from 1 to 15 bytes, and it is quite complicated to calculate the length. And you need to know the length of one instruction before you can begin to decode the next one. This is certainly a problem if you want to decode 4 or 6 instructions per clock cycle! Both Intel and AMD now keep adding bigger micro-op caches to overcome this bottleneck. ARM has fixed-size instructions so this bottleneck doesn’t exist and there is no need for a micro-op cache.
Another problem with x86 is that it needs a long pipeline to deal with the complexity. The branch misprediction penalty is equal to the length of the pipeline. So they are adding ever-more complicated branch prediction mechanisms with large branch history tables and branch target buffers. All this, of course, requires more silicon space and more power consumption.
The x86 ISA is quite successful despite of these burdens. This is because it can do more work per instruction. For example, A RISC ISA with 32-bit instructions cannot load a memory operand in one instruction if it needs 32 bits just for the memory address."----------------------------------------
és mégegy Kapcsolódó cikk az elmúlt hetekből -
Emulációnál viszont az ARM(AArch64) - 2x annyi regiszterének és a 3 operandusos utasításkészletének van valami előnye.
Valamint energiahatékonyabb is az M1. ( de ez az 5nm miatt is )
"Temptation of the Apple: Dolphin on macOS M1""AArch64 does have its advantages, though. Namely, the processors have 31 registers, compared to the 16 available in x86-64 processors. The PowerPC processor we are emulating has 32 registers, and while it is rare for all of them to be used within a single code block, more registers is always nice to have. Another difference is that AArch64 and PowerPC have 3 operand instructions while x86-64 only has two.
PPC: A = B + C AArch64: A = B + C x86-64: A = B, A = A + C
As you can see, it makes emulating some instructions much cleaner and easier than on our x86-64 JIT. Alright, enough with the boring details. How does the M1 hardware perform when put up against some of the beasts of the GameCube and Wii library? ..."
Mottó: "A verseny jó!"
-
S_x96x_S
őstag
válasz
 S_x96x_S
#5192
üzenetére
S_x96x_S
#5192
üzenetére
> - "Feb 2022 launch" -re jósolja a következő AMD cpu generációt.
> (feltételezem, hogy valami belsős infó alapján, Ian Cutress a kevésbé
> blöffölös fajta elemzők közé tartozik)rákérdezett:
"Confirmed with AMD that V-Cache will be coming to Ryzen Zen 3 products, with production at end of year."
https://twitter.com/IanCutress/status/1399766139769602058Az Intel ellen valamit ki kell állítani ..
Közben az interneten már találgatják a termékelnevezést:
"Ryzen 5950XT Pro Hyper V-Cache RX edition"Mottó: "A verseny jó!"
-

carl18
addikt
-
#5204
 Petykemano
veterán
S_x96x_S
#5201
Petykemano
veterán
S_x96x_S
#5201
Petykemano
veterán
válasz
S_x96x_S
#5201
üzenetére
Agner:
"A serious bottleneck is a decoding rate of 4 instructions or 16 bytes per clock. To compensate for this, the Zen 3 has a micro-op cache with 4096 entries after the decoder.
The increased throughput in terms of instructions per clock may be difficult to utilize if the software has long dependency chains (where each calculation must wait for the result of the preceding one). It is now more important than ever to avoid long dependency chains.
The bottleneck in the decoder appears to be difficult to overcome. This is a consequence of the messy x86 code structure where instructions can have any length from 1 to 15 bytes, and it is complicated to determine the length of each instruction. Intel processors have the same bottleneck and the same decoding rate. The programmer must make sure the critical part of a program fits into this micro-op cache if you want to get the maximum throughput. It is important to avoid loop unrolling where possible in order to economize the use of the micro-op cache. (The Clang compiler often makes excessive loop unrolling)"
[link]Az AT fórumon két elképzelés (patent) is fölmerült.
Én nem értek hozzá, nem tudom megmondani, hogy melyik mennyire jó vagy nem jóVirtualuizált uop cache [link]
A másik pedig a Tremont féle dual-decoder út [link]Persze lehet, hogy mindkettő módszer együttes használata adja a legjobb eredményt - és a legtöbb tranzisztor és fogyasztástöbbletet az Armhoz képest, ahol ilyen trükkökre nincs szükség.
Mindenesetre úgy tűnik ez alapján, hogy egyelőre hard Wall nincs, csak ha fejlődni szeretnének, akkor arra az Armhoz képest több tranzisztort és fogyasztást kell áldozni.
Egyelőre mindenki azt mondja, hogy az IPC szignifikáns növelésének legkézenfekvőbb módja a mag szélesítése lenne [link] aminek az x86 esetén az a korlátja, hogy a decoder nem tudják 4(-5)-nél szélesebbre venni.
Valószínűleg enélkül is lehet IPC-t növelni - valahogy úgy, ahogy az intel teszi, hogy a bufferek, regiszterek és cache-ek 25-50%-os növelése itt-ott ad 1-2%-os gyorsulást, ami végülis kiadhat egy valamirevaló 15%-os előrelépést egy generációban. De ez nem az a fajta ugrás, amit az igen vékony bulldozer magról az akkori értelemben széles ryzen magokra ugrás hozott és amivel utol lehetne érni az Apple M1-et.Úgy tűnik, hogy ennek az akadálynak az elhárítása a következő pár év nagy kihívása és beszédtémája lesz.
[ Szerkesztve ]
Találgatunk, aztán majd úgyis kiderül..
-
#5205
Petykemano
veterán
S_x96x_S
#5178
-
S_x96x_S
őstag
V-Cache - Anandtech részletes frissítés:
Update June 1st:
In a call with AMD, we have confirmed the following:- This technology will be productized with 7nm Zen 3-based Ryzen processors. Nothing was said about EPYC.
- Those processors will start production at the end of the year. No comment on availability, although Q1 2022 would fit into AMD's regular cadence.
- This V-Cache chiplet is 64 MB of additional L3, with no stepped penalty on latency. The V-Cache is address striped with the normal L3 and can be powered down when not in use. The V-Cache sits on the same power plane as the regular L3.
- The processor with V-Cache is the same z-height as current Zen 3 products - both the core chiplet and the V-Cache are thinned to have an equal z-height as the IOD die for seamless integration
- As the V-Cache is built over the L3 cache on the main CCX, it doesn't sit over any of the hotspots created by the cores and so thermal considerations are less of an issue. The support silicon above the cores is designed to be thermally efficient.
- The V-Cache is a single 64 MB die, and is relatively denser than the normal L3 because it uses SRAM-optimized libraries of TSMC's 7nm process, AMD knows that TSMC can do multiple stacked dies, however AMD is only talking about a 1-High stack at this time which it will bring to market.
Mottó: "A verseny jó!"
-
#5207
 awexco
őstag
Petykemano
#5197
awexco
őstag
Petykemano
#5197
awexco
őstag
válasz
 Petykemano
#5197
üzenetére
Petykemano
#5197
üzenetére
Ez egy nagyon sok ismeretlenes egyenlet . Sok dologot nem tudunk .
Az biztos , hogy alapjában véve nagyon durván pazarló megoldás ebben a kivitelben . De nem feltétlenül rossz . Megnyitja a lehetőségek tárházát . Annak van értelme , hogy a legnagyobb asztali cpu kapjon belőle. Mert vannak olyan gamerek akik nem az árat nézik és megvesznek bármit ami a csúcs .
Laptop téren elgondolkoztam egy picit . Teszem azt a kissebb cpu-kra rátesznek 8gb a nagyobbakra mondjuk 16gb ramot . Lehet kissebb chippet is tervezhetnek és maga komplet termék kissebb , olcsóbb is lehet . Mivel az integrációnak hála sok minden elhagyható lesz a nyákról .
Ez az egész egy opció . Annak is fügvénye lesz , hogy mennyi gyártó kapacitása lesz az amdnek . Ha kevés termék fogy véletlen és fel kell használni a gyártó kapacitást , hogy értéknövelt terméet áruljanak arra jó ...
Vajon menyibe kerülhet amdnek csak a szilicium gyártása (2x36) mindenféle járulékos költség mentesen ?[ Szerkesztve ]
I5-6600K + rx5700xt + LG 24GM77
-

paprobert
senior tag
Vajon menyibe kerülhet amdnek csak a szilicium gyártása (2x36) mindenféle járulékos költség mentesen?
Ian Cuttress számolt egyet korábban: [link]
Az ő számai alapján egy cache lapka kevesebb mint 7 dollár, a 2 chipletre való 13.5 dollárba kerül 7nm anyagköltségen.640 KB mindenre elég. - Steve Jobs
-

HSM
félisten
válasz
S_x96x_S
#5206
üzenetére
"- As the V-Cache is built over the L3 cache on the main CCX, it doesn't sit over any of the hotspots created by the cores and so thermal considerations are less of an issue. The support silicon above the cores is designed to be thermally efficient."
Azért az nem túl bíztató, hogy "less of an issue". A nagy kérdés, hogy a hűtő és a tranzisztorok távolsága változott-e, ez sajnos ebből nem derült ki. Ha nőtt, akkor a hűthetősége elméletileg rosszabb lesz.#5208 paprobert : Azt lenne még érdekes tudni, a csip és kapacitás hiány miatt mennyi bevételtől esnének el, ha pl. ilyeneket gyártanának adott kapacitásokon Navi GPU-k és Zen3 CCD-k helyett. És ezt mondjuk mennyire lehet ellensúlyozni egy nyilván magasabban árazott prémium termékkel, amihez ezeket felhasználhatják. Persze, B-tervnek is jónak tűnik, ha az Alder Lake túl jól sikerülne.

-
#5210
Petykemano
veterán
S_x96x_S
#5206
Petykemano
veterán
válasz
S_x96x_S
#5206
üzenetére
Jól értem, hogy a 36mm2 = 64MB és ez egy réteg?
Tehát nem 2x36mm2.Vajon.... mi érné meg jobban?
- hasonló rétegeket az L2$ és L1$ fölé építeni?
- a jelenlegi L3$ helyén az L2$ méretét növelni (hogy a V-cache továbbra is cache fölött legyen) és az L3$-t pedig kompletten kiszervezni többrétegű V-cache-be?Találgatunk, aztán majd úgyis kiderül..
-
#5211
Petykemano
veterán
S_x96x_S
#5192
Petykemano
veterán
válasz
S_x96x_S
#5192
üzenetére
Feb 2022
a dátum - noha későbbi, mint amit én reméltem - nem irreális,.sőt.
A Vermeer megjelenéséhez képest 15 hónap - a szokásos termék-megjelenés-intervallum.
Lisa Su azt mondta a kísérleti zen3V-re, hogy év végén kerül gyártásba. Onnan még biztosan pár hónap, mire termék lesz.De vajon milyen termék?
Szerverbe nagyonis lenne értelme, ott bármilyen formában megfizettethető. =>Milan-X (Talán nem is nagyon lenne szükség v-cache nélküli termékre.)Viszont abból lenne értelme vajon új szériát csinálni, ha egyébként csak a legdrágább 8-12-16 magos darabokra kerül rá? Na nem mintha sok 8 magosnál kisébb zen3 létezne a piacon. Viszont egy olyan új széria, ami nagyobb drágulást hoz - mert a texhnológia drága - mint amennyi előnyt biztosít, az megint fölháborodást fog kelteni. Persze tudom, így is el fog fogyni.
Na de mindegy, nem is ide akartam kifuttatni, hanem az időzítésekhez. Ha ez az AMD 2022Q1-2023Q2-ig tartó terméke (ide értve a Vermeer-X és Milan-X is) akkor miért mondta Lisa Su, hogy eltökéltek az 5nm-es termékek 2022-ben való megjelentetését illetően?
Persze sokminden lehetséges. Pl:
- 2022 hosszú, a zen4 indulhat akár 2022Q4-ben is és még akkor is 2022. Azt gondolnám, hogy ez talán inkább a DDR5 és az 5nm elérhetőségétől függ, mint attól, hogy kész van-e. A Milan-X a meglevő alaplapokba akkor is remek drop-in-replacement lenne, ha egyébként egyszerre jelenne meg a Genoaval.
- én továbbra is azt remélem, hogy a 7nm-es (AM4) termékek olcsóbb változatként még pár évig a piacon maradnak. Ennek némileg ellentmond az, hogy a zen4-ről meg épp azt rebesgetik, mégsem emel magszámot.
- egy kísérleti terméket láttunk. A végleges 2022-ben megjelenő megoldás épülhet éppenséggel már zen4-re - újabb meglepetést okozva. Nem jött megerősítés arra vonatkozólag, hogy ez volna a Warhol
(Én erre látok legkevesebb esélyt)Találgatunk, aztán majd úgyis kiderül..
-
#5212
S_x96x_S
őstag
Petykemano
#5211
S_x96x_S
őstag
válasz
Petykemano
#5211
üzenetére
> Lisa Su azt mondta a kísérleti zen3V-re, hogy év végén kerül gyártásba.
én már azzal a gondolattal is eljátszottam,
hogy a következő Threadripper (zen3-as) _TALÁN_ már ilyen lesz ..
De szeptemberre még semmi esély ..
Mottó: "A verseny jó!"
-
#5213
Petykemano
veterán
Petykemano
veterán
Megszakítjuk adásunkat...
IDT => Intel FRED vs AMD SEE
Linux szerint "és"
[link]Kiváncsi vagyok, hogy lesz-e a jövőben valamilyen közös megoldás például a mostanában sokat emlegetett utasítás-hossz problémára, ami szakértők szerint egy objektív akadálya a mag szélesítésének.
Találgatunk, aztán majd úgyis kiderül..
-
paprobert
senior tag
Abban a termékszegmensben, ahol az egyre jobb termékek már 200-300 dollárokkal lépkednek felfele árban, kigazdálkodják valahogy.
 Nyilván azért csinálják, mert megéri csinálni.
Nyilván azért csinálják, mert megéri csinálni.Egyébként lassan vége a kapacitáshiánynak.
CPU-ból már túltermelés van, és amint az eladatlan termékeken realizálódó kieső profit egyenlőséget tesz a GPU részleg eddigi 30%-os dollár/mm2 hendikepje között a CPU-hoz viszonyítva, a GPU termelés is helyre fog állni.
Gyakorlatilag mindegy lesz anyagilag, hogy melyiket gyártja majd az AMD.[ Szerkesztve ]
640 KB mindenre elég. - Steve Jobs
-
#5215
Petykemano
veterán
Petykemano
#5211
Petykemano
veterán
válasz
Petykemano
#5211
üzenetére
"In fact, the AM5 schedule is inconsistent with the V-Cache Zen3. This is one of the reasons why AM5 will only appear on ZEN4."
[link]Találgatunk, aztán majd úgyis kiderül..
-
S_x96x_S
őstag
válasz
 paprobert
#5214
üzenetére
paprobert
#5214
üzenetére
> CPU-ból már túltermelés van,
ezt hogy érted?
- vagy erre milyen adatokból/jelekből következtettél?
- vagy ezt csak az OEM és a Cloud-ra érted?mert a Consumer hazai piacon:
- én "G"-s és "Athlon" procit nem is nagyon látok.
- és AthlonG-s pedig még ritkább. ( Athlon 3000G, 200GE, 240GE )ha csak a 7nm-resekre .. azért ott is lenne igény ..
és várják az új olcsó 5600G-t. ( meg ha lenne Ryzen3 -as ZEN3-as )Mottó: "A verseny jó!"
-
S_x96x_S
őstag
AMD Rembrandt will not get Infinity Cache
AMD has recently updated the Linux kernel with information on the upcoming Yellow Carp APU.
https://videocardz.com/newz/amd-ryzen-6000-rembrandt-yellow-carp-apu-will-reportedly-not-feature-infinity-cache
"
The APU will require a new FP7 socket, which will force laptop makers to adopt existing designs for new motherboards and possibly power and thermal characteristics of the “Yellow Carp” APU series. This is understandable, as Rembrandt brings major changes not only to the CPU and GPU core but also I/O. Rembrandt will be the first AMD APU to support DDR5 and LPDDR5 memory standards. It will also enable PCIe Gen4 support, which is something that Cezanne currently does not.
According to some new information, Rembrandt will not have Level3 (L3) cache, at least there is no such entry in the recent Linux kernel update (only L1 and L2 cache).
Furthermore, instead of 8 Compute Units per ShaderArray, Rembrandt will have 6. The code does not confirm the full number of CUs in the APU though. The Zen3+ and 6nm fabrication processes have not yet been confirmed either, but they have been repeated in rumors for quite a while, so it would be surprising if they turn out to be false.
"
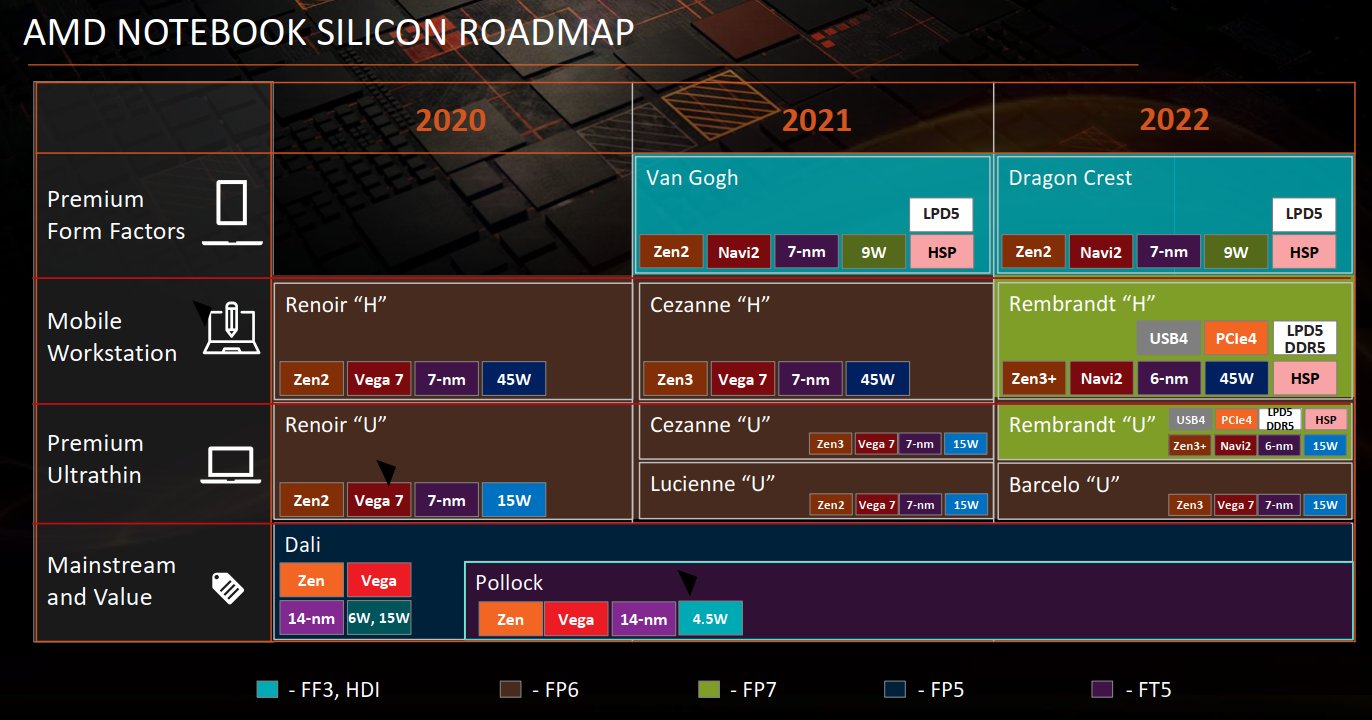 Source: @Broly_X1
Source: @Broly_X1Mottó: "A verseny jó!"
-
S_x96x_S
őstag
CPU trend: VCPU specializálódás ..
Az általános x86 CPU feladatot - egyre inkább specializált chipek veszik át."Google New Custom Silicon Replaces 10 Million Intel CPUs | Google Argos VPU"
https://semianalysis.substack.com/p/google-new-custom-silicon-replaces
"if we assume that Google’s servers are utilized at 100% (they aren’t), all YouTube/Google Photos/Google Drive footage video is 1080p 30FPS, and the target is H264, the workload would require ~904,000 Intel Skylake server CPUs to encode. Google switching to VP9 with the same set of assumptions would require ~4,193,000 Intel Skylake server CPUs. If the ingest footage is 4k 60FPS, then the number of CPUs required for H264 is ~7,205,000, and VP9 requires ~33,407,000."
Mottó: "A verseny jó!"
-
HSM
félisten
válasz
paprobert
#5214
üzenetére
"Nyilván azért csinálják, mert megéri csinálni."
Nyilván, de nem mindegy, milyen szempontból éri meg... Pl. az is lehet a cél, hogy megtartsák a "leggyorsabb gaming CPU" címet, miközben nyilván a tömeg nem 5950X "triple L3" kiadásokat fog vásárolni....
#5218 S_x96x_S : A videók enkódolását/dekódolását azért már elég régóta szokás célhardverre vinni (tipikusan GPU/IGP), mivel jól gyorsítható ilyesmikkel.
-
S_x96x_S
őstag
Simply NUC Ruby R8 (CBM1r8RB) AMD NUC Review
https://www.storagereview.com/review/simply-nuc-ruby-r8-cbm1r8rb-amd-nuc-review
van több config ... R3/R5/R7
https://simplynuc.eu/ruby/
Ruby R3
AMD® Ryzen™ R3-4300U CPU (4c/4t) passmark: ~7667
AMD® Radeon™ Vega 5 Graphics
4GB DDR4 Memory
128GB SSD
1x 2.5GbE NIC + 1x 1GbE NIC + Intel Wi-Fi 6 AX200
Free OS installation
FULLY CONFIGURED
From €439 Ex.VATMottó: "A verseny jó!"
-
#5222
Petykemano
veterán
Petykemano
veterán
AMD Ryzen 3 6100 [link]
4 mag
5ghz
Nem valami magas eredmény értékek...
Könnyen lehet, hogy fake[ Szerkesztve ]
Találgatunk, aztán majd úgyis kiderül..
-
#5223
 Z10N
veterán
Petykemano
#5222
Z10N
veterán
Petykemano
#5222
Z10N
veterán
válasz
Petykemano
#5222
üzenetére
Fake. Abu szerint 8 mag lesz a belepo
# sshnuke 10.2.2.2 -rootpw="Z10N0101"
-
#5225
 Yutani
nagyúr
Petykemano
#5222
Yutani
nagyúr
Petykemano
#5222
Yutani
nagyúr
-
S_x96x_S
őstag
LINUX ..
fixálnak egy ryzen boot problémát ..
Linuxosok - óvatosan !CPU: Ryzen 7 3700xMB: Asrock X470 Taichi bios P4.70Have been unable to boot 5.13 rc kernels but bisected the issue to this commit:"Linux x86/x86_64 Will Now Always Reserve The First 1MB Of RAM"
"The motivation now for Linux 5.13 in getting that 1MB unconditional reservation in place for Linux x86/x86_64 stems from a bug report around an AMD Ryzen system being unbootable on Linux 5.13 since the change to consolidate their early memory reservations handling. Just unconditionally doing the first 1MB makes things much simpler to handle."
https://www.phoronix.com/scan.php?page=news_item&px=Linux-Always-Reserve-1MB
[ Szerkesztve ]
Mottó: "A verseny jó!"
-
#5227
Petykemano
veterán
Petykemano
veterán
AMD ZEN4 and RDNA3 architectures both rumored to launch in Q4 2022
[link]Ebből elég nagy blama/zúgolódás (=> idővel térvesztés) lesz. Szerintem.
... amennyiben az AMD a Vermeer-X-et (Zen3 refresh) nem úgy fogja bevezetni, hogy minden chiplet kap egy v-cache-t, hanem csak a 12,16, esetleg a legerősebb 8 magos kapja meg és az is komoly áremelkedéssel.Gondolhatnánk, hogy tök jogos az áremelés, meg hogy csak a drágább modellek kapják meg, mert hát drága technológia. Persze, érthető.
Akár nevethetnénk is, hogy ugyan minek kéne erőlködni, az intel sehol sincs, a Vermeer-X bőven elég lesz az Alder Lake ellen (a lényeg úgyis az, hogy chartokon folyó versenyt ki nyeri )
Ahogy az is lehetséges, hogy az AMD az 5nm-hez előbb ha akarna se férne hozzá.
És persze az is érthető, hogy minek gyártsanak jobb terméket, ha még abból se tudnak eleget gyártani, amijük most kapható.De közben Apple oldalról érkezik az M1X meg az M2.
Ha az Apple hoz 10-15% generációs növekményt, akkor azzal még mindig megőrzi az előnyét és ha 4+4 helyett komolyabb konfigurációt hoz, az nagyon el fogja halványítani az AMD erőfeszítéseit. Mindezt ráadásul úgy, hogy lényegesen kisebb TDP-ből kijön.
Mondjuk egy 16+4-es konfigurációban (az apple kis magjai emlékeim szerint nem efficiency, hanem Low Power magok) még az sem feltétlenül biztos, hogy az AMD marad a desktop környezet megkérdőjelezhetetlen királya.A Nuvia a saját csodáját 2023-ra ígérte. A Qualcomm felvásárlással esetleg felgyorsulhatott annyira, hogy 2022-ben ledobjanak valamit, ami emlékeztet az M1-re.
Valahogy azt érzem, hogy ebből az lesz, hogy az AMD küszködik itt a kapacitásokkal, meg az intellel való küzdelemben és az ARM-os megoldások a külső íven fogják előzni mindkettejüket.
Találgatunk, aztán majd úgyis kiderül..
-
S_x96x_S
őstag
 látom - lassabb vótam ... ( de ezért itthagyom )
látom - lassabb vótam ... ( de ezért itthagyom )
---------
Jajj .. 2022-Q4 ! - akkor az egyik variáció:
2022Q1: ZEN3 XT
2022Q4: ZEN4AMD ZEN4 and RDNA3 architectures both rumored to launch in Q4 2022
https://videocardz.com/newz/amd-zen4-and-rdna3-architectures-both-rumored-to-launch-in-q4-2022[ Szerkesztve ]
Mottó: "A verseny jó!"
-
#5229
 Busterftw
veterán
Petykemano
#5227
Busterftw
veterán
Petykemano
#5227
Busterftw
veterán
válasz
Petykemano
#5227
üzenetére
Ebbol ahogy irtad csak a CPU lesz max maceras, bar ez attol is fugg az Alder Lake hogy sikerul.
RDNA3 meg elegge adja magat, 2 eves ciklus meglesz az RDNA2-nel es a konkurencianal is. -
#5231
S_x96x_S
őstag
Petykemano
#5227
S_x96x_S
őstag
válasz
Petykemano
#5227
üzenetére
> Gondolhatnánk, hogy tök jogos az áremelés,
> meg hogy csak a drágább modellek kapják meg,
> mert hát drága technológia.- még nem biztos, hogy lesz áremelkedés.
- ráadásul az Inteltől is függ, hogy milyen árat lő be.
( amit az AMD bizonyára figyelembe vesz )nekem a Gen5 a sötét ló , vajon mi az AMD stratégiája?
mert ha ZEN3XT - hez nem lesz Gen5-ös lehetőség, akkor
az sokaknak fájhat..A prémium gamer / mini workstation-t keresők körében szerintem tarolni fog a Gen5.
- főleg a Gen5-ös GPU-k sokkal alacsonyabb latency-je miatt
- valamint a több GPU-s CXL összekötés, ami annó "Coherent Multi-GPU" néven futott, habár nem tudom, hogy melyik CXL verzió mire képes .. ( Ez valami általános SLI szerűség utódja )vagyis 2 középkategóriás Gen5-ös Intel GPU .. _akár_ le is verheti,
a csúcs nVidia / Radeon (Gen4)-es kártyákat .. ( ~ elméletben )"If CXL can seamlessly scale GPUs, then the economics of the market would also change completely. People would be able to buy a cheaper GPU first and then simply add another one if they want more power. It would add much more flexibility in buying decisions and even alleviate buyers remorse to some extent for the gaming class. If CXL mode trickles down to the consumer level anytime soon, then we might even see motherboard designs change drastically as multiple sockets and multiple GPUs become a feasible option. Needless to say, it looks like things are going to get pretty exciting in a few years."
( a coherent multi-gpu-s linkről másolva )
Mottó: "A verseny jó!"
-
#5232
 Mumukuki
aktív tag
Petykemano
#5227
Mumukuki
aktív tag
Petykemano
#5227
Mumukuki
aktív tag
válasz
Petykemano
#5227
üzenetére
Mióta kijött az M1 én azt mondom hogy szerintem az x86 -nap szépen lassan egyre kisebb szelet jut , perifériára szorul nagyon .
Eleve apple ami elég sok embernek , nem is lett annyira szar , a marketingje máris jó -
#5233
Petykemano
veterán
S_x96x_S
#4995
Petykemano
veterán
válasz
S_x96x_S
#4995
üzenetére
zen4 IPC
Sokmindent lehetett eddig olvasni
- volt ez a zen2 =>zen4 +45%
- volt zen3 => zen4 +29% (Milan => Genoe)
- MLiD utolsó videójában zen3 => zen4-re 20+%-ról írtDe az AMD jól megkavarta ezeket információkat.
Mi a zen3? plain zen3, vagy zen3D?
Mi a zen4? plain zen4, vagy a zen4-et már v-cache-sel együtt kell érteni? (Ami még nem jelenti azt, hogy minden sku-n lesz v-cache, de hát ugye "upto*" )És hol jön képbe a Rembrandtnál szereplő zen3+?
"AMD Ryzen 6000 Warhol could hit 5 GHz with 9-12% gains over Zen 3"
Ezeket 9-12%-os értékeket magyarázná, ha a v-cache-re vonatkozna. Bár ha frekvencia növekményt is nézzük, akkor a 9-12% meg elég konzervatív. (Bár lehet, hogy az AMD is azt a pár játékot emelte ki, ahol van létjogosultsága a V-cachen-nek)
Már olyat is olvastam, hogy a v-cache-nek semmi köze a Warholhoz. De olyat is, hogy a Warhol nem a B2-es stepping. Az is lehet, hogy mégis, de az is lehet, hogy az AMD csinált egy B2-es steppinget, ami képes a v-cache felépítmény fogadására, de a végleges termék a Warhol lesz 6nm-en gyártva és a 9-12% úgy jön össze - v-cache nélkül - hogy picit emelkedik a mag frekvencia és picit emelkedik a FCLK is.
Én még titkon reménykedem az új IOD-ben. Van egy olyan elméletem is, hogy a B2 stepping lesz a warhol végül, de 6nm-es IOD kapDe a lényeg, hogy innentől bármilyen hírt nehéz lesz értelmezni.
Találgatunk, aztán majd úgyis kiderül..
-
#5234
awexco
őstag
Petykemano
#5233
awexco
őstag
válasz
Petykemano
#5233
üzenetére
V-cache alsó házba túl drága . Kérdés az alkalmazásoknál mennyire fog számítani ?
I5-6600K + rx5700xt + LG 24GM77
-
#5235
HSM
félisten
Petykemano
#5233
HSM
félisten
válasz
Petykemano
#5233
üzenetére
Valamelyik APU-hoz volt írva régebben Zen3+, az pedig nem valószínű, hogy a plusz V-cache lett volna, tehát valószínűleg van még hiányzó része a kirakósnak.
 Illetve a tervek is változhattak idő közben, ezt se felejtsük el.
Illetve a tervek is változhattak idő közben, ezt se felejtsük el.[ Szerkesztve ]
-
#5236
Petykemano
veterán
awexco
#5234
Petykemano
veterán
V-cache alsó házba túl drága
Ez is egy érdekes kérdés egyébként, hogy valójában kit mit gondol alsó háznak?
Nyilvánvalóan nincs egyértelmű meghatározá. Amit látunk az régóta az, hogy az alsó-felső ház
- elsősorban feldolgozószámot jelent. Ez akár 50-100-150%-os különbség is lehet.
- kisebb részben tierenként pár százalékot jelentő eltérő maximális frekvenciát
- és az Intel sokáig láttunk kihagyott/letiltott utasításkészletetA mobil procik egyre inkább fejlődnek. Beérik, vagy beérték a desktop számítógépeket.
Legalábbis abban az értelemben, amire az átlag felhasználó használni akarja. VAnnak, akik arra készülnek, hogy kidobják a(z akármilyen kis) dobozos számítógép gondolatát és csak leteszik a telefont a monitor és a billentyűzet mellé és úgy használják. Persze AAA játékra nyilván nem megfelelő, de számlát befizetni, internetezni, excel táblázgatni kicsi helyett nagy kijelzőn és kicsi billentyűzet helyett emberi klaviatúrán elegendő.Van egy megfigyelés, amely szerint
- a mobil az új desktop
- a desktop az új workstationAz Apple-t hagyjuk, mert bár az M1 kimagasló teljesítényt nyújt, de a 300+eFt-os Mac mini semmiképp nem tartozik az alsó házba. De mondjuk mi van, ha jövőre a Qualcomm beforgatja a Nuvia fejlesztését egy az X2-nél 30-40%-kal gyorsabb processzormagba. Abból már lehetne csinálni - az Apple-nél - olcsóbb 4+4 magos miniPC-ket.
Biztos vannak páran, akiknek nem feltétlenül szükséges 16-24 mag, hanem kicsi, de fürge cpu-t szeretnének. És akkor az AMD azt fogja mondani, hogy ezekkel a 12-16 magos felsőházunk tud versenyképes lenni.
Vagy ott van pl a friss 4 magos Tiger Lake az inteltől, ami GB5-ben 1700 pontot ér el. Ehhez képest az 5600U csak valami 1300, az 5600G meg csak 1500 körül mozog.
Szóval ilyen kemény verseny mellett tényleg lehet azt mondani, hogy az alsó-felső ház nem csak magszámot jelent, hanem az egyszálas teljesítmény erőteljesebb differenciálását is?
Találgatunk, aztán majd úgyis kiderül..
-
#5237
carl18
addikt
Petykemano
#5236
carl18
addikt
válasz
Petykemano
#5236
üzenetére
Van egy megfigyelés, amely szerint
- a mobil az új desktop
- a desktop az új workstationEz egy elég jó megfigyelés, bele gondolni 12-16 mag már elérhető átlag felhasználó számára elég durva.
Az intel is idén már árulni fogja az Alder Lake-S mellet a 16 magot, az már tény hogy 8 nagy és 8 gyenge mag lesz egymás mellet.
Hát azért rengeteg youtuber/streamer lett akiknek fontos az erős cpu videózás szempontjából.Hiába szúr, itt Ryzen a úr!
-
carl18
addikt
Hiába szúr, itt Ryzen a úr!
-

wwenigma
Jómunkásember
16 nagyot nem lehetne lehuteni, csak azert.
Steam: http://bit.ly/1rRuf8p , Origin: wwenigma -- | -- Jiayu F1 / G3C / OT995 cuccok: http://bit.ly/1w44CI2 -- | -- ZTE V5 Red Bull -> http://bit.ly/1mgtfrd -- | -- Xiaomi RN3SE -> http://bit.ly/2r8DlV7 -- | -- Live Stream: twitch.tv/wwenigma
-
-
#5242
Petykemano
veterán
Petykemano
veterán
Érdekes olvasmány:
[link]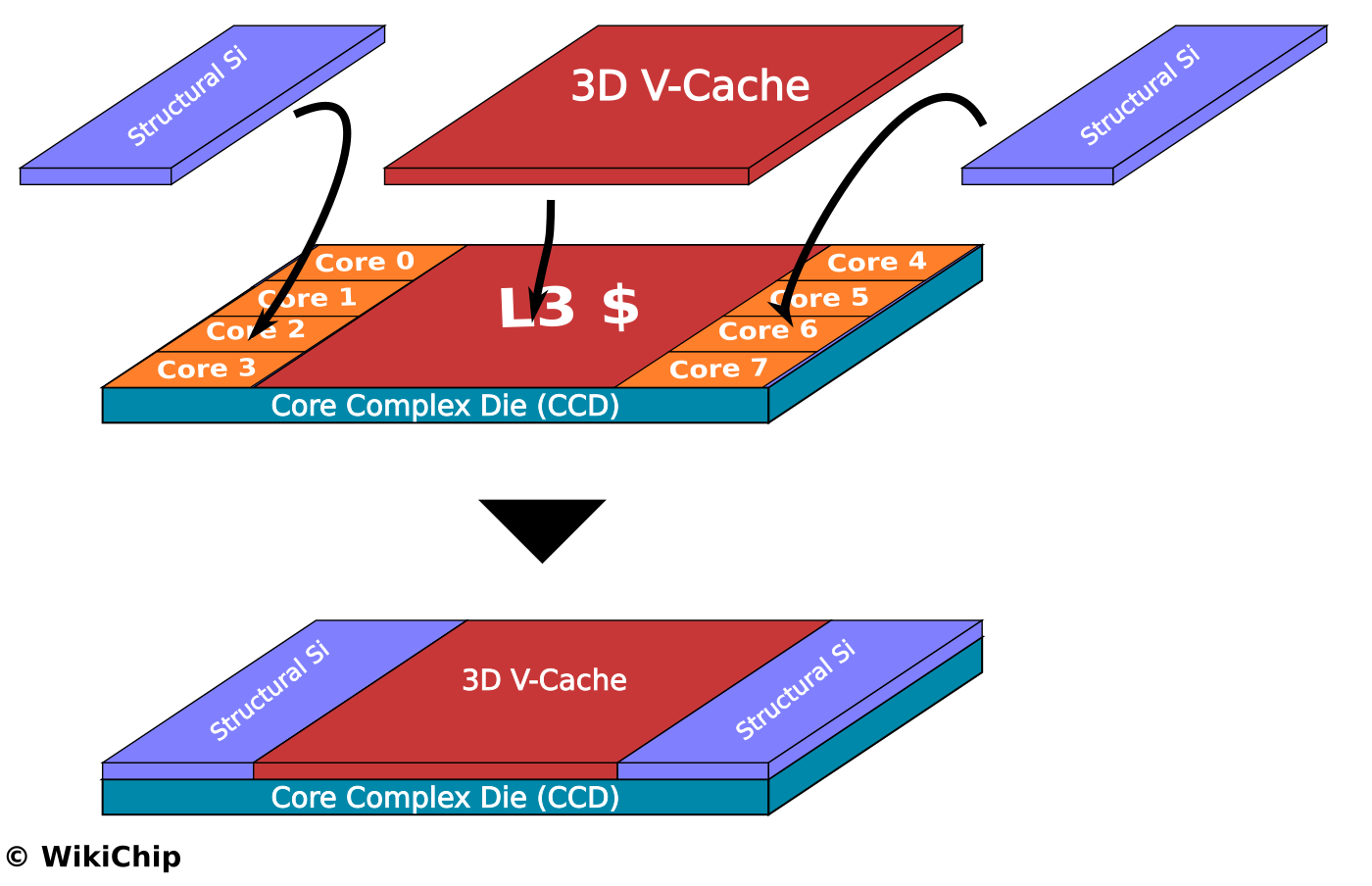
Azon gondolkodtam el, hogy vajon fogják-e lehetne-e valahogy a Structural Si elemeket hasznosítani."Schor speculates that the dummy dies may include thick copper traces to aid heat transfer. However, why not put all that copper to use? I see an opportunity to put fat vector engines in these dies. Instead of squeezing 512-bit wide SIMD units and data paths into the core below to support AVX-512, instead put (perhaps even wider) vector units in the dies above."
[link]
Az első reakció nyilván az: Hát az lehetetlen (és egyébként szentségtörés is volna), hiszen a hő a CCD-ben a logikai részeken keletkezik, amit a Structural Si fed, aminek épp az a célja, ahogy elvezesse az alul képződött hőt, nem pedig, hogy maga is hőt termeljen.De ezen az első felhorgadáson lépjünk túl.
Tényleg mi lenne, ha skálázható lenne egy chiplet. És ebben a skálázhatóságban a L3$ csak az első lépés. A structural Si minden rétege tartalmazhatna L2$-t, vagy akár L1$-t. Vagy ha már AVX, akkor lehetne úgy is, hogy minden egyes réteg tartalmaz egy AVX512 feldolgozót. Ha 4 magas a felépítmény, akkor 4xAVX512 pipeline van, ha nincs felépítmény, akkor meg egy se.
a processzor lelke persze továbbra is a CCD-ben maradna, csak az egyes részegységek elhelyezése/kiterjesztése/skálázása 3D irányban történne, ráadásul opcionálisan.Találgatunk, aztán majd úgyis kiderül..
-
#5243
S_x96x_S
őstag
Petykemano
#5242
S_x96x_S
őstag
válasz
Petykemano
#5242
üzenetére
> Tényleg mi lenne, ha skálázható lenne egy chiplet.
> És ebben a skálázhatóságban a L3$ csak az első lépés.valami lesz
habár szerintem az ARM-es design-oknak lesz egy kis előnyük a 12-es szendvich formációnál..
( kisebb fogyasztás .. kisebb hő .. kisebb gond )
És szerintem a következő Apple silicon is kaphat V-cache szerűséget."A single slide at the Technology Symposium shows it all off. TMSC is currently probing 12-Hi configurations of SoIC. Each of the dies within the 12-Hi stack has a series of through silicon vias (TSVs) in order for each layer to communicate with the rest of the layers, and the idea is that each layer could be a different element of logic, of IO, of SRAM, or could be passive to act as a thermal insulation layer between other active layers."
Mottó: "A verseny jó!"
-
#5244
 TRitON
aktív tag
TESCO-Zsömle
#5241
TRitON
aktív tag
TESCO-Zsömle
#5241
TRitON
aktív tag
válasz
 TESCO-Zsömle
#5241
üzenetére
TESCO-Zsömle
#5241
üzenetére
A magyar bruttó átlagfizetés jelenleg ~410.000Ft, ami ~273.000 nettó fizetést jelent, a medián (aminél a "keményen dolgozó kisemberek" fele kevesebbet keres) bruttó ~300.000Ft, ami nettó ~200.000Ft. Egy valamire való játék-PC összerakása (monitor nélkül) jelenleg kb. 2 havi átlag-, vagy 3-4 havi medián fizetésbe kerül; persze ez nagyban függ attól is, hogy pontosan mit szeretnénk vele játszani. Nyilván, ha átlépjük a Lajtát, ezek kb. feleződnek, de szerintem még a nyugati világban is igen durva, hogy pl. egy középkategóriás videokártyáért jelenleg 1000USD-t kérnek, egy valódi gaming PC, amin elfutkosnak a legújabb játékok, simán bele kerülhet 4-5-6.000$ba.
Egy játékkonzol lazán kijön egy havi magyar medián fizetésből is. Szóval ja, a PC gaming igen kemény luxussá vált.Mi az? 3 lába van mégsem tranzisztor? - ??? - Traffipax...
-
S_x96x_S
őstag
válasz
S_x96x_S
#5243
üzenetére
TSMC ..
June 8, 2021
An AnandTech Interview with TSMC: Dr. Kevin Zhang and Dr. Maria MarcedIC: As process nodes shrink, resistance on metal layers is becoming more problematic. With regards innovative solutions, and exotic materials versus copper interconnects, is it just a case of more research down that front? Or do we need to put more effort into increasing and routing higher metal layers?
KZ: I think in the research session at our advanced technology introduction, we did cover a little bit about the back end work. For example, we are continuing to optimize the copper grain boundary to bring a lower resistance metal line to our overall chip technology and new technology. Also, with dielectrics we continue to find innovative materials to improve the dielectric in parasitic capacitance. So, those things are being actively researched.
The 3D integration can also bring an alternative solution to this whole performance requirement in the back-end. You can instead route from A to B in a 2 dimensional space, or you can route A to B vertically in 3 dimensions. In some cases, by going vertical, you can reduce the overall length of the RC wire, and reduce pass delay significantly. So all those things have to be looked at going forward.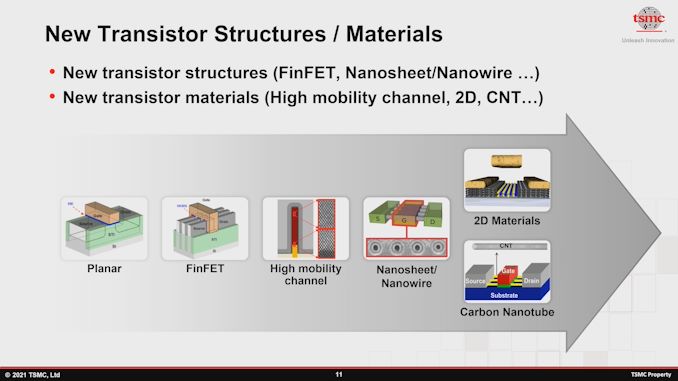
Mottó: "A verseny jó!"
-
S_x96x_S
őstag
egyes tőzsdei elemzők szerint már nem fenyegeti az Intelt az AMD ..
de majd meglátjuk .. Azért az Intelnek se lesz egyszerű dolga .."
Intel: AMD Threat Is Finished
SummaryAlthough competition from Arm is increasing, AMD remains Intel’s biggest competitor, as concerns of losing market share weigh on Intel’s valuation.
AMD's short-lived laptop competitiveness is already waning. Intel will further crush AMD with its (up to) 16-core Alder Lake: going from half the core count, to double in one generation.
Intel is also re-investing in the (high-end) desktop, could leapfrog AMD in the data center, and seems to be overtaking AMD-Xilinx for FPGA leadership.
AMD is slow to transition to the leading edge in process technology. For example, AMD will not launch 5nm laptop CPUs until 2023, when Intel might have outsourced (TSMC) 3nm.Given all the above, the Intel bear thesis of AMD benefiting from Intel's stumbles, gaining a large tech advantage and taking much market share, is finally finished.
"
a csoda-stratégia:
"
By 2023, with Meteor Lake Intel will have a "breakthrough" (as Intel called it) CPU architecture that might leapfrog AMD, perhaps reaching Intel's goal of "unquestioned leadership". Built on TSMC's 3nm and its own 7nm, it will be about half node to a full node ahead of AMD's 5nm portfolio."
Mottó: "A verseny jó!"
-
#5247
Petykemano
veterán
S_x96x_S
#5243
Petykemano
veterán
válasz
S_x96x_S
#5243
üzenetére
A hősűrűség (thermal density) eddig is fokozódó problémát jelentett.
A hősűrűség azért jelent problémát, mert magas hőmérsékleten ugyannak a frekvenciának a tartásához magasabb feszültségre van szükség, ami növeli a hőtermelést.
Nem állítom, hogy a 14nm-es zen1 frekvencia skálázódása emiatt állt meg, de amikor a 12nm-re váltottak, akkor a hírekben arra hivatkoztak a fizikai kiterjedés megtartásával kapcsolatban, hogy így több a "hely" a hőt termelő tranzisztorok között és könnyebben hűl
Valamint a zen2 esetén is szó volt róla, hogy nagyon szép és szuper, hogy milyen sűrű a 7nm-es gyártástechnológia, de az intel abból a szempontból könnyebb helyzetben van, hogy a lapkái 2x akkora kiterjedésűek, és ennélfogva engedheti meg magának a ~2x akkora fogyasztást. másként megfogalmazva: a hősűrűség miatt az AMD ha akarná se tudná növelni a fogyasztást.Szerintem a 3D technológia terjedésével ez a probléma fokozódni fog. A rétegződéssel - gondolom valamelyest növekedni fog a lapkák magassága (Az ExecutableFix által megosztott/renderelt Raphael kupak például kifejezetten magasnak tűnik) A legalsó réteg biztosan távolabb kerül a hőelvezetést szolgáló hűtött felső felülettől. Tehát szerintem egyre kevésbé lesz megengedhető, hogy neked valahol a szilícium téglatestedben - főleg alul - legyen valami nagy hőkoncentrációt okozó részegységed.
Vannak elképzelések a 3D stacked chipek Z irányú hűtésére, de azért annál szerintem lényegesen egyszerűbb, ha a hőtermelést a frekvencia csökkentésével oldják meg. a chipek ma már tele vannak hőérzékelőkkel, tehát nem gondolom, hogy bármikor is alattomosan ki tudna alakulni valami hőtermelő központ, ami leégeti a chipet.
A másik fontos szempont ami megjelenik, hogy ha valahol nagy hő képződik, akkor oda a szükséges kakaót is el kell juttatni.Számomra minden szempontból előnyösebbnek tűnik az alacsonyabb feszültség és a frekvencia és a 3D stacking által kínált cache és feldolgozó szélesítési lehetőség.
Az Apple a példa rá, hogy ebben a vonatkozásban jelenleg az Arm tűnik előnyösebb pozícióban levőnek. És arról pedig volt már szó, hogy az x86 esetén az instruction decoder szélessége tűnik jelentős korlátozó tényezőnek a feldolgozók szélesítése kapcsán.
Találgatunk, aztán majd úgyis kiderül..
-
Busterftw
veterán
válasz
S_x96x_S
#5246
üzenetére
Koszi, erdekes olvasmany.
Azert az evek soran ez latszott, hiaba volt/van (gyartas)technologiai foleny AMD-nel, kisebb volumen miatt az AMD nem tudott annyira ervenyesulni mint tudott volna normalis korulmenyek kozott.
Szerintem a korulmenyekhez kepest az Intel jol allta a sarat, mindezt ugy hogy 14nm-el kellett dolgozni. Ez latszott az evek alatt, a market share nagyon lassan kezdett megindulni AMD fele, ekozben kijott 4! Ryzen generacio.
En ezt mar az elejetol fogva mondtam, hogy az Intelnek a legfontosabb tenyezo az ido.Persze aztan ahogy lattuk, par ev alatt nagyon sok minden tud valtozni, teljesen realis, hogy a leirtak nem fognak bejonni. Az AMD sem fog egy helyben ulni.
[ Szerkesztve ]
-
#5249
Petykemano
veterán
S_x96x_S
#5246
Petykemano
veterán
válasz
S_x96x_S
#5246
üzenetére
Szerintem Arne Verheyde ugyanaz az személy, mint Twitteren witeken, aki eléggé elfogult az intel irányában.
Nem állítom, hogy nincs igazság a felsorolt pontokban.
Találgatunk, aztán majd úgyis kiderül..
-
#5250
 TESCO-Zsömle
félisten
TRitON
#5244
TESCO-Zsömle
félisten
TRitON
#5244
TESCO-Zsömle
félisten
Azzal ugye tisztában vagy, hogy a fenti statisztikából hiányzik egy csomó melós, aki rontaná a statisztikát? Nincsenek benne se a 4 fős vagy annál kisebb cégek alkalmazottai, a részmunkaidős munkavállalók, valamint a közmunka-programban résztvevők sem.
Nem mintha ez változtatna a dolgokon... Én 4 éve kevesebb, mint 2 havi béremből vettem az AMD legerősebb videókártyáját. Azóta a bérem nagyjából 40%-al nőtt, az említett kategóriájú videókártya MSRP-je pedig 100%-al*. 🤣
* - Ehhez ugye még jön a forint gyengülése is, mert az MSRP az $.
[ Szerkesztve ]
Sub-Dungeoneer lvl -57












 Nyilván azért csinálják, mert megéri csinálni.
Nyilván azért csinálják, mert megéri csinálni.




 látom - lassabb vótam ... ( de ezért itthagyom )
látom - lassabb vótam ... ( de ezért itthagyom )


 Illetve a tervek is változhattak idő közben, ezt se felejtsük el.
Illetve a tervek is változhattak idő közben, ezt se felejtsük el.







Új hozzászólás Aktív témák
- Alkalmazásbemutató: Keep
- Gaming notebook topik
- Súlyos adatvédelmi botrányba kerülhet a ChatGPT az EU-ban
- Debrecen és környéke adok-veszek-beszélgetek
- Futott egy Geekbench kört egy új HTC készülék
- Apple notebookok
- Anime filmek és sorozatok
- gban: Ingyen kellene, de tegnapra
- NVIDIA GeForce RTX 3080 / 3090 / Ti (GA102)
- Az USA vizsgálja a RISC-V kínai terjedésének kockázatát
- További aktív témák...
