Új hozzászólás Aktív témák
-
#5601
 S_x96x_S
őstag
Petykemano
#5595
S_x96x_S
őstag
Petykemano
#5595
S_x96x_S
őstag
válasz
 Petykemano
#5595
üzenetére
Petykemano
#5595
üzenetére
> Természetesen nem gondolnám, hogy konzumer piacon kapkodni
> kellene a pcie5-tel, szerintem a pcie4 ssdk pláne videokártyák
> penetrációja sem magas.én Gen5 párti vagyok..
- A CXL sok új lehetőséget ad még az erősebb desktop gépeknek is
- már a Gen4 sávszél is ki van hajtva jelenleg is az NVMe SSD-vel ..
- Latency ... Nem véletlen, hogy az Optane memóriát jelnleg a memória csatlakozóra kapcsolja az Intel .. mert jelenleg ott a legkisebb az overhead - a PCIe -hez képest.
- Latency - az Intel/nvidia biztos ki fog hozni Gen5 -ös videókártyát ..
és a latency csökkenés sok mindent kompenzálni tud.Az, hogy az AMD nem megy rá az első körben a Gen5 -re a piaci termékeknél
ott valami tesztelési probléma lehet
( A gen5 és a CXL eredetileg Intel-es javaslat ; Az Intelnek természetes előnye van )
De az is lehet, hogy a "safe choice" a Gen4 ..
és ha a Gen5 bevezetés jól halad, akkor az utolsó pillanatban válthatnak Gen5-re .. pl. a procira kötött eszközöknél.
Viszont ha valami hardveres hiba van az i/o die-ban amit nem lehet javítani, akkor marad a Gen4.Mottó: "A verseny jó!"
-
#5602
S_x96x_S
őstag
Petykemano
#5600
S_x96x_S
őstag
válasz
Petykemano
#5600
üzenetére
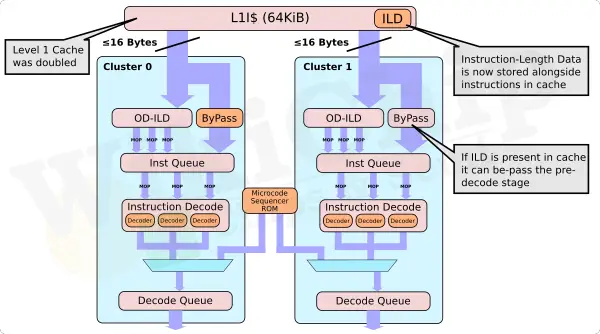
> Intel's Gracemont
érdekes.

"x86 uArch ROB Sizes"
https://fuse.wikichip.org/news/6102/intels-gracemont-small-core-eclipses-last-gen-big-core-performance/Tremont : 208Gracemont : 256 <-- gracemontSkylake : 224Sunny Cove: 352Golden Cove: 512 <-- ajövő ..Zen 2: 224Zen 3: 256 <--- Zen3Gracemont = L1i$ 64 KiB instruction cache.
Mottó: "A verseny jó!"
-
#5603
 TESCO-Zsömle
félisten
Petykemano
#5595
TESCO-Zsömle
félisten
Petykemano
#5595
TESCO-Zsömle
félisten
válasz
Petykemano
#5595
üzenetére
PCIe4/5 SSD-knek nincs értelme halandók számára. A puszta sávszélesség-növekedést csak bencsmárkok szekvenciális részeinél lehet élvezni, az IOPS meg ugyanúgy semmit nem ér, amíg a növekedés csak QD32-nél látványus, QD1-4-nél alig marad belőle valami.
Ebben volt poén a 3DXpoint, ami már QD4-nél elérte a max írás/olvasás kb 90%-át. Csak ugye az meg horror áron volt...Sub-Dungeoneer lvl -57
-
#5604
S_x96x_S
őstag
Petykemano
#5595
S_x96x_S
őstag
válasz
Petykemano
#5595
üzenetére
> A cikk szerint a Raphael csak DDR5-4800 és PCIe4 támogatást kap.
Annyi remény lehet még,
hogy az az ábra felirata, hogy "Example Block Diagram"
vagyis akár ez lehet az olcsóó A620-as lap is ..
( Az A520 -is csak Gen3-at tud )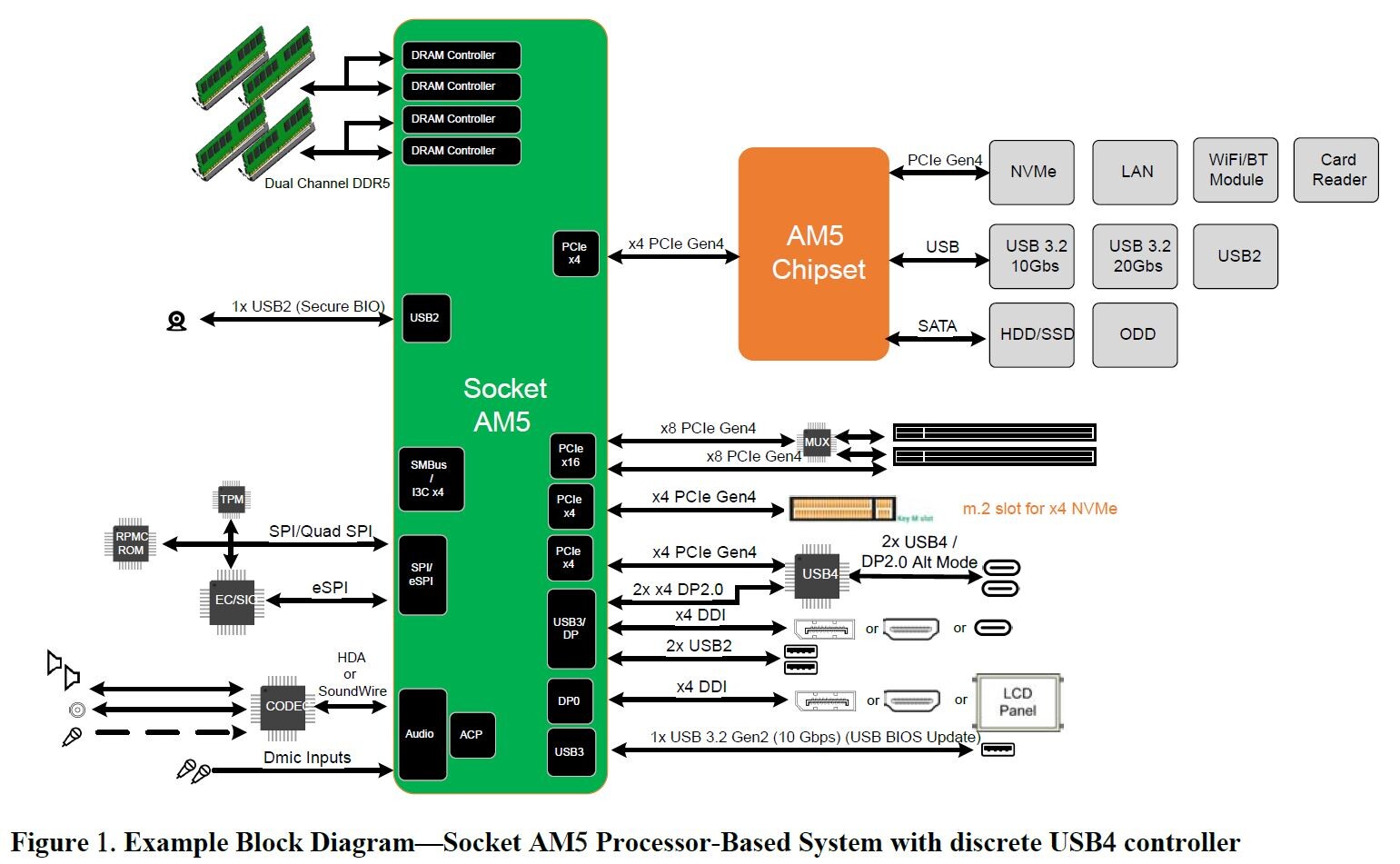
Hátha ...
Mottó: "A verseny jó!"
-
#5605
S_x96x_S
őstag
TESCO-Zsömle
#5603
S_x96x_S
őstag
válasz
 TESCO-Zsömle
#5603
üzenetére
TESCO-Zsömle
#5603
üzenetére
> PCIe4/5 SSD-knek nincs értelme halandók számára.
Workstation kategória,
Videó szerkesztés
Kiterjesztett valóság ; Spéci alacsony latenciájú 3D szemüvegek
AI ;
AdatfeldolgozásÉs pár célpiac ahol már jelenleg is gen4 -van : pl. konzol
De a közeljövőben a DirectStorage elterjedésével - Windowsra
is jön a halandóknak.És a CXL -nek is lesz haszna.
Én mindenesetre az alacsony
latenciájú olcsó Optane riválisokat várom
ami tényleg érezhető egy halandóak is.Persze nem lesz gyors átmenet..
Aki mindig 1-2 évre vesz gépet, annak nem sokat számít,
jövőre úgynúgy beszerezheti ha akarja ..de aki 5-6 évenként cserél, annak fontos lehet ..
habár az első széria mindig necces ..
Mottó: "A verseny jó!"
-
#5606
 Petykemano
veterán
S_x96x_S
#5602
Petykemano
veterán
S_x96x_S
#5602
Petykemano
veterán
válasz
 S_x96x_S
#5602
üzenetére
S_x96x_S
#5602
üzenetére
Én is azt néztem a táblázatban, hogy azokban a számokban, amiknek sokan az M1 magas IPC-jét tulajdonítják, a zen3 alacsony értékekkel rendelkezik. Persze nem mindenben.
De az a ROB pl alacsony a Sunny/Willow Cove magokhoz képest.
Ez szerintem azért jó, mert van még hová növekedni.
Persze nyilván minden egyes duplázás megtérülése IPC-ben csökkenő mértékű és külön-külön minden elhanyagolható mértékű.
Mindenesetre én is arra számítok, hogy a jövőben ezeknek az értékeknek a növekedését fogjuk látni.
Ja igen, azt elfelejtettem mondani - a másik threadben - hogy az intel IPC növekedése nagyjából a sandy bridge-től a skylake-ig azért volt szerény - összehasonlítva azzal, hogy most néhány év leforgása alatt duplázást terveznek - mert akkoriban az intel - konkurencia hiányában - a lapkaméret csökkentésére is koncentrált. (=> gyártási volumen ^^ és profit ^^)
Ami a Gracemontot illeti...
Szintén a táblázatban azt írják, hogy 2.5-ös az IPC szintje, ami kb annyi, mint a skylake és igazából csak 20%-kal (~1 generáció) van lemaradva a zen3 mögött. Nyilván nem volna jó, ha csak ebből állna egy cpu, de azért kis prüntyögőnek sem mondható.Ilyen magokból lesz 4db egy nagy mag helyén. A maximális frekvencia pedig kb 1Ghz-cel lesz lemaradva. Én arra számítok, hogy 2 Gracemont mag teljesítmény nagyjából 1 Cove mag 2 szálas teljesítményével fog felérni, viszont 4 Gracemont mag fogy annyit fogyasztani, mint 1 cove mag.
Most sokan morognak amiatt, hogy az AVX512 támogatás kikerült az Alder Lake-ből.
Fenti ábrából számomra nem derül ki, hogy a Gracemont hány és milyen méretű FPU porttal, vagy pipe-pal rendelkezik. (Egy helyet találtam, ahol azt írták, hogy a gracemont fpu port size 256b) Ha jól tudom a Zen eredetileg 4x128b volt, amivel tudott AVX2-es utasításokat végrehajtani úgy, hogy két portot összeolvasztott. Aztán ez a zen2-ben bővült 4x256b-re.
Korábban pedig beszéltünk arról, hogy az Arm SVE esetén is megoldható az, hogy egy hosszabb vektorutasítást rövidebb feldolgozóval több órajelciklus alatt hajtson végre.Remélem, hogy a raptor lake-ben megoldják, hogy AVX512 visszajöjjön
1) vagy úgy, hogy összeolvasztással, vagy több órajelciklus alatt történő végrehajtással.
De szimpatikus lenne egy olyan megközelítés, mint a zené, hogy 4x128bit a feldolgozó képessége, amivel lightweight taskokat gyorsan tud kiszolgálni, de kompatibilis tudna maradni akár AVX512 utasításokkal egy órajelciklus alatt is.2) Nem tudom, emlékszel, hogy az új Low-power Arm magoknál a "Compex" kifejezésre
[link]
Lényegében az amd bulldozer köszönt vissza: megosztott, összeolvasztható FPU
Na ez még elég ütős lenneTalálgatunk, aztán majd úgyis kiderül..
-
#5607
TESCO-Zsömle
félisten
S_x96x_S
#5605
TESCO-Zsömle
félisten
válasz
S_x96x_S
#5605
üzenetére
"Workstation kategória,
Videó szerkesztés
Kiterjesztett valóság ; Spéci alacsony latenciájú 3D szemüvegek
AI ;
Adatfeldolgozás"
Tipikus dolgok, amiket 8-12 óra szalag/üzletkötés után csinálni szeretnek az emberek, mint kikapcsolódás.
De most komolyan, mennyit nyersz késleltetésben PCIe3-hoz képest nem munka-célú felhasználás alatt?
Optane persze hogy érezhető, azt írtam én is, mert számottevően jobban skálázódik, mint a NAND. Ez azért érezhető különbség:
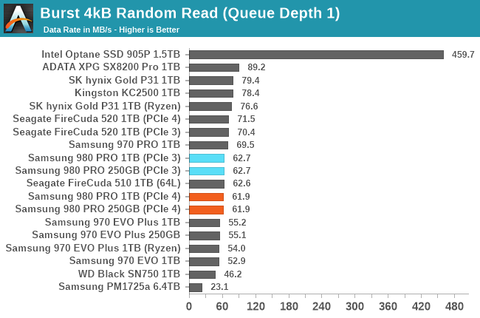
De mikor megnéze legy új PCIe4-es NVME tesztet, ahol játékok betöltése, alkalmazások indítása közt van 1mp szünet, ott megvakarod a fejed, hogy akkor azért most le akarsz-e szurkolni annyi pénzt.
Sub-Dungeoneer lvl -57
-
#5608
S_x96x_S
őstag
TESCO-Zsömle
#5607
S_x96x_S
őstag
válasz
TESCO-Zsömle
#5607
üzenetére
> De most komolyan, mennyit nyersz késleltetésben
> PCIe3-hoz képest nem munka-célú felhasználás alatt?Win11 DirectStorage
https://www.pcgamer.com/windows-11-directstorage-windows-10/
persze aki ezután is aknakeresőzik vagy passziánszozik..
azoknak nem lesz érzehető sebesség.és GPU szinten :
alapból Coherens Multi-GPU támogatás lehetősége.
Vagyis csak tolod be a GPU-kat mint most a RAMokat - és a GPU-k összekapcsolják magukat.
Persze ez egy gyenguszabb MCM szerű dolog lesz,
de mégis .. lehet, hogy 2 olcsó kártyával ár/teljesítménybe le lehet nyomni a bitang drága 3090TI utódját.persze ez majd a Gen6-nál lesz igazán ütős.
"If CXL can seamlessly scale GPUs, then the economics of the market would also change completely. People would be able to buy a cheaper GPU first and then simply add another one if they want more power. It would add much more flexibility in buying decisions and even alleviate buyers remorse to some extent for the gaming class. If CXL mode trickles down to the consumer level anytime soon, then we might even see motherboard designs change drastically as multiple sockets and multiple GPUs become a feasible option. Needless to say, it looks like things are going to get pretty exciting in a few years."
https://wccftech.com/intel-xe-coherent-multi-gpu-cxl/Ezen kivül szerintem az Intel biztos készül valami ütős - spéci
Gen5-re kihegyezett játékdemóval,
ami csili vili .. és most még csak az új Intel CPU -val és GPU -val megy.
De szerintem játékokban is kimérhető lesz a Gen5 latency csükkentése.[ Szerkesztve ]
Mottó: "A verseny jó!"
-
#5609
TESCO-Zsömle
félisten
S_x96x_S
#5608
TESCO-Zsömle
félisten
válasz
S_x96x_S
#5608
üzenetére
Értam, amit mondasz, csak nem az én kérdésemre ad választ. A DirectStorage nem a PCIe3 és PCIe4/5 közötti késleltetés-különbség miatt működik, hanem mert az adatfolyam útjából kivágják a CPU-t.
A koherens multi-GPU-t meg már lobogtatják egy ideje, kezdve a Lucid Hydra-val, ahol konkrétan eltérő gyártókat/architektúrákat is lehetett vegyíteni, csa kaztán mégse...
Ne érts félre, örülnék, ha lenne a dologból bármi is, csak ugye anno, mikor bejött a 3D, mint olyan, lobogtatták, hogy a multi-GPU rendszerek milyen jók lesznek, mert beteszel két egyforma GPU-t és az egyik az egyik szemet, a másik a másik szemet számolja... Aztán ugyanezt belengették, mikor az Oculus megjelent, hogy majd a VR milyen jó lesz, mert nem kell egy GPU-nak számolnia az irdatlan FPS-t és felbontást, mehet a két szem képe két külön GPU-ra... Azóta már a multi-GPU is -kvázi- megszűnt, az említett megoldásokból pedig soha nem lett semmi.
[ Szerkesztve ]
Sub-Dungeoneer lvl -57
-
#5610
 hokuszpk
nagyúr
TESCO-Zsömle
#5609
hokuszpk
nagyúr
TESCO-Zsömle
#5609
hokuszpk
nagyúr
válasz
TESCO-Zsömle
#5609
üzenetére
"lobogtatták, hogy a multi-GPU rendszerek milyen jók lesznek, mert beteszel két egyforma GPU-t és az egyik az egyik szemet, a másik a másik szemet számolja..."
de most az lesz, hogy az egyik szamolja a kepkockat, a masik felskalaz

* ja ezt már elsütöttem valaholElső AMD-m - a 65-ös - a seregben volt...
-
#5611
S_x96x_S
őstag
TESCO-Zsömle
#5609
S_x96x_S
őstag
válasz
TESCO-Zsömle
#5609
üzenetére
> Értam, amit mondasz, csak nem az én kérdésemre ad választ.
> A DirectStorage nem a PCIe3 és PCIe4/5 közötti
> késleltetés-különbség miatt működik,
> hanem mert az adatfolyam útjából kivágják a CPU-t.A DirecStorage csak egy csoportosító név - ami ad egy egységes API-t
de hogy alatta szoftveres vagy hardveres implementáció van,
az már a "gyártóra" van bízva.A PS5 és az MS konzolnál - az AMD megoldotta az APU-val a koherenciát és a szikronizációt.
Mind a szoftver - mind a hardver össze van csiszolva.De hiába van a konzoloknál és a szervereknél
az AMD-nek a házi Infinity Fabric megoldása a CPU-GPU -ra ;
csak azzal az nVidia GPU nem tud mit kezdeni - mert zárt.
De még az AMD direkt GPU -ra se optimális - annyira mint lehetne, mert Gen4 - és ennek még mindig magas a latency-je.Persze papíron az nVidiának is van direktStorage támogatása;
de majd a benchmarkok kimutatják az eltéréseket.
Lásd 1 éve bejelentett nVidia RTX IO-t - tuti, hogy a régi PCIe 3/4 visszafogja. és a CXL -el meglódul majd ..De amúgy bármilyen 2 kütyü szinkronizálásához
- nem árt az alacsony késleltetés. 2 GPU-nál különösen;
És itt a Gen5-nél komolyan hozzányultak
és eléggé szigorúra vették a latency-t.És nem árt, hogyha a NVMe diszk rálát a GPU memóriájára - mert akkor közvetlenül oda be tudja tölteni a tartalmat.
és a betöltésnél se árt a gyors szinkronizálás.A "Latency" sokat számít - főleg a szűk keresztmetszetnél.
és a CXL ad valami szabványosítást.
valami hardveres alapot ...

Mottó: "A verseny jó!"
-
S_x96x_S
őstag
AMD 3D V-Cache for Ryzen CPUs has 9 micro pitch bonds
In Hot Chips 33 presentation AMD outlines the future of 3D stacking technology, also sharing first details on its 3D V-Cache stacking.
https://videocardz.com/newz/amd-3d-v-cache-uses-9-micron-pitch-bonds-the-future-of-3d-stacking-is-circuit-slicingpár slide - izelitőnek:

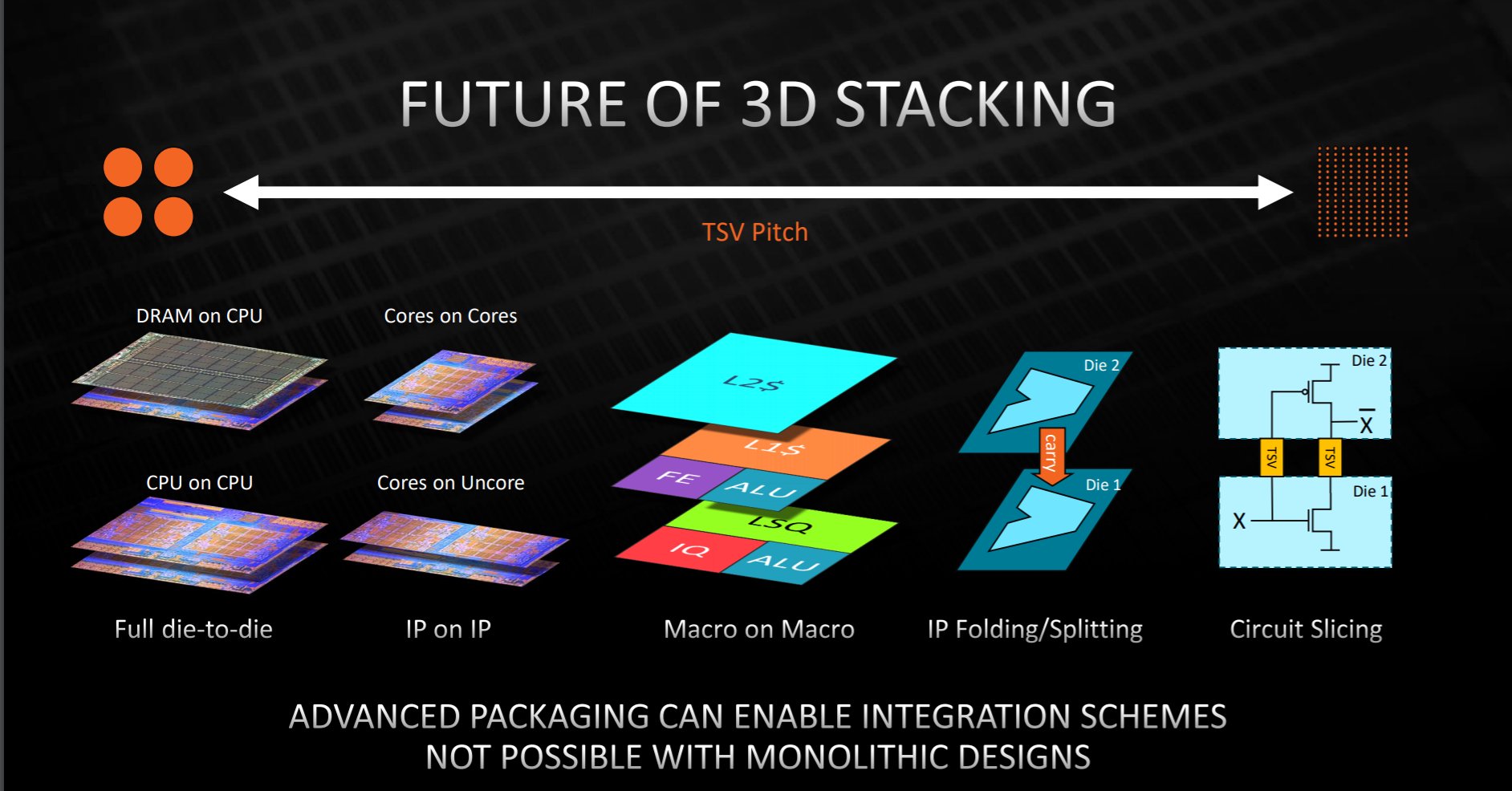
Mottó: "A verseny jó!"
-
S_x96x_S
őstag
DIY TR laptop
"AMD’S THREADRIPPER IS THE BEATING, HEATING HEART OF “MOST POWERFUL” DIY LAPTOP"
https://hackaday.com/2021/01/22/amds-threadripper-is-the-beating-heating-heart-of-most-powerful-diy-laptop/van videó is..

Mottó: "A verseny jó!"
-
S_x96x_S
őstag
remélem filléres cucc lesz ez is ..
-------------
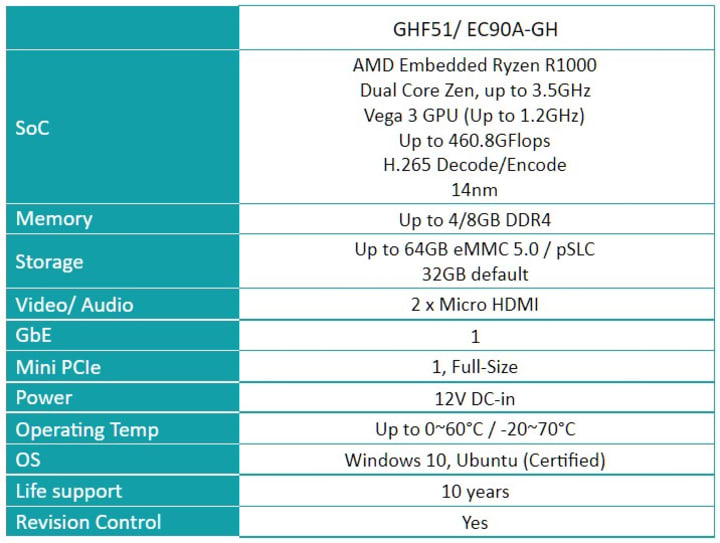
Canonical and DFI launch the first Ubuntu certified AMD-based “Industrial Pi”
on 19 August 2021
https://ubuntu.com//blog/canonical-and-dfi-launch-the-first-ubuntu-certified-amd-based-industrial-pi


Mottó: "A verseny jó!"
-
S_x96x_S
őstag
New Dynamics: Meet TSMC’s Top 3 Customers
- Apple
- AMD
- Mediatek
https://techtaiwan.com/20210818/tsmc-apple-amd-mediatek/"
Beyond Apple, TSMC’s 2nd and 3rd largest customers have recently changed. For risk diversification, Nvidia and Qualcomm are sourcing from both TSMC and Samsung, and their places are filled by AMD and MediaTek.TSMC’s advanced 7nm node was key to AMD’s recent success in catching up with Intel: AMD released its Zen 2-based Ryzen 3000 processor in 2019, when Intel was still struggling with its 10nm and 7nm processes. Undoubtedly, AMD will continue its partnership with TSMC to maintain its edge. The company will continue to use TSMC’s 7nm process until the release of its Zen 4 core, which will use the 5nm process. In fact, AMD has come to be TSMC’s largest client in terms of the 7nm process. With AMD seeking to gain a larger share in the server market (some estimations suggest a 25-30% share in 2023) and its acquisition of Xilinx, another user of TSMC’s advanced nodes, it is expected that AMD will remain TSMC’s 2nd largest customer all the way through 2021. "
Mottó: "A verseny jó!"
-

awexco
őstag
válasz
S_x96x_S
#5615
üzenetére
Intelnek ha a gyártásra elköltött durva pénzösszegekből profitot is akar látni és képesek lesznek élvonalbeli gyártás technológiával előrukkolni akkor át kell magához csábítani az AMD-t . Apple az már sokkal keményebb dió mert ott lehet valami durva háttéralku , hogy a legfejlettebb gyártósorok nagyon nagy részét csak ő kaphassa .
I5-6600K + rx5700xt + LG 24GM77
-
S_x96x_S
őstag
> Intelnek .. át kell magához csábítani az AMD-t .
A Samsungnak se sikerült, pedig biztos próbálkozott ..
Az egyetlen AMD-Samusung közös projekt lényegében
a Radeon átkonvertálása Samsung-ARM technológiára.
Az nVidiát viszont a Samsungnak sikerült részben átcsábítania.
Amíg az Intel - le nem választja a Foundry üzemét,
addig nem sok remény van az AMD megszerzésére.Persze a GloFo - Intel általi bekebelezésével változhat a helyzet ...
Mottó: "A verseny jó!"
-
hokuszpk
nagyúr
teljesen kizart. ha az Intelnek lesz a TSMChez hasonloan jo technologiaja, majd hulye lenne nem a sajat processzorait gyartani rajta. Pont az AMD peldaja mutatta meg, hogy a jobb gyartastechnologian ( 28 -> 14 aztan a 14 -> 7 ) mennyivel versenykepesebb procikat lehet csinalni.
Első AMD-m - a 65-ös - a seregben volt...
-
#5619
TESCO-Zsömle
félisten
hokuszpk
#5618
TESCO-Zsömle
félisten
válasz
 hokuszpk
#5618
üzenetére
hokuszpk
#5618
üzenetére
Ugyanakkor azt is érdemes figyelembe venni, hogy pusztán a számok nem jelentenek semmit. Intel jelenlegi 10nm-e elvileg jobb, mint a TSMC7. Csak a kapacitással vannak/voltak bajok. Érdemes megnézni a videó-sorozatot, amiben Der8auer elektronmikroszkóppal vizsgál Intel és AMD procikat a valódi csíkszélesség és tranzisztormagasság/-sűrűség megállapítása érdekében.
Tényleg kéne már valami új jelölés, mert ez az 'X' nm utoljára talán 130-nél volt valós érték. Attól lefele már csak arányszám, 45-től lefele meg már tényleg csak marketing-fogás. Semmire nem jó.
[ Szerkesztve ]
Sub-Dungeoneer lvl -57
-
#5620
hokuszpk
nagyúr
TESCO-Zsömle
#5619
hokuszpk
nagyúr
válasz
TESCO-Zsömle
#5619
üzenetére
a kapacitassal azert voltak/vannak bajok, mert gyatra volt a kihozatal, kb. mondhatni alig mukodott a node. de ha olyan vagy jobb lesz, mint a TSMC, akkor az Intel procik is ugranak egy nagyot perf / wattban, azaz minden téren újra vesenyben lesz az Intel ; akkor meg minek a konkurrencianak gyartani ?
Első AMD-m - a 65-ös - a seregben volt...
-
#5621
Petykemano
veterán
TESCO-Zsömle
#5619
Petykemano
veterán
válasz
TESCO-Zsömle
#5619
üzenetére
van új jelölés: Intel 7
[ Szerkesztve ]
Találgatunk, aztán majd úgyis kiderül..
-
#5622
Petykemano
veterán
Petykemano
veterán
Úgy tűnik, hogy a zen4 ismét csak egy iteráció, nem szakít a tradícionális felépítéssel, zen-egyensúllyal.
Úgy tűnik, hogy a zen4 fejlesztése az AVX512 implementálása köré épült, nagyjából hasonlónak lehetünk majd szemtanúi, mint a zen2 esetében.[ Szerkesztve ]
Találgatunk, aztán majd úgyis kiderül..
-
#5623
S_x96x_S
őstag
Petykemano
#5622
S_x96x_S
őstag
válasz
Petykemano
#5622
üzenetére
AM5: A PCIe Gen5 és CXL -et leszámítva azért korrekt előrelépés.
Genoa: itt legalább lesz Gen5!Spekuláció: ZEN4 alapú Threadripper: remélem itt is lesz gen5+CXL és lesz relative olcsó 16 magos proci + alaplap : mert akkor megbékélek ..
Azért az Intel tuti ki fog hozni Gen5-ös videókártyát és Optane diszket is.
> Úgy tűnik, hogy a zen4 fejlesztése
> az AVX512 implementálása köré épült,remélem, hogy azt legalább jól implementálták.
Ha igen, akkor a sima AVX2 - teljesítmény is nagyobb lesz.persze a jövőben - az AMD-nek is meg kell oldania - az AVX-512 - Big-Little architektúrát ( remélhetőleg nem kiherélten - mint az Intel Alder Lake )
[ Szerkesztve ]
Mottó: "A verseny jó!"
-
#5624
Petykemano
veterán
S_x96x_S
#5623
Petykemano
veterán
válasz
S_x96x_S
#5623
üzenetére
> persze a jövőben - az AMD-nek is meg kell oldania - az AVX-512 - Big-Little architektúrát
> ( remélhetőleg nem kiherélten - mint az Intel Alder Lake )Nekem nem lenne bajom azzal, ha csak a kompatibilitás végett úgy oldanák meg ,hogy 128 bites feldolgozók vannak a kis magokban és 4 órajelciklus alatt hajt végre egy AVX512-es utasítást.
De szerintem nem ez lesz.Találgatunk, aztán majd úgyis kiderül..
-
#5625
S_x96x_S
őstag
Petykemano
#5624
S_x96x_S
őstag
válasz
Petykemano
#5624
üzenetére
> AVX512-
valószinüleg a ZEN4 -ből lesz majd a "little" - a ZEN5-nél.
kérdés, hogy teljes ZEn4 lesz, vagy kiherélt.Mottó: "A verseny jó!"
-
#5626
TESCO-Zsömle
félisten
Petykemano
#5621
TESCO-Zsömle
félisten
válasz
Petykemano
#5621
üzenetére
Az nem új jelölés, hanem egy ugyanolyan marketing név, mint a TSMC N7.
Sub-Dungeoneer lvl -57
-
#5627
Petykemano
veterán
S_x96x_S
#5625
Petykemano
veterán
válasz
S_x96x_S
#5625
üzenetére
Ahogy a Ch&Ch elemzésben is írták, a zen4 fundamentálisan nem különbözik a zen3-tól. AZ AVX512 utasításcsalád és a 256bit helyett 512bites feldolgozók persze a vektor egységen nagy előrelépésnek számít, de más vonatkozásban inkább csak csiszolgatás-reszelgetés.
A viszonylag jelentősnek mondható L2$ méretnövekedését is e kettő kategóriába sorolnám. Úgy értem, hogy el tudom képzelni, hogy ezzel a cél nem az IPC gyorsítás volt - Na nem mintha nem nőne tőle az IPC -, hanem elsősorban a duplázódó adatméretek tették indokolttá.
Példaként a Golden Cove magokat szokták felhozni, reszelgetés (+10%) helyett elég komoly (+50+%) méretnövekedésen esnek át bizonyos alegységek, mint pl a reorder buffer. De ahogy a múltkor is mondtam, ha a zenből e nélkül is lehet IPC növekedést elérni az jó jel, mert arra enged következtetni, hogy van még benne tartalék.
Engem amúgy meglepett, hogy az L1$-t egyáltalán nem növelték. Én arra számítottam, hogy 48kB-ra nő az is.
Találgatunk, aztán majd úgyis kiderül..
-
S_x96x_S
őstag
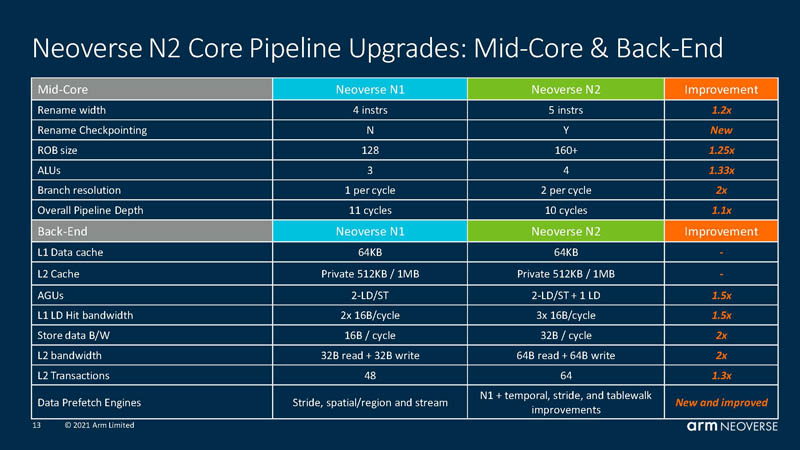
Kemény menet várható az X86 vs ARM vonalon.
Versenytárs: Arm Neoverse N2
+40% IPC performance uplift
DDR5, HBM3, PCIe Gen5, CXL 2.0, CCIX 2.0, 5nm,
CMN-700 : max 256 core/die
https://www.servethehome.com/arm-neoverse-n2-at-hot-chips-33/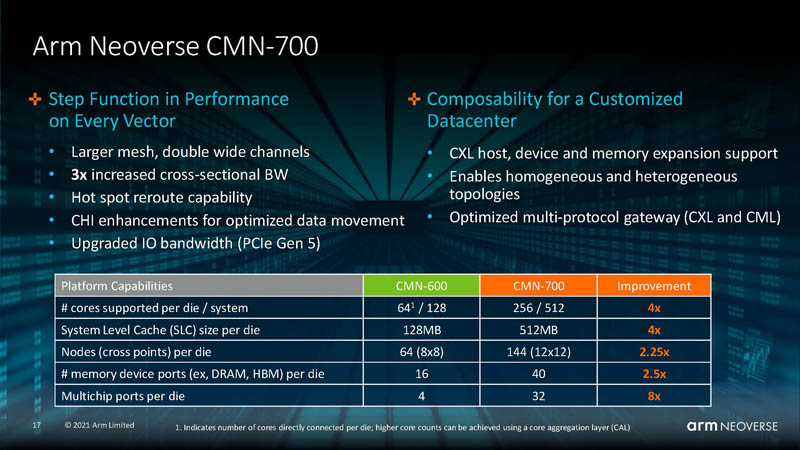
Mottó: "A verseny jó!"
-
#5629
S_x96x_S
őstag
Petykemano
#5627
S_x96x_S
őstag
válasz
Petykemano
#5627
üzenetére
> a zen4 fundamentálisan nem különbözik a zen3-tól.
Ha az AVX-512 mellett
más - megfogható teljesítménynövekedést hoz,
akkor szerintem hozza a kötelezőt.
És szerintem min +10% IPC csak össze tudnak kaparniElég nagy változás önmagában
az AVX-512 kielégítő implementálása.
( mert az Inteltől láttunk nem annyira pöpec implementációkat, amikor pl. visszavett az órajelből avx-512 utasításoknál )
Míg az Intel már a sokadik AVX-512 -öt csiszolgatja, az AMD-nek rögtön nekifutásból - egy versenyképes architektúrát kell kinyomnia, ami felveszi a versenyt az Intellel.> Engem amúgy meglepett, hogy az L1$-t egyáltalán nem növelték.
a 2két X86-os cég teljesen eltérő ciklusban fejleszt és dobja ki
az új architektúrákat.Más stratégia -> más roadmap.
Meg amúgy az Intel - szinte minden lehetséges újdonságot betolt a mostani magokba ( néha átgondolatlanul )
kockázati lépéskényszerben voltak - nem volt más választásuk.Mottó: "A verseny jó!"
-
#5630
S_x96x_S
őstag
Petykemano
#5627
S_x96x_S
őstag
válasz
Petykemano
#5627
üzenetére
> Ahogy a Ch&Ch elemzésben is írták,
újra olvasva :
"Genoa supports AVX-512F, VL, BW, CD, IFMA, DQ, VPOPCNTDQ, BITALG, VNNI, VBMI, VBMI2, and BF16 (bfloat16) which puts it at roughly
an AVX512 featureset level of Ice Lake Server in terms of AVX512 exclusive instructions."
"Personally, I think Zen 4 might have a single 512-bit FMA unit that can be addressed as 1×512 or 2×256, in a setup similar to Sunny Cove’s. "megjegyzés:
Ha igaz az 1x FMA ..
és az "Ice Lake Xeons" - nak 2x FMA -ja van ;
( "Two AVX-512 FMA units per CPU core ")
Akkor a ZEN4-ben fele annyi lesz.Mottó: "A verseny jó!"
-
#5631
Petykemano
veterán
S_x96x_S
#5628
Petykemano
veterán
válasz
S_x96x_S
#5628
üzenetére
Az N2 sok szempontól vastagabbnak tűnik, mint a zen3, más szempontból viszont nem. [link]
És mégis nagyon pici.Mondjuk nehéz összehasonlítani.
7nm-en 1.1-1.4mm2 az N1 [link]
Ehhez képest a zen3 brutálisan nagy, több mint 3mm2 [link]
(A számok csak a core részeket tartalmazzák)
Persze az IPC-je is másfélszeres és nyilván az elérhető frekvenciában is jelentős különbség van [link]az N2 kiterjedése 5nm-en nem változott az N1-hez képest.
Elvileg egyébként a zen4 lapkaméret is csökkent. Ha jól emlékszem olyan 70mm2 - annak ellenére, hogy az L2 a duplájára nőtt és az AVX512 is eléggé helyigényes - azt mondják 0.5mm2 a core részből csak az.> És szerintem min +10% IPC csak össze tudnak kaparni
> Elég nagy változás önmagában
> az AVX-512 kielégítő implementálása.Nem kívántam lekicsinyleni. Csupán megállapítottam, hogy ha volt egy design goal listájuk a zen4-re vonatkozóan, akkor annak első helyén az AVX512 implementálása lehetett. Emellett persze nyilván dolgoznak,csiszolnak-reszelnek más részegységeket is és ha valamilyen fejlesztés elkészül, akkor az bekerülhet a release-be. (ahogy anno a zen2-be is bekerült valami Tage branch predictort, amit eredetileg a zen3-ba terveztek)
Szerintem 10%-nál több lesz az IPC növekedés - a szokásos módon ahol az L2$ számít, ott nagyobb.
> Akkor a ZEN4-ben fele annyi lesz.
De dupla annyi mag.Lehet, hogy innen érdemes ágaztatni.
A zen5 újdonsága lehet, hogy az lesz, hogy a backend szélesedik.[ Szerkesztve ]
Találgatunk, aztán majd úgyis kiderül..
-
#5632
Petykemano
veterán
Petykemano
veterán
Már a zen2-t is felkészítették V-cache fogadására
A Warholt akkor kaszálhatták el, amikor sikerült összerakni.[ Szerkesztve ]
Találgatunk, aztán majd úgyis kiderül..
-
#5633
S_x96x_S
őstag
Petykemano
#5631
S_x96x_S
őstag
válasz
Petykemano
#5631
üzenetére
>> Akkor a ZEN4-ben fele annyi lesz.
>De dupla annyi mag.necess lesz.
a Sapphire Rapids Xeon - max 56 magos lesz / foglalat
.. és hamarabb kijön, mint a Genoa ( max 96 core )de főleg a core alapján licenszelt szoftvereknél lehet ez hátrány.
valami árazással ki kell egyensúlyozni.[ Szerkesztve ]
Mottó: "A verseny jó!"
-
#5634
 HSM
félisten
Petykemano
#5624
HSM
félisten
Petykemano
#5624
HSM
félisten
válasz
Petykemano
#5624
üzenetére
Pedig ez tűnik a legjobb megoldásnak. A kis mag utasítás szinten kompatibilis az AVX512-vel is, csak csiga lassú, ha tempó is kell, majd átrakja az ütemező a nagyobb magokra.
#5627 Petykemano :"reszelgetés (+10%) helyett elég komoly (+50+%) méretnövekedésen esnek át bizonyos alegységek"
Szerintem itt lényeges szempont, hogy mi lehetett a cél a fejlesztésnél. Az első Core architektúrák után a cél kb. a Skylake-ig az volt, hogy a mobil chipek terén legyen jelentős az előrelépés, ez volt a tervezési filozófia, hogy csak akkor építettek be valamit, ha hatékonyságban is jó volt. Nekem úgy tűnik, hogy ezt most már máshogy gondolják, a nagy magba menjen minden, amit elbír a gyártástechnológia, a hatékonyság meg majd jön a sok kis magból.#5629 S_x96x_S : "( mert az Inteltől láttunk nem annyira pöpec implementációkat, amikor pl. visszavett az órajelből avx-512 utasításoknál )"
Így volt ez az AVX2-nél is. A gyakorlatban viszont ebből nem igazán láttam problémát, nem dupla olyan gyors lett az AVX2 kód, csak mondjuk 80%-ot gyorsult.
Ami gondot okozhatott, hogy a maradék magokon is így csökkent a nem-AVX-es kódoknak elérhető órajel, de ezek már nagyon apróságok.
#5630 S_x96x_S :"Personally, I think Zen 4 might have a single 512-bit FMA unit that can be addressed as 1×512 or 2×256, in a setup similar to Sunny Cove’s."
Nekem tetszene, ha ez lenne a megvalósítás. Nem gondolom, hogy jót tenne a csipnek más aspektusokból, ha túlizmosítanák a vektorfeldolgozókat, a jelenlegi Zen-nek is tetszik a kiegyensúlyozottan jó teljesítménye. -
#5635
Petykemano
veterán
S_x96x_S
#5633
Petykemano
veterán
válasz
S_x96x_S
#5633
üzenetére
> de főleg a core alapján licenszelt szoftvereknél lehet ez hátrány.
> valami árazással ki kell egyensúlyozni.Nem tudom, hogy a sapphire rapids esetén az AVX512 használata jár-e még órajelcsökkentéssel. De ha esetleg az AMD megoldotta - ahogy az AVX2 esetén is tette - hogy órajelcsökkenés nélkül tudja a mag használni, akkor már az is kompenzálhatja azt, hogy kevesebb az 512b feldolgozó.
> #5634 HSM
> Pedig ez tűnik a legjobb megoldásnak.
> A kis mag utasítás szinten kompatibilis az AVX512-vel is, csak csiga lassú,
> ha tempó is kell, majd átrakja az ütemező a nagyobb magokra.Szerintem azért nem így lesz (kis mag érti az AVX512 utasítást, de vékony feldolgozókkal rendelkezik és egy AVX512 utasítást több órajelciklus alatt tud csak végrehajtani), mert az Intel számára az E mag nem Low Power, amely esetén kényszerből, de minél olcsóbban megvalósítják a utasítás-parítást. Az E magokat az intel throughputra akarja használni.
Nem tudom megmondani, hogy mi az ideális, de azt feltételezem, hogy nem a minimum. Nyilván attól is függ, hogy milyen a kód, amit futtatni kell.
Jelenleg a Gracemont magok AVX2-ot tudnak, elvileg 256b feldolgozókkalTalálgatunk, aztán majd úgyis kiderül..
-
#5636
HSM
félisten
Petykemano
#5635
HSM
félisten
válasz
Petykemano
#5635
üzenetére
"Az E magokat az intel throughputra akarja használni."
Szvsz nincs ellentmondás. A kulcs itt szerintem, hogy adott lapkaméreten belül a legjobb throughput. Tehát lehet, csak negyed tempóval aprítaná az AVX512-t, de ha ebből 4 elfér egy nagy mag helyén már lehet nyertél...
Aldernél szerintem nagy öngól, hogy a kis mag semmilyen formában nem eszi meg az AVX512-t, így a nagy mag ilyen tudása teljesen kihasználhatatlan marad. -

wwenigma
Jómunkásember
válasz
hokuszpk
#5637
üzenetére
Bennem az merült fel hogy "hány magosnak" fogják árulni és mit jelent a teljes értékű mag, ugye ott is belekötöttek ebbe...
Steam: http://bit.ly/1rRuf8p , Origin: wwenigma -- | -- Jiayu F1 / G3C / OT995 cuccok: http://bit.ly/1w44CI2 -- | -- ZTE V5 Red Bull -> http://bit.ly/1mgtfrd -- | -- Xiaomi RN3SE -> http://bit.ly/2r8DlV7 -- | -- Live Stream: twitch.tv/wwenigma
-
HSM
félisten
válasz
hokuszpk
#5637
üzenetére
Akár az is opció lehet szvsz.

#5638 wwenigma : Ez a "hány magos" kérdés régóta nem egyértelmű sajnos. A Bulldozer is nézőpont kérdése, 4 vagy 8 magosnak tekinted, de a Zen-eknél is bizonyos kódokak igencsak árt, ha át kell nyúlkálni a szomszédos CCX-ekbe, tehát ott is bejött a "nézőpont kérdése", hány magot tudsz hatékonyan használni a különféle alkalmazásokban. Aztán persze most már a kékek is beálltak a sorba az Alder Lake-el.
 Valószínűleg itt is más, mélyebb metrikák után kell majd nézni, ahogy a gyártástechnológiai elnevezéseknél is volt. A user meg csak vakargathatja majd a fejét.
Valószínűleg itt is más, mélyebb metrikák után kell majd nézni, ahogy a gyártástechnológiai elnevezéseknél is volt. A user meg csak vakargathatja majd a fejét. 
-
#5640
Petykemano
veterán
Petykemano
veterán
AMD Storm Peak [link]
Ami furi, mert a zen3 TR-nek Genesis peak a neve elvileg. [link]AMD EPYC 7T83 [link]
100-000000348
Egy újabb egyedi EPYC.
Talán csak nem az új az intel-féle aurora helyett épülő AMD-Nvidia szupercomputer?7773X 64C [link]
100-000000504
Milan-X[ Szerkesztve ]
Találgatunk, aztán majd úgyis kiderül..
-
#5641
Petykemano
veterán
Petykemano
#5640
Petykemano
veterán
válasz
Petykemano
#5640
üzenetére
Találgatunk, aztán majd úgyis kiderül..
-
#5642
hokuszpk
nagyúr
Petykemano
#5640
hokuszpk
nagyúr
válasz
Petykemano
#5640
üzenetére
"Milan-X"
aljas rágalom. a Milan most hétvégén idegenben győzött, tehát "2" volt a helyes tipp.
Első AMD-m - a 65-ös - a seregben volt...
-
#5643
S_x96x_S
őstag
Petykemano
#5640
S_x96x_S
őstag
válasz
Petykemano
#5640
üzenetére
> Talán csak nem az új az intel-féle aurora helyett épülő AMD-Nvidia szupercomputer?
" New DoE Argonne Polaris Supercomputer Features HPE AMD and NVIDIA"
https://www.servethehome.com/new-doe-argonne-polaris-supercomputer-features-hpe-amd-and-nvidia/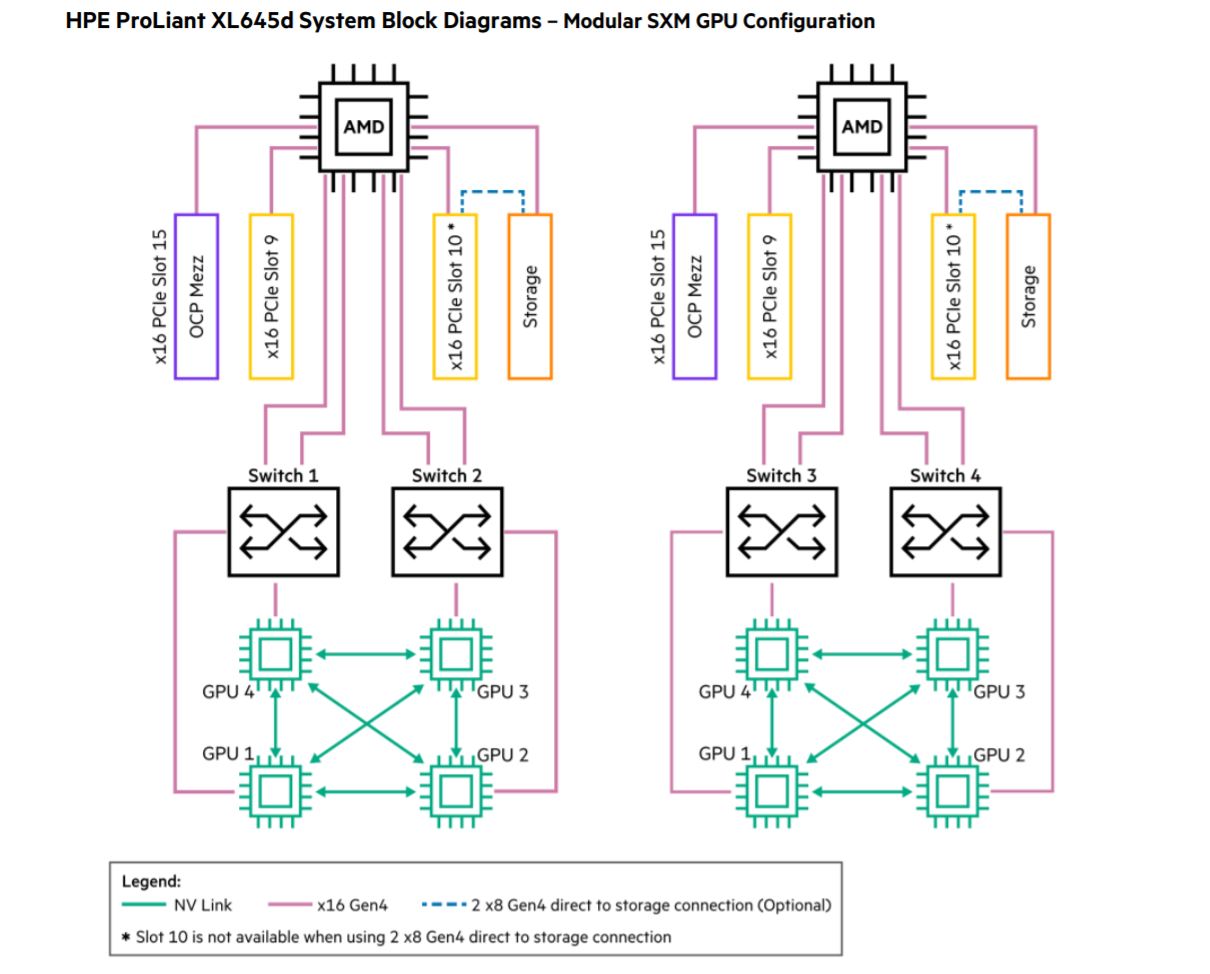
Mottó: "A verseny jó!"
-
#5644
S_x96x_S
őstag
Petykemano
#5640
S_x96x_S
őstag
válasz
Petykemano
#5640
üzenetére
> AMD EPYC 7T83 [link]
A chipen a 2. sorban a "BH 2052PG.."
még mindig a gyártási hetet jelzi?
vagyis 2020 - 52.hét ?Mottó: "A verseny jó!"
-
#5645
S_x96x_S
őstag
Petykemano
#5640
S_x96x_S
őstag
válasz
Petykemano
#5640
üzenetére
> Milan-X
már a wécécé is lehozta
AMD EPYC Milan-X Server CPUs Leak Out, Up To 64 Zen 3 Cores & Possibly 3D V-Cache Stacks
https://wccftech.com/amd-epyc-milan-x-server-cpus-leak-out-up-to-64-zen-3-cores-possibly-3d-v-cache-stacks/EPYC 7773X 64 Core (100-000000504)EPYC 7573X 32 Core (100-000000506)EPYC 7473X 24 Core (100-000000507)EPYC 7373X 16 Core (100-000000508)> Possibly 3D V-Cache Stacks
Ezek után ha a Threadripper nem kapja meg idén összel ..
akkor bánatos leszek.és a TomsH is - persze nem HBM és korrigálták is magukat.
https://www.tomshardware.com/news/amd-epyc-milan-x-leaks-64-cores-rumored-hbm-memory[ Szerkesztve ]
Mottó: "A verseny jó!"
-
S_x96x_S
őstag
Az Intel elég jó versenytársat tol be idén
a 8 Erős + 8Gyenge&hatékony mag (24 thread) pariban van
a 16 ZEN3-as maggal ( 32thread)
Persze egy teszt nem teszt - de azért valamit sejtet.Már csak az a kérdés, hogy
az AMD - minden maghoz ad 3D-Vcache-t
vagy most még csak vegyes konstrukció lesz.
pl. a 8 magos chipletből csak 4 magot tunningolnak fel,
vagy az új 6950X - nél csak az egyik chiplet lesz 3DVcache tunningolt.
( csak hogy kezdjek mindenkit felkészíteni a nemvárt meglepetésekre is)
persze ennek minimális az esélye - mert itt is az ütemezés okozhat (apróbb) problémákat - de ki tudja ...
------------Intel Core i9-12900K is 12% faster than Ryzen 9 5950X in single-core and 3% faster in multi-core tests
https://videocardz.com/newz/intel-core-i9-12900k-is-12-faster-than-ryzen-9-5950x-in-leaked-single-core-geekbench-5-benchmark
- Core i9-12900K should offer a 5.3 GHz boost clock on P-Cores and 3.9 GHz on E-Cores. ~ DDR5-4800Egy összehasonlítás:
https://browser.geekbench.com/v5/cpu/compare/9509437?baseline=9506672Mottó: "A verseny jó!"
-
HSM
félisten
válasz
S_x96x_S
#5646
üzenetére
"vagy az új 6950X - nél csak az egyik chiplet lesz 3DVcache tunningolt."
Ennek mutatták be először a prototípusát. [link]![;]](//cdn.rios.hu/dl/s/v1.gif)
Érdekes gondolat egyébként, a big-little első megközelítésének is megfelelne.
Az ütemező miatt túlzottan nem aggódnék, a CPPC-ből konfigurálható mag-preferencia eddig is adott volt, és a Ryzeneknél eddig is voltak erősebb és gyengébb magok, hiszen nem egyforma volt a magok maximális BOOST órajele, tehát simán SMU-ból is kezelhetőnek tűnik a dolog ahogy jelenleg is.[ Szerkesztve ]
-
#5648
Petykemano
veterán
S_x96x_S
#5646
Petykemano
veterán
válasz
S_x96x_S
#5646
üzenetére
> vagy most még csak vegyes konstrukció lesz.
> pl. a 8 magos chipletből csak 4 magot tunningolnak fel,A jelenlegi CCX-ek közösen/megosztottan érik el és használják a L3$-t.
Az én értelmezésem szerint a V-cache nem L4$ lesz, hanem az L3$ kibővítése.
De sehogyse értem, hogy miképp lenne megvalósítható, hogy 8-ból 4 mag látja csak a kibővített - v-cache - területet.Azt esetleg el tudom képzelni, hogy egy 2CCD-s kialakításban csak az egyik kap v-cache-t. Ez mondjuk a 2 CCD-s Ryzenek esetén talán kevésbé lenne látványos/jelentős lépés, de ha egy Threadripper épülne fel úgy, hogy 4-ből csak 1 kap tornyot az már eléggé a big.LITTLE irányába hatna. És nyilván ahogy mondod, szükség is lenne a megfelelő megkülönböztetésre.
Ilyenkor az emberek mindig megijednek, hogy na itt ette meg a fene, de hát valahogy eddig is kitalálta a hardver és az ütemező együtt, hogy melyik az a mag, amelyik a legmagasabb frekvenciára tud boostolni és hogy oda akkor mit érdemes ütemezni a maximális teljesítmény elérése érdekében.
Ezzel együtt én valószínűbbnek tartok egy v-cache méreten alapuló szegmentációt. egy CCD felett 64 v 32
Találgatunk, aztán majd úgyis kiderül..
-
#5649
S_x96x_S
őstag
Petykemano
#5648
S_x96x_S
őstag
válasz
Petykemano
#5648
üzenetére
> A jelenlegi CCX-ek közösen/megosztottan érik el és használják a L3$-t
jogos!
akkor ennek az esélye közel a nullához.Mottó: "A verseny jó!"
-
hokuszpk
nagyúr
válasz
S_x96x_S
#5646
üzenetére
kihagytad azt a kombot, hogy az I/O die tetejere teszik a VCache -t
"Intel Core i9-12900K is 12% faster than Ryzen 9 5950X in single-core and 3% faster in multi-core tests"
az jo, mert akkor csak 100-200 Mhz -t kell tolni az 5950X -en, hogy multiban visszavegye a vezetest, nyolc mag feletti procit meg azert valoszinuleg nem a single core teljesitmeny miatt veszi az emberfia.
[ Szerkesztve ]
Első AMD-m - a 65-ös - a seregben volt...




















 Valószínűleg itt is más, mélyebb metrikák után kell majd nézni, ahogy a gyártástechnológiai elnevezéseknél is volt. A user meg csak vakargathatja majd a fejét.
Valószínűleg itt is más, mélyebb metrikák után kell majd nézni, ahogy a gyártástechnológiai elnevezéseknél is volt. A user meg csak vakargathatja majd a fejét. 
![;]](http://cdn.rios.hu/dl/s/v1.gif)
