Új hozzászólás Aktív témák
-
Sziasztok, csináltam egy példa kódot List<List<Color>> struktúra létrehozására. Tudom, hogy a listakreálás lassú, stb, de szükségem van a felxibilitására.
Készítettem egy benchmarkot úgy hogy párhuzamosság nélkül kreálok egy 4000 elemű List<> szerkezetet amit List<Color> elemeket tartalmaz (4000 elemű lista üres List<Color> elemekkel). Majd ugyanezt a listát megkreálom 250 elemű szublisták konkatenálásával, melyeket külön taskonként asszinkron módon hozok létre.
A kód változtatás és többletmunka nélkül fordul Visual Studióban
azt látom, hogy a párhuzamosítással nem tudok érdemi sebességelőnyt elérni. Én csinálok valamit nagyon rosszul, vagy a .NET olyan ravasz, hogy a List<List<>> kreálását már magától párhuzamosan végzi???
Előre is köszi !
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Drawing;
using System.Diagnostics;
namespace ConsoleApp30
{
class Program
{
private const int width = 4000;
private const int height = 3000;
//Ez lesz a delegate függvény a Taskok megkreálásához
static public List<List<Color>> createSublist (int n, int height)
{
List<List<Color>> result = new List<List<Color>>(n);
for (int i = 0; i< n; ++i)
{
result.Add(new List<Color>(height));
}
return result;
}
static void Main(string[] args)
{
Stopwatch stopwatch = new Stopwatch();
Stopwatch stopwatch1 = new Stopwatch();
List<List<Color>> pixelList = new List<List<Color>>(width);
//Listakreálás párhuzamosítás nélkül
stopwatch.Start();
for (int i = 0; i < width; ++i)
{
pixelList.Add(new List<Color>(height));
}
stopwatch.Stop();
Console.WriteLine("Sequential :" + stopwatch.ElapsedMilliseconds);
stopwatch.Reset();
int numOfCores = Environment.ProcessorCount;
int numOfTasks = numOfCores * 4;
Task<List<List<Color>>>[] tasks = new Task<List<List<Color>>>[numOfTasks];
long[] threadCreations = new long[numOfTasks];
stopwatch.Start();
for (int i= 0; i< numOfTasks; ++i)
{
stopwatch1.Start();
tasks[i] = new Task<List<List<Color>>> (() => createSublist(width / numOfTasks, height));
stopwatch1.Stop();
threadCreations[i] = stopwatch1.ElapsedMilliseconds;
stopwatch1.Reset();
}
for (int i=0; i< numOfTasks; ++i)
{
tasks[i].Start();
}
for (int i = 0; i < numOfTasks; ++i)
{
Console.WriteLine("Task nr {0} state: {1}", i, tasks[i].Status.ToString());
}
Task.WaitAll(tasks);
stopwatch.Stop();
Console.WriteLine("Creating {0} sublists in parallel took: {1} ms", numOfTasks, stopwatch.ElapsedMilliseconds);
stopwatch.Reset();
for (int i = 0; i < numOfTasks; ++i) {
Console.WriteLine("Creating task nr {0} took: {1} ms", numOfTasks, threadCreations[i]);
}
stopwatch.Start();
IEnumerable<List<Color>> result = tasks[0].Result.AsEnumerable();
for (int i = 1; i < numOfTasks; ++i)
{
result = result.Concat(tasks[i].Result);
}
var cList = result.ToList();
stopwatch.Stop();
Console.WriteLine("Concat of {0} Lists took :{1} ms", numOfTasks, stopwatch.ElapsedMilliseconds);
stopwatch.Reset();
}
}
}[ Szerkesztve ]
-
válasz
 Jester01
#7885
üzenetére
Jester01
#7885
üzenetére
Köszi hogy kipróbáltad!
ez ugye a párhuzamos eredménye:
var cList = result.ToList();Tehát a cList változó.
Elképzelhető, hogy a Mono fordítója észreveszi, hogy a cList semmire sincsen használva, az előtte lévő Concat függvénynek meg ugye a taskoknak sincsenek mellékhatásai, ezért a cList kiszámításához vezető utat kioptimalizálja (= ki sem számítja)?
SZERK:
Nálad valahogy iszonyat jól gyorsul: 796ms x 64 = 51sec az alig több mint a 46sec.De ennyit nem szabadna sehogy sem gyorsulnia, én ugye a Taskok számát a logikai procimagok száma x 4-re vettem. A max gyorsulás amit várnék az a logikai procimagok arányában lenne (nálam 4, nálad 16(????))
[ Szerkesztve ]
-
válasz
Jester01
#7885
üzenetére
Egyébként attól eltekintve, hogy nálad legalább gyorsul, a Mono (még nem próbáltam) ezek szerint valami iszonyat optimalizálatlan kódot készít:
nekem Windowson egy négymagos géppel ca 280ms, függetlenül attól,
hogyan erőlködöm a párhuzamosítással. A procim egy szálon sem erősebb a tiednél.[ Szerkesztve ]
-
-
#7894
 joysefke
veterán
Peter Kiss
#7893
joysefke
veterán
Peter Kiss
#7893
válasz
 Peter Kiss
#7893
üzenetére
Peter Kiss
#7893
üzenetére
Color adatokat szeretnék egy List<List<Color>> struktúrában tárolni. BMP képnek az adatai lesznek benne, tehát akár 10-20 millió képpont (4 byte) is tárolódhat itt.
Azért kell a List<>, mert szinte véletlenszerűen egy sornyi vagy oszlopnyi pixel (de nem ugyanabból a sorból vagy oszlopból) kieshet. ekkor pedig szeretném a kiesett pixeleket kiszedni a pixellistából, hogy ne maradjanak lyukak, minden pixelnek legyen érvényes szomszédja. Tehát úgy gondolom, hogy a statikus tömb nekem nem jó a rengeteg átméretezés miatt. (bár az egy opció, hogy statikus tömb memóriaterületét oszloponként a listába másolom, de itt nem tartok)
Kb 300ms kell, mire egy List<> listát lefoglalok, amely 4000 darab üres List<Color> -ból áll. Szeretném ezt lerövidíteni, de a művelet végén mindenképpen dinamikus listát szeretnék látni.
[ Szerkesztve ]
-
válasz
Jester01
#7895
üzenetére
Számon tartok egy gradiens táblázatot is, amely az egyes képpontok szomszédainak eltérőségét adja meg.
valueMap[x][y] = sqrtLookup[
sqr[Math.Abs((pixelList[modKadder(x, 1,width)][y].R - pixelList[modKadder(x, -1, width)][y].R))]
+ sqr[Math.Abs((pixelList[modKadder(x, 1, width)][y].G - pixelList[modKadder(x, -1, width)][y].G))]
+ sqr[Math.Abs((pixelList[modKadder(x, 1, width)][y].B - pixelList[modKadder(x, -1, width)][y].B))]
//+ sqr[Math.Abs((pixelList[modKadder(x,1,width)][y].A - pixelList[modKadder(x,-1,width)][y].A))]
+ sqr[Math.Abs((pixelList[x][modKadder(y, 1, height)].R - pixelList[x][modKadder(y, -1, height)].R))]
+ sqr[Math.Abs((pixelList[x][modKadder(y, 1, height)].G - pixelList[x][modKadder(y, -1, height)].G))]
+ sqr[Math.Abs((pixelList[x][modKadder(y, 1, height)].B - pixelList[x][modKadder(y, -1, height)].B))]
//+ sqr[Math.Abs((pixelList[x][modKadder(y, 1, height)].A - pixelList[x][modKadder(y, -1, height)].A))]
];minden Pixelpozícióra ki van számolva a gradiensfüggvény arra a pontra. Amikor egy képpont kiesik, akkor a szomszédainak (akik esetleg bentmaradnak) megváltoznak a szomszédai, tehát a gradienstáblázatot is updatelni kell azokban a pixelpozíciókban, ahol változás történt.
egy sor vagy oszlopnyi pixel fizikai (vagy logikai) törlése nagyságrendileg 4000 pixel törlését és 8000 pixelnyi gradiens újraszámítást igényel. Ha 1000 sort veszel ki, akkor mindezt 1000x. A gradiens újraszámítás pedig igényi, hogy gyorsan el tudd dönteni, hogy egy pixelnek kik a szomszédai. Nem rakhatok bonyolult logikát a ki-kinek a szomszédja meghatározásába.
[ Szerkesztve ]
-
válasz
 joysefke
#7896
üzenetére
joysefke
#7896
üzenetére
az int sqrtLookup[] és az int sqr[] keresőtáblák, az első a gyökvonáshoz a második a négyzetreemeléshez (mondjuk ennek nem sok haszna van)
pixelList[x][modKadder(y, 1, height)]Ez a kódrészlet fogja és kikeresi a pixellistából az [x][y+1] pozícióhoz tartozó pixel Color értékét. a modKadder egyszerűen annyit csinál, hogy az utolsó sorból (y = height-1) a nulladik sorba ugrat (y = 0) és fordítva. Ugyanezt az x tengely mentén az oszlopokra
-
válasz
Jester01
#7895
üzenetére
Nem tudom hogy akarod utána használni, de egy sor/oszlop index ami megmondja hogy az i. sor/oszlop az fizikailag melyik sor/oszlop az viszonylag egyszerű törlést tesz lehetővé.
Hmm...
most jobban belegondolva megfontolom:
Egy 4000x3000 elemű List<List<>> előállításánál elmegy egyszer 300ms, utána minden egyes sor segédlistákból való törlésénél elmegy még sor-törlésenként egyszer 6-8ms (de ez mondjuk 1000x is megtörténhet). Lehet tényleg előrébb tartanék egy index-fordító táblázattal, kérdés, hogy a statikus tömbök rugalmatlansága mennyi plusz futásidőt eredményezne, elvinné-e a megtakarítást.
[ Szerkesztve ]
-
Saját szórakozásra implementálok egy Seam Carving algoritmust. Az algoritmus meg körülötte egy WPF ablak már kész van, prototípus szinten szépen működik (egyelőre full fapad, de müxik).
Én is tegnap jöttem rá -világított rá valaki redditen-, hogy a Color az sokat foglal, mindjárt meg is nézem mennyit. Eddig szembe sem jutott, hogy a Color az nem 4 byte (8+8+8+8 = A+R+G+B).
A szükségesnél magasabb memóriafoglalás egyelőre nem zavar, egy 13mpx-es kép esetén az applikáció teljes memóriafogyasztás "csak" 500-550mb. A sebesség viszont sokkal gázabb. Parallel.For(), taskok és nem managelt mem hozzáférés segítségével már volt némi gyorsulás
Na mind majd visszajövök

Athlon64:
A kép kirajzolása másodlagos, kétszer kell kirajzolni: miután betöltötte a képet, illetve miután lefutott az algoritmus a módosított képet.Ha lesz időm töltök fel konkrét kódrészleteket, hogy lássuk mit lehetne hatékonyabbá tenni. Lenne mit
[ Szerkesztve ]
-
#7902
joysefke
veterán
Peter Kiss
#7900
válasz
Peter Kiss
#7900
üzenetére
Ha az nem is jó neked, akkor pl. én nem használnék Color-t, mert az kicsit túl nagy, helyette egy int is megteszi vagy egy kisebb saját típus.
Te jó ég, most megnéztem
Console.WriteLine(Marshal.SizeOf(new Color ())); -----> Ez 24-et ír ki a konzolra

Jól értelmezem, Color objektumonként 24 Byte + a tömb overheadje a memóriafoglalás???
Ez 13Mpx-nél (az egy átlagos kép) 13*24*E6 = 312MB+overhead...
Én meg annyira meg voltam győződve róla, hogy ez a Color objektum csak az RGBA értékeket tárolja 4byte-ban, és az a sok property amin keresztül ezt-azt le lehet kérdezni az is csak az RGBA értékeket kérdezgeti le/állítja be...
[ Szerkesztve ]
-
Az előző hsz, vagy ez, int.Parse(string)-gel, de itt manuálisan kell elkapni az exceptiont
a
bool successváltozó tárolja, hogy sikeres volt-e a beolvasás, ado-whileciklus addig fog próbálkozni a beolvasással, míg az egyszer sikeres nem lesz. A string -> int átalakítást azint.Parse(string)végzi, ha ez sikeres volt (mert a user tényleg számot adott be), akkor a következő végrehajtott utasítás a success = true; lesz. Ellenkező esetben létrejön egy exception és a végrehajtás acatch(Exception) {...}blokkban folytatódik anélkül, hogy a success változót átállítottuk volna, ebben az esetben a do-while ciklus újra lefut.class Program
{
static void Main(string[] args)
{
int num=0;
bool success = false;
do
{
Console.Write("Enter number : ");
string str = Console.ReadLine();
try
{
num = int.Parse(str);
success = true;
}
catch (Exception ex)
{
Console.WriteLine("Not a valid number, try again!");
}
} while (success != true);
Console.WriteLine($"You typed in the following number: {num}");
}
}[ Szerkesztve ]
-
A válaszom tökéletesen helytálló illetve egyből működés közben mutatja be a dolgot, copy-pésztezhetően. ÉS mint följebb írtam vagy a fölötte levő hsz a TryParse(..) -val, vagy az int.Parse(..). Konzolon userre várva sosem fog számítani, ha pedig streamből jön az adat, akkor már nem az lesz a kérdés, hogy milyen metódussal lehet string->int parseolni.
-
using System;
class Program
{
static void Main(string[] args)
{
bool succes = false;
float num1 = 0;
float num2 = 0;
do
{
Console.WriteLine("Kérem az összeadni kívánt számokat.");
Console.Write("Egyik szám: ");
string a = Console.ReadLine();
Console.Write("Másik szám: ");
string b = Console.ReadLine();
succes = float.TryParse(a, out num1) && float.TryParse(b, out num2);
if (!succes)
{
Console.WriteLine("");
Console.WriteLine("Nem számot adtál meg!");
}
}
while (succes != true);
float osszeg = num1 + num2;
Console.CursorVisible = false;
Console.WriteLine("A két szám összege= " + osszeg);
}
} -
válasz
joysefke
#7939
üzenetére
Ez float.Parse(string) helyett
bool float.TryParse(string, out float)-tal van.A kettő között a különbség az, hogy a TryParse akkor sem dob exception-t ha nem sikerült a parzolás, ehelyett a sikert a TryParse(...) fgv. a visszatérési értékével jelzi. Csak akkor, ha ha mindkét számot egyszerre sikerült parzolni lesz a success változó értéke true, ekkor tudja a vezérlés elhagyni az adatbeolvasó do-while ciklust.
-
C# 7.0 in a Nutshell könyvet referenciaként forgatja valaki? Vélemény?
-
#7975
joysefke
veterán
Peter Kiss
#7974
válasz
Peter Kiss
#7974
üzenetére
In a nutshell : 1089 oldal
![;]](//cdn.rios.hu/dl/s/v1.gif)
-
válasz
 don_peter
#7986
üzenetére
don_peter
#7986
üzenetére
Ha Goose-T példájában a TryParse(...) sort erre cseréled, akkor nem int-ként hanem hexa-ként fogja értelmezni az input sztringeket...
if (int.TryParse(clean, NumberStyles.HexNumber, null, out var number))Ha így csinálod, akkor kell még egy:
using System.Globalization;[ Szerkesztve ]
-
http://www.c-sharpcorner.com/article/C-Sharp-heaping-vs-stacking-in-net-part-i/
Ez egy régebbi cikksorozat, de a lényeg azóta nem változott. rágd magad át rajta.
-
Legyen szíves valaki segítsen. System.IO.Compression-al bohóckodom, biztosan valami bufferprobléma van, de nem látom, hogy hol... Elég béna vagyok

Itt van két nyúlfarknyi kód, az egyikben nincs tömörítés és működik, a másikban van tömörítés és nem működik. Az írásnál nem futok bele exceptionba.
Itt alább ez működik:
Gyártok egy string[] tömböt és elemenként mint szöveget beleírom egy StreamWriter(new MemoryStream)-be. Majd ennek az ellentettje, mindent szépen rendben vissza tud olvasni. Egyszer 1000 utána 10000 elemet próbálok tömöríteni, kiírni.Előre is köszönöm!!!
using System;
using System.IO;
class Program
{
//Gets a string[] array with n data items
public static string[] GetNumbers(int n)
{
string[] numbers = new string[n];
for (int i = 0; i < n; ++i) numbers[i] = (i + 20000).ToString();
return numbers;
}
// writes the string[] array consisting of n items as text to an underlying memory stream
// after that the backing byte[] data structure of the memory stream is extracted via toArray()
// this byte[] array is used to instantitze a MemoryStream and read back the content as text
// this works as expected
public static void WriteReadStrings(int n)
{
string[] numbers = GetNumbers(n);
byte[] data;
using (MemoryStream ms = new MemoryStream())
using (StreamWriter sw = new StreamWriter(ms))
{
int i = -1;
try
{
for (i = 0; i < n; ++i) sw.WriteLine(numbers[i]);
}
catch (Exception ex)
{
Console.WriteLine("Exception: " + ex.Message);
Console.WriteLine("Current item: {0} \r\nhit key!", i);
Console.ReadKey();
}
sw.Flush();
ms.Flush();
data = ms.ToArray();
}
Console.WriteLine("data size: {0}", data.Length);
Console.WriteLine("hit key to proceed");
Console.ReadKey(true);
//reading back the compressed stream
using (MemoryStream ms = new MemoryStream(data))
using (StreamReader sr = new StreamReader(ms))
{
while (sr.EndOfStream != true) Console.WriteLine(sr.ReadLine());
}
}
static void Main(string[] args)
{
WriteReadStrings(1000);
Console.WriteLine("hit key to proceed");
Console.ReadKey(true);
WriteReadStrings(10000);
Console.WriteLine("hit key to proceed");
Console.ReadKey(true);
}
}Ok, és most ugyanez tömörítéssel:
Totálisan nem megy. Ha 1000 elemet próbálok tömöríteni, semmi nem kerül bele a MemoryStreambe, ha 10000-et, akkor meg csak valami 8000 környéki. Biztosan valami buffer hiba van, de hol???using System;
using System.IO;
using System.IO.Compression;
class Program
{
//Gets a string[] array with n data items
public static string[] GetNumbers(int n)
{
string[] numbers = new string[n];
for (int i = 0; i < n; ++i) numbers[i] = (i + 20000).ToString();
return numbers;
}
// writes the string[] array consisting of n items as text compressed to an underlying memory stream
// after that the backing byte[] data structure of the memory stream is extracted via toArray()
// this byte[] array is used to instantitze a MemoryStream and read back the content as text
// this does NOT work
public static void CompressAndDecompressStringArr(int n)
{
string[] numbers = GetNumbers(n);
byte[] compressedData;
using (MemoryStream ms = new MemoryStream())
using (GZipStream ds = new GZipStream(ms, CompressionMode.Compress))
using (StreamWriter sw = new StreamWriter(ds))
{
int i = -1;
try
{
for (i = 0; i < n; ++i) sw.WriteLine(numbers[i]);
}
catch (Exception ex)
{
Console.WriteLine("Exception: " + ex.Message);
Console.WriteLine("Current item: {0} \r\nhit key!", i);
Console.ReadKey();
}
sw.Flush();
ds.Flush();
ms.Flush();
compressedData = ms.ToArray();
}
Console.WriteLine("Compressed data size: {0}", compressedData.Length);
Console.WriteLine("hit key to proceed");
Console.ReadKey(true);
//reading back the compressed stream
using (MemoryStream ms = new MemoryStream(compressedData))
using (GZipStream ds = new GZipStream(ms, CompressionMode.Decompress))
using (StreamReader sr = new StreamReader(ds))
{
while (sr.EndOfStream != true) Console.WriteLine(sr.ReadLine());
}
using (MemoryStream ms = new MemoryStream(compressedData))
using (GZipStream ds = new GZipStream(ms, CompressionMode.Decompress))
using (StreamReader sr = new StreamReader(ds))
{
string[] separator = new string[1];
separator[0] = Environment.NewLine;
Console.WriteLine("Split returned {0} lines", sr.ReadToEnd().Split(separator, StringSplitOptions.RemoveEmptyEntries).Length );
Console.WriteLine("hit key to proceed");
Console.ReadKey(true);
}
}
static void Main(string[] args)
{
CompressAndDecompressStringArr(1000);
Console.WriteLine("hit key to proceed");
Console.ReadKey(true);
CompressAndDecompressStringArr(10000);
Console.WriteLine("hit key to proceed");
Console.ReadKey(true);
}
}[ Szerkesztve ]
-
Vedd ki a flush hívásokat, ha using blockot használsz, mert szükségtelen. De nem vagyok benne biztos, hogy ez okozza a problémát.
A működőben (tömörítés nélkül) kellenek a flush() hívások, próbáltam, anélkül hibázik :
mire ez meghívódik:data = ms.ToArray()már mindennek a MemoryStream-ben kell lennie.A nem működő verziók (ami tömörít) pedig nem segít, akár bent van, akár nem. Egyébként mindenfélével próbálkoztam, nincs ötletem..
[ Szerkesztve ]
-
válasz
 Zalanius
#8005
üzenetére
Zalanius
#8005
üzenetére
Köszönöm!
1, az általad javasolt megoldás működik (
 )
)2, A
Fush()megléte, meg nem léte nem változtatott semmit. (kipróbáltam)3, Ami megjavította a kódot az ez volt:
using (MemoryStream ms = new MemoryStream())
{
using (GZipStream ds = new GZipStream(ms, CompressionMode.Compress))
{
using (StreamWriter sw = new StreamWriter(ds))
{Ezzel pedig hibázik:
using (MemoryStream ms = new MemoryStream())
using (GZipStream ds = new GZipStream(ms, CompressionMode.Compress))
using (StreamWriter sw = new StreamWriter(ds))
{......}Ne röhögjetek ki, de én azt hittem, hogy a kettő egyenértékű. Rengeteg példaprogramot láttam
using (.....)
using (.....)
{...}sablon szerint, illetve a fönti tömörítés nélküli verzióban ami nem hibázik is több using statementet egymás után van, majd a kódblokk...
[ Szerkesztve ]
-
Miért gondoljátok, hogy a Flush() a using blokkon belül felesleges, ha még a using blokkon belül szeretném, hogy a stream konzisztens legyen azzal amit beleírtam:
byte[] data;
using (...)
{
írás....
sw.Flush();
ms.Flush();
data = ms.ToArray();
} -
Köszi!
1,
Nem a zárójelek javították meg, hanem az hogy a GZipStream using blokkon kívülre került a ToArray hívásVak vagyok
Próbálgattam a dolgot, és elegendő volt a ToArray() hívást a StreamWriter- using blokkján kívülre rakni, már az is megjavította (úgy hogy a GZipStream using blokkján még belül volt ) (!!!)
Tehát abban igazad van, hogy ki kellett lépni valamelyik using blokkból.2,
A flush pedig nem szükséges (mivel a végén van nem okoz problémát, csak kétszer hívódik), mert a Dispose során a Framework meghívja mindenképpen.OK, ezt értem, de azt nem értem, hogy az én megoldásom miért nem jó, tehát, ha még a legbelső (StreamWriter) using blokkon belül akarom a ToArray()-t megívni backing streamen (MemoryStream), akkor miért nem működik az, hogy szépen visszafele meghívom a Flush()-öket:
sw.Flush(); ds.Flush(); ms.Flush();aztán meghívom a MemoryStreamen a ToArray()-t.Itt azt várnám, hogy a Flush() hívások után a a MemoryStream mindent tartalmaz amit beleírtam (kiürültek a bufferek), tehát bátran hívhatok ToArray()-t...
Itt ugye asszinkronitás sincsen, tehát abban a pillanatban amikor meghívom a Flush()-t, akkor már minden írás amit előtte kiadtam már megtörtént (bufferbe)És ez működik is úgy, hogy nincsen tömörítés (DeflateStream vagy GZipStream) hanem csak Streamwriter( MemoryStream()) van. Onnantól kezdve, hogy közé ékelek egy GZipStreamet vagy DeflateStream-et, borul az egész...
[ Szerkesztve ]
-
Uhh

https://msdn.microsoft.com/en-us/library/system.io.compression.deflatestream.flush(v=vs.110).aspx
DeflateStream.Flush Method ()The current implementation of this method does not flush the internal buffer. The internal buffer is flushed when the object is disposed.
GZipStream.Flush() ugyanez...
Mondjuk továbbra sem értem, miért elegendő, ha a ToArray() a StreamWriter blokkján kívül, de a GZipStream blokkján belül van. Azt várnám, hogy ahogy Te tanácsoltad, a GZipStream blokkja után kellene hogy legyen, hogy biztonságos legyen meghívni a ToArray-t. (mert ekkor a GZipStream is Dispose-olva és ezáltal a bufferje is ürítve lett)
[ Szerkesztve ]
-
Az egyetlen nehézséget az okozza ebben, hogy a Console.ReadKey() blokkol ha éppen nem volt megnyomva billentyű, ekkor addig vár amíg le nem nyomsz egy billenytűt, azt kiolvassa és csak azután megy tovább a végrehajtás. A
Console.KeyAvailablesegítségével ezt ki lehet küszöbölni, ennek akkor ha true az értéke, akkor volt lenyomva billentyű, amelynek az értéke bufferbe került, ezt ki lehet olvasni a Console.ReadKey()-jel, anélkül, hogy az blokkolna.using System;
using System.Threading;
// NonblockingReadKey
class Program
{
// N > 1
static void Count(int N)
{
//this will store the pressed key
ConsoleKeyInfo consoleKey;
// counter will be the running variable
// starting to count down from N
int counter = N;
// when true: counting down
// when false counting up
bool countingDown = true;
// ends one below zero when counting down and one above N when counting up
while (!(counter==-1 && countingDown) && !(counter == N+1 && !countingDown) )
{
Console.Clear();
Console.Write(counter);
Thread.Sleep(250);
// Console.KeyAvailable == true only if there was a keypress
//in the console
if (Console.KeyAvailable)
{
// reads the keypress
consoleKey= Console.ReadKey();
// reads any remaining keypresses from the buffer
// if you have pressed more then one keys during sleep-time
while (Console.KeyAvailable) consoleKey = Console.ReadKey();
// Immediatelly breaks at reading ESC key
if (consoleKey.Key == ConsoleKey.Escape)
{ Console.Clear(); break; }
//switches the counting direction
// true -> false
// false -> true
// countingDown ^= true; ;)
countingDown = !countingDown;
}
//increments or decrements the counter according to
// the value of countingDown
if (countingDown == true) { --counter; }
else { ++counter; }
}
Console.Clear();
Console.WriteLine("Finished!!!");
}
static void Main(string[] args)
{
Count(100);
}
}[ Szerkesztve ]
-
Sziasztok!
Le akarok szedni YT-ról automatizáltan (barátnőmnek futáshoz) zenéket, mp3 formátumban. Engem nem érdekelnek túlságosan az ilyen olyan kódolások, csak működjön és legyen legalább 192kbps mp3. És lehetőleg tényleg mp3 kódolásban legyen.
Ezt használom YT librariként:
https://github.com/Tyrrrz/YoutubeExplodeA képen egy tetszőleges YT zeneklipphez kinyert AudioStreamInfo bejegyzéseket lehet látni, összesen öt darabot.
Opus AAC és Vorbis típusú kódolású audióstreamek vannak, mp3 sehol. Opusból van három különböző bitrátával.
Van ezzel az Opussal valakinek valami tapasztalata?
-telefonok media playere lejátssza önmagában vagy ez egy WEB-formátum?
-könnyen konvertálható mp3-má? (értelemszerűen .NET-ben)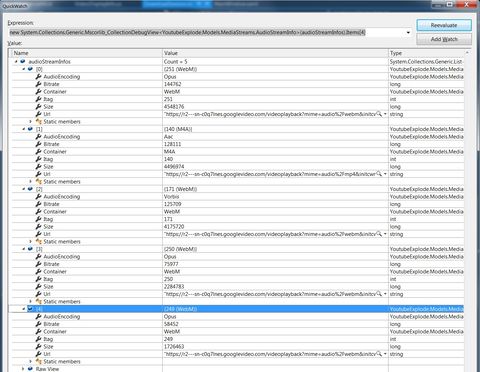
[ Szerkesztve ]
-
válasz
 Goose-T
#8023
üzenetére
Goose-T
#8023
üzenetére
Neki pont WP van
Mivel azt látom, hogy a YT videóknál az Opus adja a legtöbb bitráta-opciót, ezért az tűnik a legegyszerűbben használhatónak:
-(1) Minden videóból kiszedem a bitrátában a legjobban illeszkedő (192kbps környéke) Opus sávhoz tartozó uri-t
-(2) Letöltöm az Opus kódolású audió fájlt
-(3) Miután lent van, konvertálom mp3-ra.Ez most a terv. Ha lenne 192-es mp3 sáv, egyből azt szedném le, de az alapprobléma az, hogy:
Egy csomó videónak az audióját szeretném egyszerre letölteni, előre nem tudom, hogy ezek milyen kódolásban, milyen sávszélességekben lesznek fent. A végén pedig egységesen mp3-ban szeretném látni őket. A példaképen (fönt) egyértelműen ez az Opus csoda tűnik a legtámogatottabbnak...
-
válasz
 harylmu
#8028
üzenetére
harylmu
#8028
üzenetére
Barátnőm még naptárból is papírt használ, facebookja nincs etc. Az egyetlen stabil pont, amire biztosan számíthatok, hogy meg fog kérni, hogy offline rakjam rá a YT-ról ezt meg azt a telefonjára. Havonta 10-15-20 számot. Fizetni meg biztosan nem fog ilyen streaming csodákért. Én sem. Én zenét sem hallgatok...
tenyleg csak max gyakorlasnak
tökéletes, gyakorlom a Task-async dolgokat
Dobjuk légyszi ezeket a streaming előfizetéseket, a YT videók audió tartalmának párhuzamos letöltését azóta már megoldottam, már csak az Opus -> mp3 konverzió van hátra, azt holnap este megcsinálom.
[ Szerkesztve ]
-
WPF
A letöltés szépen működik meg minden, de belefutottam egy problémába, amit nem tudtam megoldani:
szeretném, ha az összes párhuzamos letöltés állapota egy progress csíkon aggregáltan látszódna, tehát letöltött bájtok/összes letöltendő bájt.Na ezt nem tudom megoldani, nem értem, hogy hol a hiba. Attól eltekintve, hogy már ránézésre is ronda. Már többször átstrukturáltam a releváns kódrészletet, de nem akarja az igazságot, a letöltések szépen működnek, de a progress bar nem moccan. debuggolni sem igazán tudom...
A kód:
MainWindow.xaml.csMiután a user kiválasztotta, hogy mit akar letölteni, kreálok egy progress objektumot (ez fogja a teljes letöltés állapotát mutatni) és ezt illetve a cél könyvtárat átadom a _session objektum letöltő metódusának. Ez a metódus minden fájlt egy egy Task-async művelettel tölt le, amelyek egy-egy Progress<double> objektumon keresztül tudják állapotukat visszajelezni. Ezeknek az egyes Progress<double>-oknak a visszajelzéseit szeretném egyetlen egy Progress<double>-ba aggregálni. Na ez nem megy.
private async void _downloadAudios(object sender, RoutedEventArgs e)
{
...
IProgress<double> [B]progress[/B] = [B]new Progress<double>[/B]([B]a =>[/B] _fileProgressBar.[B]Value = a*100[/B]);
[B]await _session.DownloadAudioAsync(_folderPath, progress);[/B]
}Másik fájl
DownloadAudiosAsync:public async Task DownloadAudioAsync(string downloadPath, IProgress<double> progress)
....
List<Task> dlTasks = new List<Task>();
[B]Itt fogom az egyes fájlok teljes méretét illetve az aktuálisan letöltött
bájt-számokat tárolni. Ezek az adatok az aggregáláshoz kellenek.
[/B] Az összes Action<double> delegate hozzáfér ezekhez és ugyanazt látják.
//[B]long[] bytesDownloaded[/B] = new long[_videoDisplayInfos.Count];
//[B]long[] fileSizes[/B] = new long[_videoDisplayInfos.Count];
//Előre előkészítem a Progress objektumoknak az üres helyet. Az első
tömb fogja a valós, a második pedig a dummy (null) Progress objektumokat
tartalmazni. Indokás később
[B]IProgress<double>[] fileDLprogresses [/B]= new IProgress<double>[_videoDisplayInfos.Count];
[B]IProgress<double>[] progressesEmpty [/B]= new IProgress<double>[_videoDisplayInfos.Count];
[B]A dummy tömböt feltöltöm csupa Progress = null referenciával[/B].
Indoklás később.
for (int i=0; i< progressesEmpty.Length; ++i) progressesEmpty[i] = new Progress<double>();
//összes fájl együttes mérete tárolódik itt
long totalBytesToDownload = 0;
[B]//Ezen a for cikluson belül lesznek megkreálva az egyes Action delegate-k,
melyek elkapják a ciklusváltozót és lemásolják azt. Illetve itt lesznek az
egyes Task-async letöltések elindítva.[/B]
//végigmegyünk a letöltendő videókon
for (int i=0; i < _videoDisplayInfos.Count; ++i)
{
//letöltendő videók letöltésre kijelölt streamjeinek adatait kiszedjük
VideoDisplayInfo videoDisplayInfo2 = _videoDisplayInfos[i];
AudioStreamInfo streamToDownload2=_videoDisplayInfos[i].PreferredAudioStream;
//csak ha létezik a videóhoz megfelelő stream
if (streamToDownload2 != null)
//fájladatokat (név, útvonal, kiterjesztés) kiszedem/legyártom
string fileExtension2 = streamToDownload2.Container.GetFileExtension();
string sanitizedFileName2 = Utils.SanitizeFilename(videoDisplayInfo2.Title);
string filename2 = Path.ChangeExtension(Path.Combine(downloadPath, sanitizedFileName2), fileExtension2);
//fájlok méretadatait elmentem
fileSizes[i] = streamToDownload2.Size;
totalBytesToDownload += fileSizes[i];
[B]//Megkreálom az egyes Progress<double> objektumok action delegate-ját.[/B]
//Minden delegate updatelgeti az őt futtató letöltés által letöltött adatmennyiséget
//Majd meghívja az aggregált delegatet
//
Action<double> action = value =>
{
// captured loop iterator
int index = i;
long fileSize = fileSizes[index];
long totalBytesDownloaded;
lock (bytesDownloaded)
{
long oldValue = bytesDownloaded[index];
bytesDownloaded[index] = (long)(value * fileSize);
totalBytesDownloaded = bytesDownloaded.Sum();
progress.Report(totalBytesDownloaded / totalBytesToDownload);
}
};
//megkreálom a valós Progress objektumokat
fileDLprogresses[i] = new Progress<double>(action);
//Elindítom a letöltéseket a dummy (null) Progress objektumokkal.
dlTasks.Add(_youtubeClient.DownloadMediaStreamAsync(streamToDownload2, filename2, progressesEmpty[i]));
[B]//if blokk vége[/B]
}
[B]//for blokk vége[/B]
}
// Miután kiléptem a for ciklusból és az int i ciklusváltozó érvényét vesztette lecserélem
a dummy Progress referenciákat az igazi Progress referenciákra. A for cikluson belül
nem lehet odaadni az igazi Progress referenciákat, mert az Action delegateben
a ciklusváltozó akkor még érvényes.
for (int j = 0; j < progressesEmpty.Length; ++j) progressesEmpty[j] = fileDLprogresses[j];
// bevárom a letöltést
await Task.WhenAll(dlTasks);
}[ Szerkesztve ]
-
Istenem hogy néz ez ki

-
válasz
joysefke
#8033
üzenetére
a hiba megvan:
Valamiért nem működik az, hogy menet közben lecserélem a letöltés metódusnak átadott dummy Progress<> objektumot egy igazira. Nem értem, hogy miért, de így van.
Tehát a progress repoltolás itt nem működik a Progress objektum cseréje után sem:
var p = new Progress<double>();
Task t = _youtubeClient.DownloadMediaStreamAsync(streamToDownload, filename, p);
// lecserélem a Progress-t valami olyanra ami csinál is valamit
p = new Progress<double> (value => {....})
await tnem működik.
Nem értem miért nem működik, hiszen a DownloadMediaStreamAsync metódus is az átadott Progress objektumnak a referenciáját használja, _tudtommal_ nem készít róla fizikai másolatot.
szerk:
Uhh bakker, milyen jó volt leírni a problémát, most jövök rá mi a baj
[ Szerkesztve ]
-
válasz
 zsolti_20
#8081
üzenetére
zsolti_20
#8081
üzenetére
nekem a szerver alapú megoldás a szimpi, mert a kliensek a szerver nyilvános címéhez mindig tudnak csatlakozni tcp-n vagy még inkább https-en keresztül, ez után a szerver már tud válaszolni a klienseknek, mert kinyíltak a tűzfalak.
ha tisztán szervermentes üzemmódot szeretnél és mindkét kliensed tűzfal mögött van külön privát hálózatokon, akkor szerver nélkül nekem lehetetlennek tűnik, hogy megtalálják egymást illetve a tűzfalon keresztül fel tudjanak egy kapcsolatot építeni. A kliens oldali tűzfalak befelé csak akkor engednek bármit is, ha a kliens kifelé már kezdeményezte a kapcsolatot...
[ Szerkesztve ]
-
#8097
joysefke
veterán
stickermajom
#8088
válasz
 stickermajom
#8088
üzenetére
stickermajom
#8088
üzenetére
Kezdőnek (egy félév egyetemi C# oktatás jó régen) milyen szakirodalmat ajánlanátok? Pluralsight, Lynda adott, bookmarkolok ezerrel mindent, ami kezdő szint.
Én is csak ismerkedem a nyelvvel (fél éve), picit már kezd több lenni mint hobbi, írok egy két tapasztalatot, hogy nekem eddig mi jött be.
1,
C# Yellow book, 200-250 oldal
http://www.robmiles.com/c-yellow-book/A könyv egyes részei picit már elavultak, de szerintem az egész egyben mint egy nagyon kezdőknek való tanító könyv nagyon jó. Gyorsan ki tudod végezni, megismertet a nyelv és a keretrendszer fő elemeivel, sok jó példakód van benne és best practicek mint szamárvezető. Ez a könyv nem engedi el a kezed és irányban tart. A könyvhöz tartozik laborjegyzet és két "nagyházi feladat" is útmutatókkal.
Én úgy érzem, hogy nekem érdemes volt anno belerakni a könyvbe, a gyakorlatokba és a nagyházi feladatokba azt a két hét munkát amibe az egész került. Nekem a dolog programozás része nem volt új, ezért egy csomó szájbarágós fejezetet elég volt csupán átlapozni, a legalapvetőbb nyelvi elemek viszont többé kevésbé rögzültek.
2,
Aztán írtam egy csomó kódot, egyszerű dolgokat, algoritmusokat implementáltam, ha valamit nem tudtam, nem működött akkor Google -> stackoverflow, vagy msdn. Általában sikerült egyenesbe hozni a dolgokat, de ilyenkor mindig egy csomó dolgot nem értek, hogy miért az a legjobb megoldás illetve miért pont úgy kell, és hogy hogyan működik a motorháztető alatt.Én úgy vagyok vele, ha éppen egy nagyobb tanulás fázisban vagyok, akkor igyekszem egyes témakörökkel mélységében is megismerkedni, mert különben nincsen lehorgonyozva a tudás, és úgy nem csak sokkal bizonytalanabb az ember, hanem hamarabb is felejt. Ha éppen implementálás fázisban vagyok, akkor nyilván megelégszem a Google-> Stackoverflow féle megoldásokkal, mert akkor haladni akarok.
3,
Most éppen on-off a C# 7.0 in a Nutshell könyvet gyűröm. Ez már nem egy szájbarágós könyv, hanem az aktuális C# és Framework funkciókat írja le témakörökbe csoportosítva érthető magyarázatokkal és példakódokkal, kitér arra is, hogy mi hogyan működik a motorháztető alatt. Itt már eléggé el van engedve az ember keze, de nem hagy teljesen magadra mint egy language reference.Az a jó a C# in a Nutshell-ben, hogy aktuális és vannak online példakódok is hozzá, melyek (nagyrészt) copy-paste-vel könnyedséggel kipróbálhatóak.
Szóval számomra kezdőként a tanulság eddig az, hogy úgy fejlődök/tanulok a leghatékonyabban, ha ciklusosan tanulok pár hétig (nyilván a példakódokat az IDE-ben ki is próbálom) aztán implementálok valamit ami nem teljesen triviális, de fókuszál valamire amit el szeretnék mélyíteni. Implementálás közben meg nem ragadok le tanulással. Utána megint tanulok pár hétig, de mindig az aktuális felkészültségemnek még emészthető mélységben.
[ Szerkesztve ]
-
Találkozott már valaki jól működő google contacts CSV parserrel?
Próbaképpen kiexportáltam a saját google kontaktjaimat CSV-be, beimportáltam Excelbe és egy totál káosz az egész. Az én kontaktjaim nyilván már összekuszálódtak, de feltételezem ez az általános és nem egyedi eset.
-(1) Annyi az oszlop mint égen a csillag
-(2) Az elválasztó karakter a vessző, de vannak benne " "-közé zárt stringek is, melyek ugyancsak tartalmazhatnak vesszőt (!!!)Legalábbis nekem így tűnik (azért írom ezt, mert Excelbe sehogy sem sikerült értelmesen beimportálnom őket)
-
válasz
Zalanius
#8548
üzenetére
Köszi!!
De hát a csv-k esetében az pont szándékos, amit a (2)-ben írtál, mert a szövegjelölő " ... " nélkül nem lehetne vessző a cellákban
Najó, de miért nem lehet akkor olyan karaktert használni, ami nem engedélyezett/nem bukkanhat fel a kontaktok között? Ha én berakok egy vagy több "-karaktert valamelyik kontaktba, akkor az még escaepelve is lesz vagy mi

Ezt minden parsernek kezdettől fogva tudnia kell, az excel is simán boldogul vele, az importáláskor még meg is adható, mit tekintsen szövegjelölőnek.
Meg is adtam, de nem jelent teljes megoldást a problémára, ezen kívül más is van...
Inkább arra gyanakszom, hogy CR / LF lesz egy vagy több szövegben, és azt már az Excel legendásan rosszul tűri.
Na erre nem gondoltam, annyira hosszúak és üresek a sorok, hogy számomra gyakorlatilag követhetetlen hogy éppen hol van elcseszve a sortörés. Mindenesetre az Outlook CSV export gyönyörűen importálódik Excelbe
-
válasz
Zalanius
#8548
üzenetére
Ránéztem notepad++ -szal illetve utánaolvastam.
-(1) Igazad volt benne, hogy a goolge CSV export valóban alapból LF karakterrel zárja le a CSV sorait, de nem ez a valódi probléma. Én úgy látom, hogy még ezt is megenné az Excel. Hanem
-(2) Úgy tűnik a Google CSV megengedi a sorvége karaktert a CSV adatmezőiben is. Utánaolvastam, régebben így volt, ezek szerint ez nem változott. Na ezzel van az Excelnek problémája amit bőven meg is értek. Semmilyen jelölőkarakter nincsen az ilyen köztes sortörések előtt...
A " "-párokat mint szövegjelölőt még meg tudom érteni, de "sor közben" sortörés?
[ Szerkesztve ]
-
válasz
joysefke
#8550
üzenetére
Semmilyen jelölőkarakter nincsen az ilyen köztes sortörések előtt...
helyesbítek: annyi jelölés van, hogy sor közbeni sortörés csak aposztrófok között lehetséges.
Ez lesz a megoldás : https://github.com/22222/CsvTextFieldParser/blob/master/CsvTextFieldParser/CsvTextFieldParser.cs[ Szerkesztve ]
-
#8556
joysefke
veterán
Peter Kiss
#8552
válasz
Peter Kiss
#8552
üzenetére
Köszönöm, nagyon jó tipp volt!
-
ASP .NET Core MVC 2
Iránymutatás kéne, elég kezdő vagyok ebben
Csinálok egy esküvőszervező appot. Ennek lesz egy User és egy Admin felülete. A User felületen lehet látni a bemutatkozást, elolvasni a részleteket, elfogadni a meghívást, visszajelezni stb. Az Admin felületen lehet konfigurálni a szövegmezőket (nevek, időpontok, helyszín, bemutatkozás stb..) képeket feltölteni az egyes szekciókhoz illetve a usereket konfigurálni, meghívókat elküldeni stb...
Adatbázis -SQLite- már van az applikációban, ez tárolja az IdentityUser entitásokat az elérhetőségekkel illetve hozzájuk a userek visszajelzéseit is. A backend logika már egész jól működik, ehhez akarok hozzákendácsolni valami értékelhető user interfészt. Ehhez értek a legkevésbé.
A User felülethez letöltöttem egy (free) single page reszponzív template-t HTML-CSS-JS+képekkel. Ennek a HTML részéből csináltam egy _UserLayout.cshtml-t. Azonosítottam azokat a szövegmezőket és képeket amelyeket az Admin által konfigurálhatóvá akarok tenni.
Ezek a konfigurálható textboxok/képek a Layout-on teljes mértékben szét vannak szórva, nincsenek lokalizálva, nem tudok egy szekciót kiemelni, hogy csak ott legyenek a konfigurálható elemek. Minimum 50-60db szövegelemmel és 20db képpel számolok. Szóval a végére akár a duplája is lehet.
A kérdés az, hogy mi a legértelmesebb módja annak, hogy a Layout/View-nak átadjam a megjelenítendő szövegelemeket, képeket? Minél kevesebb javascript-tel. Az admin felülettel nem lesz problémám.
Nekem ez jutott eszembe:
-(1)Írjam be a konfigurálható szövegelemeket az adatbázisba,
-(2)onnan kerüljenek az alkalmazás-szerver indításakor (vagy bármikor amikor konfigurációs változás történt) egy perzisztens read only in-memory Dictionary<string, string> objektumba ami dependecy injectionnal elérhető lesz a kontroller(ek)ből,
-(3) A kontroller(ek) pedig (egy közös helper methoddal) mielőtt meghívják a View-t bepakolják az adatokat a ViewBag-be?
-(4)A ViewBag-re alapozva lehetne a Layout/View-ban megjeleníteni a konfigurálható szövegelemeket._________
Azt hogy ezeket (a gyakorlatilag statikus) elemeket ViewModel-be rakjam és mindig cipeljem nem tűnik optimálisnak.
Mi a sztenderd megoldás? Gondolom ez nem valami egyedi dolog és van rá több jó megoldás...
Képeket adatbázisba rakjam, vagy csak a nevük/útvonaluk/rendeltetésük kerüljön az adatbázisba, maga a fájl pedig a fájlrendszerbe? Itt jelentkezne az a probléma, hogy a fájlrendszert és az AB-t szinkronban kellene tartanom. Van erre valami pattern?
Előre is köszönöm!
üdv
J.[ Szerkesztve ]
-
válasz
 martonx
#8571
üzenetére
martonx
#8571
üzenetére
Hi köszi a választ! Igen, számítottam rád
Nah szóval:
hanem maradj a HTML-nél, és igyekezz minél több mindent html és mvc alapokon tartani.Az Admin oldalon ez már megvan és működik. Van egy _AdminLayout-om ami tartalmazza a linkeket (no meg némi bootstrap formázást) az egyes admin feladatokhoz, ezek a feladatok külön-külön View-ba vannak szervezve. Itt a kontrollerek és a View-k között az adatok ViewModel objektumokkal közlekednek, visszafelé ugyanígy Model-bindinggal.
Szerintem ez a része jó ahogy van. Nem túl esztétikus, de nem is kell az legyen.
A userek felé viszont illene valahogyan esztétikusan kinézzen a dolog. Ehhez töltöttem le egy template-t. Se nem tudnám, se nem akarnám megcsinálni a user oldal HTML+CSS+ izgő mozgó JS design-ját. Ennek egyébként is minimális köze van csak a feladathoz. Az admin tudjon usereket konfigurálni, meghívókat szétküldeni, a kapott visszajelzéseket aggregálva megjeleníteni.
A usernek annyi dolga van, hogy a user View-ban rábökjön, hogy jön-e vagy sem, hányan jönnek, kell-e szállás stb..
Tehát ezt a szép template-t szeretném a korábban általam elkészített management felülettel összeházasítani illetve a user felület néhány tartalmát az admin által konfigurálhatóvá tenni.
A kérdés kifejezetten erre irányult, mégpedig azért, mert eddig az admin felület View-jait adatokkal ellátó ViewModel objektumaim (user adatai, user visszajelzése) mind nagyon karcsúak és feladat specifikusak voltak, most pedig nem tudom, hogy ezeket a kvázi-statikus adatokat (user neveket-bemutatkozásokat, képeket stb kb egyszer kell az adminnak konfigurálnia) hogyan lenne érdemes elszállítani a kontrollertől a renderelt user View-ba.
Ezek mellett a kvázi-statikus adatok mellett még lesz sokkal fókuszáltabb user specifikus adat (pld. üdvözlő szöveg amikor a user az egyedi linken keresztül belép vagy egy visszajelzés arról, hogy már elfogadta-e a meghívást)
Nah szóval leírtam a problémámat, és nagyon szépen megkérlek, ha már vetted a fáradtságot és végigolvastad a dolgot, írtál vagy 30 sort, akkor 2-3 pontba összeszedve valami olyat is próbálj beleírni a válaszodba ami engem most előre visz...
Nagyon szépen köszönöm
[ Szerkesztve ]
-
.NET Core 2 MVC - model validálás, miért nem megy?
Sziasztok!
Szeretném a (működő) model validálást kiszervezni a kontrollerből egy külső osztályba. Létrehoztam egy : Attribute, IModelValidator interfészeket megvalósító validátor attributum-osztályt, a nevével dekoráltam az action method megfelelő paraméterét, mégis semmi nem utal arra, hogy valaha, bármilyen körülmények között eljutna a végrehajtás az én általam definiált IModelValidator.Validate() metódushoz. Sem a breakpoint sem a Validate függvényben levő exception nem aktiválódik. A
fileparaméterValidatedbejegyzést rak a ModelState-be akkor is amikor nem kéneRészletek:
[HttpPost]
public IActionResult EditPerson(Person model, int id, [ImageValidator]IFormFile file)Itt a
file-t kellene validálni.Itt a validátor:
public class ImageValidatorAttribute : Attribute, IModelValidator
{
public bool IsRequired => true;
// Max size of image in KB
public int MaxSize { get; set; } = 1024;
// Allowed extensions
public string Extensions { get; set; } = ".jpg .jpeg";
public IEnumerable<ModelValidationResult> Validate(ModelValidationContext context)
{
throw new NotImplementedException();
IFormFile file = context.Model as IFormFile;
List<ModelValidationResult> result = new List<ModelValidationResult>();
if (file != null) {
.....
....
}
return result;
}
}A kontrolleren beül így néz ki a file paraméter-kezelése:
if (ModelState.GetValidationState(nameof(file)) == Microsoft.AspNetCore.Mvc.ModelBinding.ModelValidationState.Valid)
{....}Ez mindig igaz...
Elmulasztottam valamit? Kell esetleg regisztrálni valahol a validátort?
[ Szerkesztve ]
-
válasz
martonx
#8576
üzenetére
Ez is egy példakód volt...
Igen, a linkelt doksit olvastam, azóta megcsináltam ami benne van, továbbra sem működik.
ValidationAttribute-tal.
public class SizeAttribute : ValidationAttribute
{
private int size;
public SizeAttribute(int Size) => size = Size;
protected override ValidationResult IsValid(object value, ValidationContext validationContext)
{
IFormFile file = validationContext.ObjectInstance as IFormFile;
if (size * 1024 < file.Length) return new ValidationResult($"A maximum image size of only {size}KB is allowed");
else return ValidationResult.Success;
}
}Itt az action method:
[HttpPost]
public IActionResult EditPerson(Person model, int id, [Size(1024)]IFormFile file)Kell még valami? Kell esetleg valahol regisztrálni a SizeAttribute-osztályt?
[ Szerkesztve ]
-
válasz
 petyus_
#8578
üzenetére
petyus_
#8578
üzenetére
Nincsen, a doksi szerint azáltal, hogy nincsen rajta, nem is zártam ki, hogy érvényes legyen paraméterre:
https://docs.microsoft.com/en-us/dotnet/csharp/programming-guide/concepts/attributes/attributeusage
-
válasz
martonx
#8580
üzenetére
Nem, azt még nem próbáltam ki.
Alapvetően én ezt az IFormFile-t akarom validálni, maga a model objektumom (Person) nem túl kritikus, annak a propertijeit az osztálydeklarációban dekoráltam [Required]-del, az a része működik és nekem egyelőre elég is.
Dobtam a mai próbálkozásomat (elnapoltam) a kontrollert visszaállítottam a naiv, nem túl alapos kézi validálásra. Jelenleg így néz ki, csak annyi a célja az IFormFile validálásnak, hogy figyelmetlenségből ne lehessen rossz formátumot feltölteni. Tudom, hogy a fájl kiterjesztése semmit nem jelent.
A Person egy ViewModel objektum és tárolja egy személy adatait illetve a képének a relatív útvonalát a wwwroot-hoz képest. Összesen kb 6-10 Person objektum lesz, ezek in-memory tárolódnak (és minden változás mentődik a diszkre). Ők nem userek, hanem csupán koszorúslányok-fiúk, a képük-nevük pedig a Weblapon fog virítani. Az admin egyszer konfigurálja őket a content-manager oldalon utána ezek úgy maradnak.
A dolog nincsen túlságosan kitesztelve, de működik.
[HttpPost] public IActionResult EditPerson(Person model, int id, IFormFile file)
{
// Text based informations (Person object) and IFormFile gets validated separatelly
// The expectation is to execute EditPerson if the Person is valid, even if IFormFile is missing or invalid
// Exceptions can only be raised bc of file IO errors. This should not break the method
// we collect the exceptions to log details later into ModelState
IList<Exception> exceptions = new List<Exception>();
if (id < 0 || store.Data.People.Length <= id) ModelState.AddModelError("", "Error: route variable \"id\" has invalid value");
if (model?.Title != "Groomsmen" && model?.Title != "Bridesmaid") ModelState.AddModelError("", "Http post request contains invalid title: must be \"Bridesmaid\" or \"Groomsmen\"");
if (ModelState.IsValid)
{ // Person object is valid and updates the ContentStore no matter the IFormFile state
store.Data.People[id] = model;
store.Update(store.Data.People);
} // IFormFile gets manually validated
if (file != null)
{
string name = file.FileName;
string ext = Path.GetExtension(file.FileName.ToLower());
if (1024 * 1024 < file.Length) ModelState.AddModelError("", "Error: A maximum image size of 1MB allowed");
if (ext != ".jpeg" && ext != ".jpg") ModelState.AddModelError("", "Error: JPEG file expected extension must be either *.jpeg or *.jpg");
if (ModelState.IsValid)
{
// currently no renaming and no protection against malicious IFileForm-s as file upload is not available for public
string newFileName = file.FileName;
string newFileFullPath = Path.Combine(webRoot, imageFolder, newFileName);
while (System.IO.File.Exists(newFileFullPath))
{
//gets a nice, short random file name in case of a filename conflict
newFileName = (DateTime.Now.Ticks % 1000).ToString() + ext;
newFileFullPath = Path.Combine(webRoot, imageFolder, newFileName);
}
try
{
using (FileStream fs = System.IO.File.Create(newFileFullPath))
{
file.CopyTo(fs);
fs.Flush();
// file path gets saved in cshtml friendly relative path
store.Data.People[id].PictureSrc = "/" + imageFolder + "/" + newFileName;
}
}
catch (Exception ex) { exceptions.Add(ex); }
}
if (0 < exceptions.Count)
{
ModelState.AddModelError("", "Error: Could not upload image");
foreach (var ex in exceptions) ModelState.AddModelError("", ex.Message);
}
else store.Update(store.Data.People);
}
if (ModelState.IsValid) return RedirectToAction(nameof(Index));
else
{ ViewBag.id = id;
return View(model);
}
}[ Szerkesztve ]











![;]](http://cdn.rios.hu/dl/s/v1.gif)



 )
)










Új hozzászólás Aktív témák
● ha kódot szúrsz be, használd a PROGRAMKÓD formázási funkciót!
- AMD K6-III, és minden ami RETRO - Oldschool tuning
- Óra topik
- Autós topik
- Napelem
- A fociról könnyedén, egy baráti társaságban
- Kodi és kiegészítői magyar nyelvű online tartalmakhoz (Linux, Windows)
- D1Rect: Nagy "hülyétkapokazapróktól" topik
- E-roller topik
- GoPro Topic
- NVIDIA GeForce RTX 4060 / 4070 S/Ti/TiS (AD104/103)
- További aktív témák...
