Új hozzászólás Aktív témák
-

nyunyu
félisten
Némelyik DB motornál lehet a select oszlopainak sorszámára is hivatkozni a rendezésnél vagy csoportosításkor, de ez nem szabvány SQL szintaxis!
Más motornál meg aliast is lehet használni.
Oracle asszem csak a sorszámot érti a group by és order by-nál, aliast nem.
[ Szerkesztve ]
Hello IT! Have you tried turning it off and on again?
-
#4903
nyunyu
félisten
Apollo17hu
#4902
nyunyu
félisten
válasz
 Apollo17hu
#4902
üzenetére
Apollo17hu
#4902
üzenetére
Ezt passzolom, nem látok bele ennyire az SQL optimalizálók lelkivilágába.
Érzésem szerint rá kéne jönnie, hogy ugyanazt akarod számoltatni az group by-nál is, így a korábban kapott eredményhalmazt használja, de meg kéne nézni egy konkrét végrehajtási tervet, hogy változik-e ha kiírod az order by-nál a case-whent, vagy ha oszlopsorszámmal hivatkozod.
[ Szerkesztve ]
Hello IT! Have you tried turning it off and on again?
-
nyunyu
félisten
válasz
 RedHarlow
#4904
üzenetére
RedHarlow
#4904
üzenetére
Fizikailag belefűzni a sorvége karakter(eke)t a stringbe?
desc=desc || chr(13) || chr(10) || 'Adat: 1200'
Feltéve, ha Windows stílusú stringekkel dolgozol, ami CR+LF (\r\n)-rel van terminálva.
Unix/linux vonalon elég lehet a chr(13) (CR, \r), mac esetén a chr(10) (LF, \n) isHello IT! Have you tried turning it off and on again?
-

Fecogame
veterán
Ugyan angolul, de publikáltam a blogomon a PostgreSQL 11-ről 13-ra váltás menetét
 Step-by-step, mindössze 20-30 percet vesz igénybe, többször tesztelt.
Step-by-step, mindössze 20-30 percet vesz igénybe, többször tesztelt.Upgrade PostgreSQL from 11 to 13 on CentOS 7
Hátha valakinek hasznos lesz. GitLab 14-es verziójától kezdve (ami idén Június 22.-én fog kijönni) megszűnik a PSQL 11-es verziójának támogatása.
Lassú a mobilinterneted? 4G/LTE antennák, közvetlenül raktárról ---> http://bit.ly/LTE_Antennak
-

kw3v865
senior tag
Sziasztok!
Ismét PostgreSQL-es téma (de gondolom más SQL-ben is hasonló lehet a megoldás). Ezúttal adott egy GROUP BY probléma, amelynek során csoportokat akarok létrehozni, kissé bonyolult feltétellel.
Adott egy tábla, melynek egyik mezője értékeket tartalmaz, ezeket kell majd szummázni (illetve más, bonyolultabb műveleteket végezni, de most igyekszem leegyszerűsíteni).
Minden egyes rekordhoz tartozik egy start és egy end érték. Ezek különbsége nem haladhatja meg a 30-at, tehát olyan rekord nincs a táblában melynél a két érték különbsége nagyobb, mint 30.
Az összevonást úgy kell végrehajtani, hogy ez a szabály továbbra is érvényes legyen, ezáltal az eredmény táblában sem lehet olyan rekord, ahol a két érték különbsége nagyobb, mint 30.
Egy oszlopban a SUM, egy startmeter (értelemszerűen a legkisebb érték az adott csoportban, a) és egy endmeter (MAX).Így néz ki az input tábla, alatta pedig az eredmény, hogy kell kinéznie:

Úgy látom ez nem egy sima GROUP BY, mivel itt komolyabb csoportosításra van szükség.
Van valami tippetek miként lehetne ezt megvalósítani?
-

sztanozs
veterán
válasz
 kw3v865
#4910
üzenetére
kw3v865
#4910
üzenetére
Ez már operációkutatás, nem adatbázis kérdés...
tegyük fel a következőt:
1 | 2 | 10 | 20
2 | 2 | 10 | 30
3 | 2 | 10 | 40
4 | 2 | 20 | 30
5 | 2 | 20 | 40
6 | 2 | 20 | 50
7 | 2 | 30 | 40
8 | 2 | 30 | 50
9 | 2 | 30 | 60
Ezzel a forrással milyen range-eket hozol létre és melyik melyikbe tartozna?[ Szerkesztve ]
JOGI NYILATKOZAT: A bejegyzéseim és hozzászólásaim a személyes véleményemet tükrözik; ezek nem tekinthetők a munkáltatóm hivatalos állásfoglalásának...
-
#4917
sztanozs
veterán
Apollo17hu
#4915
sztanozs
veterán
válasz
Apollo17hu
#4915
üzenetére
Az, hogy milyen példát hozott még nem jelenti azt, hogy ez a való életben is így lesz (lehet, hogy csak nem gondolt rá)...
JOGI NYILATKOZAT: A bejegyzéseim és hozzászólásaim a személyes véleményemet tükrözik; ezek nem tekinthetők a munkáltatóm hivatalos állásfoglalásának...
-

Diopapa
addikt
Sziasztok, kérlek segítsetek!
Van 2 táblám, az egyik egy törzsadatokat tartalmazó,
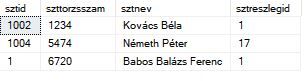
Meg egy másik:
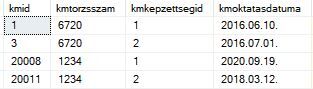
Egyszerű lekérdezésem:
select szttorzsszam , sztnev , klnevhu from szemelytorzs
left join bfkepzettsegimatrix on szemelytorzs.szttorzsszam = bfkepzettsegimatrix.kmtorzsszam
left join kepzettseglista on bfkepzettsegimatrix.kmkepzettsegid = kepzettseglista.klid where szttorzsszam = '1234'Az eredménye:

Hogyan tudom megoldani, hogy egy név csak egyszer szerepeljen és a "klevhu" mezők egymás mögött szerepeljenek?
Előre is köszönöm!
Citizen Diopapa / Commander Diopapa "SC csomag olyan, mint a barackfa, unokáidnak veszed - .tnm / De pálinkát nemlehet főzni belűle - *SkyS1gn"
-
sztanozs
veterán
válasz
 Diopapa
#4918
üzenetére
Diopapa
#4918
üzenetére
mysql/mariadb
select szttorzsszam, sztnev, group_concat(klnevhu) from szemelytorzs
left join bfkepzettsegimatrix on szemelytorzs.szttorzsszam = bfkepzettsegimatrix.kmtorzsszam
left join kepzettseglista on bfkepzettsegimatrix.kmkepzettsegid = kepzettseglista.klid where szttorzsszam = '1234'
group by szttorzsszam, sztnevmssql (2017+)
select szttorzsszam, sztnev, STRING_AGG(klnevhu, ',') from szemelytorzs
left join bfkepzettsegimatrix on szemelytorzs.szttorzsszam = bfkepzettsegimatrix.kmtorzsszam
left join kepzettseglista on bfkepzettsegimatrix.kmkepzettsegid = kepzettseglista.klid where szttorzsszam = '1234'
group by szttorzsszam, sztnevpostgres
select szttorzsszam, sztnev, array_to_string(array_agg(klnevhu), ',') from szemelytorzs
left join bfkepzettsegimatrix on szemelytorzs.szttorzsszam = bfkepzettsegimatrix.kmtorzsszam
left join kepzettseglista on bfkepzettsegimatrix.kmkepzettsegid = kepzettseglista.klid where szttorzsszam = '1234'
group by szttorzsszam, sztnev[ Szerkesztve ]
JOGI NYILATKOZAT: A bejegyzéseim és hozzászólásaim a személyes véleményemet tükrözik; ezek nem tekinthetők a munkáltatóm hivatalos állásfoglalásának...
-
Diopapa
addikt
válasz
 sztanozs
#4919
üzenetére
sztanozs
#4919
üzenetére
Szia, köszi a gyors választ, nem írtam, MSSQL, viszont nem ismeri fel a függvényt

"Msg 195, Level 15, State 10, Line 28
'STRING_AGG' is not a recognized built-in function name."Vajon mit bénázok el?

Citizen Diopapa / Commander Diopapa "SC csomag olyan, mint a barackfa, unokáidnak veszed - .tnm / De pálinkát nemlehet főzni belűle - *SkyS1gn"
-

Ispy
veterán
válasz
Diopapa
#4920
üzenetére
Csak 2017-es verziótól van, gondolom a tied korábbi, azért nem ismeri fel.
Én xml path-al és stuff-al szoktam megcsinálni, mert ugye régen is kellett a string_agg előtt.
[link]Vagy még régebben a coalesce-t használtam, az is jó hozzá:
[link][ Szerkesztve ]
"Debugging is like being the detective in a crime movie where you're also the murderer."
-
Ispy
veterán
válasz
Diopapa
#4923
üzenetére
Nem tudom jó-e, nem tudtam tesztelni, de kb. ezt hegesztgessed.
SELECT szttorzsszam,
sztnev,
STUFF ((
SELECT ',' + kepzettseglista.klnevhu AS [text()]
FROM kepzettseglista
WHERE kepzettseglista.klid = bfkepzettsegimatrix.kmkepzettsegid
FOR XML PATH('')
), 1, 1, '' )
AS [klnevhu]
FROM szemelytorzs
LEFT JOIN bfkepzettsegimatrix ON szemelytorzs.szttorzsszam = bfkepzettsegimatrix.kmtorzsszam
WHERE (szttorzsszam = '1234')
GROUP BY szttorzsszam,
sztnev[ Szerkesztve ]
"Debugging is like being the detective in a crime movie where you're also the murderer."
-
Diopapa
addikt
Aha, köszi próbálom értelmezni.
Most ezt az üzenetet kapom:
"Column 'bfkepzettsegimatrix.kmkepzettsegid' is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause."Citizen Diopapa / Commander Diopapa "SC csomag olyan, mint a barackfa, unokáidnak veszed - .tnm / De pálinkát nemlehet főzni belűle - *SkyS1gn"
-
Ispy
veterán
válasz
Diopapa
#4925
üzenetére
Hát akkor csináld amit mond, rakd be a group by-ba
![;]](//cdn.rios.hu/dl/s/v1.gif)
De a legjobb az lenne, ha az egész group by részt kiszednéd először, hogy megnézd mit is kapsz.
Sőt lehet, hogy a group by nélkül, ha megy, akkor egy subselectbe csomagolod és úgy group by-olod be.
SELECT szttorzsszam,
sztnev,
klnevhu
FROM (
SELECT szttorzsszam,
sztnev,
STUFF ((
SELECT ',' + kepzettseglista.klnevhu AS [text()]
FROM kepzettseglista
WHERE kepzettseglista.klid = bfkepzettsegimatrix.kmkepzettsegid
FOR XML PATH('')
), 1, 1, '' )
AS [klnevhu]
FROM szemelytorzs
LEFT JOIN bfkepzettsegimatrix ON szemelytorzs.szttorzsszam = bfkepzettsegimatrix.kmtorzsszam
WHERE (szttorzsszam = '1234')
) S
GROUP BY szttorzsszam,
sztnev,
klnevhu[ Szerkesztve ]
"Debugging is like being the detective in a crime movie where you're also the murderer."
-
nyunyu
félisten
válasz
 smallmer
#4927
üzenetére
smallmer
#4927
üzenetére
Nem tudom, ezek mennyire használhatóak.
Oracle DBből ER diagram generálásra tudnám ajánlani a saját Data Modelerjüket, de ezzel nem vagy kisegítve.
[ Szerkesztve ]
Hello IT! Have you tried turning it off and on again?
-
nyunyu
félisten
válasz
sztanozs
#4919
üzenetére
Csak hogy az Oracle szintaxis is meglegyen:
select szttorzsszam, sztnev, listagg(klnevhu, ',') within group(order by klnevhu) from szemelytorzs
left join bfkepzettsegimatrix on szemelytorzs.szttorzsszam = bfkepzettsegimatrix.kmtorzsszam
left join kepzettseglista on bfkepzettsegimatrix.kmkepzettsegid = kepzettseglista.klid where szttorzsszam = '1234'
group by szttorzsszam, sztnev;Hello IT! Have you tried turning it off and on again?
-

Taci
addikt
Sziasztok!
Ránéznétek kérlek, hogy ezek a lekérdezések (példák, az értékek persze folyamatosan változnak) nem "pazarlóak"-e?
Működnek tökéletesen, csak nem tudom, hogy lehet-e/kell-e optimalizálni őket.SELECT * FROM table1WHERE id NOT IN (102,103)UNION ALLSELECT * FROM table2WHERE id NOT IN (104,105,106,107,108,109,110,111,112)UNION ALLSELECT * FROM table3WHERE id NOT IN (31,32,33,34,35,36,37)UNION ALLSELECT * FROM table4WHERE id NOT IN (59,60,61,62,63)UNION ALLSELECT * FROM table5WHERE id NOT IN (21)ORDER BY date DESCA másik pedig:
SELECT * FROM table1WHERE ((title LIKE '%szoveg%') OR (description LIKE '%szoveg%'))UNION ALLSELECT * FROM table2WHERE ((title LIKE '%szoveg%') OR (description LIKE '%szoveg%'))UNION ALLSELECT * FROM table3WHERE ((title LIKE '%szoveg%') OR (description LIKE '%szoveg%'))UNION ALLSELECT * FROM table4WHERE ((title LIKE '%szoveg%') OR (description LIKE '%szoveg%'))UNION ALLSELECT * FROM table5WHERE ((title LIKE '%szoveg%') OR (description LIKE '%szoveg%'))ORDER BY date DESCHa nem "életbevágó", nem nyúlnék hozzájuk, viszont ha jobb lenne optimalizálni (valahogy), akkor megköszönném az iránymutatást.
Köszi.
-
nyunyu
félisten
Mi a ráknak van öt, tökegyforma táblába szétszedve az adat?
Teljesen felesleges, hacsak nincs sokmillió rekord, és időnként másik táblába archiváltok.
Gyorsan hízó logokhoz szerintem felesleges az unionnal bohóckodni, egyszerre úgyis csak egy logban akarsz keresni, hiszen nagyjából be tudod lőni, milyen dátum intervallumot akarsz vizsgálni.Meg az order by-t sem értem, mert ebben a formában csak az ötödik táblát rendezi csökkenőbe.
Először kapod az első táblát rendezetlenül, aztán a másodikat, aztán a harmadikat... végül az ötödiket rendezve.
Ha fontos az időben csökkenő rendezés, akkor én tennék egy select * from ( ) order by date desc-et az unionok köré.[ Szerkesztve ]
Hello IT! Have you tried turning it off and on again?
-
sztanozs
veterán
'NOT IN' elég pazarló (legalább is az én ismereteim szerint), persze lehet, hogy a modern motorok már átalakítják kevésbé lassabbakra.
A LIKE-ok meg szerintem mindegy milyen scope-ban futnak. Simán egybe lehet rakni az összes táblát és utána szűrni:SELECT * FROM (
SELECT * FROM table1
UNION ALL
SELECT * FROM table2
UNION ALL
SELECT * FROM table3
UNION ALL
SELECT * FROM table4
UNION ALL
SELECT * FROM table5
)
WHERE ((title LIKE '%szoveg%') OR (description LIKE '%szoveg%'))
ORDER BY date DESCJOGI NYILATKOZAT: A bejegyzéseim és hozzászólásaim a személyes véleményemet tükrözik; ezek nem tekinthetők a munkáltatóm hivatalos állásfoglalásának...
-
Taci
addikt
Az 5 táblában 5 különböző forrásból származó bejegyzések vannak, jellemzően több száz (idővel több ezer), ezért vannak már eleve külön táblákba mentve.
És a bejegyzéseket jelenítem meg az oldalon időrendi sorrendben.
Viszont mivel sokszor előfordult, hogy frissült az adatbázis, miközben lapozgattam a listázott bejegyzések között (egyszerre csak 4-et jelenít meg (LIMIT 4, csak azt nem másoltam be a kódrészletbe), aztán görgetés után a következő 4-et, és így tovább), ezért újra ugyanazt a bejegyzést jelenítette meg (mert megjelenítette a 4 legfrissebbet, aztán frissült a bejegyzés, frissebb bejegyzések kerültek előre, tovább görgettem, betöltötte a következő 4-et, de azok egyszer már meg lettek jelenítve a frissítés előtt, így kvázi duplán jelentek meg (nem egymás után, de ha visszagörgettem feljebb, akkor láttam)). Ezért csináltam meg így, hogy amit már egyszer megjelenített, újra nem fogja.Ha fontos az időben csökkenő rendezés, akkor én tennék egy select * from ( ) order by date desc-et az unionok köré.
Itt nekem az a lényeg, hogy az 5 táblából a lapra a bejegyzések időrendi sorrendben kerüljenek. Tehát ha a legfrissebb a table2-ben van, akkor azt jelenítse meg először. Ha a második és harmadik legfrissebb a table4-ben, akkor utána azokat. Lehet, hogy a table1-ben lévő bejegyzések csak a sokadik 4-es csoportban jelennek majd meg, mert annyival régebbi bejegyzések.Logikus teljesen, amit írsz, csak át kell gondolnom, hogy nálam miért jeleníti meg pont úgy, ahogy én akartam - ellenőriztem milliószor az időbélyegzőket is.
Köszi, hogy felhívtad rá a figyelmem, átnézem majd még egyszer.
Tehát ha az első lekérdezést nézem (ahol még nincs kizárva egy ID sem), akkor egy zárójelpár hozzáadása a megoldás, igaz? Így:
(SELECT * FROM table1UNION ALLSELECT * FROM table2UNION ALLSELECT * FROM table3UNION ALLSELECT * FROM table4UNION ALLSELECT * FROM table5)ORDER BY date DESCLIMIT 4Legalábbis elvileg, lehet, ez így hibára fut, nem tudom, csak este/holnap tudom majd kipróbálni.
Ez visszaadja a 4 legfrissebb bejegyzést, majd a következő lekérdezés már ennek a 4-nek az ID-jait kizárja, pl. így:
(SELECT * FROM table1UNION ALLSELECT * FROM table2WHERE id NOT IN (1)UNION ALLSELECT * FROM table3UNION ALLSELECT * FROM table4WHERE id NOT IN (1,2)UNION ALLSELECT * FROM table5WHERE id NOT IN (1))ORDER BY date DESCLIMIT 4Így lesz a jó?
Köszi.
-
nyunyu
félisten
Az 5 táblában 5 különböző forrásból származó bejegyzések vannak, jellemzően több száz (idővel több ezer), ezért vannak már eleve külön táblákba mentve.
Erre felesleges 5 táblát fenntartani, elég lenne egy tábla is, amibe felveszel egy pár karakteres új oszlopot, amibe az forrás azonosítóját írod, aztán ha forrásra kell szűrni, akkor beírsz plusz egy where feltételt a lekérdezésbe.
Amúgy meg kimaradt a külső select:
SELECT *
FROM
(SELECT * FROM table1
UNION ALL
SELECT * FROM table2
UNION ALL
SELECT * FROM table3
UNION ALL
SELECT * FROM table4
UNION ALL
SELECT * FROM table5)
WHERE ID NOT IN (...)
ORDER BY date DESC
LIMIT 4;Hello IT! Have you tried turning it off and on again?
-
nyunyu
félisten
válasz
sztanozs
#4932
üzenetére
'NOT IN' elég pazarló (legalább is az én ismereteim szerint), persze lehet, hogy a modern motorok már átalakítják kevésbé lassabbakra.
Tizenéve már azt tanították az egyetemen, hogy mindegy, úgyis átalakítja left joinra az optimalizáló.
Gyors futáshoz LEGYEN index a vizsgált mezőn.A LIKE-ok meg szerintem mindegy milyen scope-ban futnak.
Na, az az igazán pazarló, pláne, ha %-gal kezdődik a lájkolnivaló, mert akkor semmilyen indexet nem tud használni hozzá, hanem mindig full table scan lesz a vége.
Ha csak 'valami%'-ra alkalmazod a facebook filtert (vagyis ismert a string eleje), akkor legalább a keresendő oszlopra rakott indexből tud dolgozni.Hello IT! Have you tried turning it off and on again?
-
Taci
addikt
Ez így valóban jó ötlet. Csak sajnos már mindent a külön táblákra felépítve csináltam meg. De ha azt mondjátok, hogy nagyságrendekkel gyorsabb/hatékonyabb/(nem tudom, mit kellene még itt figyelni) lenne ezzel a szerkezettel, akkor rászánom az időt, és átírom az elejétől kezdve.
Kezdjek neki, vagy azért nincs akkora hátránya az 5 táblából való adatszerzésnek a 1 táblával szemben? Főleg úgy, hogy tényleg csak 4 bejegyzést kérek el egyszerre. (Bár amúgy az 5 tábla a jelenlegi struktúrával fel fog szökni kb. 20 táblára.) -
Taci
addikt
Ha csak 'valami%'-ra alkalmazod a facebook filtert (vagyis ismert a string eleje), akkor legalább a keresendő oszlopra rakott indexből tud dolgozni.
Kereséshez használom, így sajnos nem ismert a sztring eleje, mert a keresett szó bárhol lehet, sor elején, közepén, végén, így muszáj vagyok (jelen ismereteim szerint) így keresni:
LIKE '%szoveg%' -
Taci
addikt
válasz
sztanozs
#4939
üzenetére
Ha jó keresési találatokat nézek, akkor ez az, ugye? (Soha nem hallottam még róla, és amikro azt kerestem anno, hogy tudok keresni szavakra, a LIKE-ot dobta a legtöbb oldal, ezért kezdtem el ezt használni.)
WHERE CONTAINS ((title, description),'"szoveg1" AND "szoveg2" AND "szoveg3"')Ha ez így helyes, akkor ugye mindkét helyről (title, description) ad vissza találatokat, akár egyikben, akár másikban, akár mindkettőben van találat az összes keresett szóra?
@bambano:
Ez azt jelenti, hogy inkább egy táblám legyen csak?
De amúgy tényleg érdekelne, hogy miben/mennyivel "rosszabb", ha több táblában vannak az adatok. Nyilván a sebesség az egyik válasz, ez biztos. De érdekelne, miben még.Úgy szeretném megcsinálni, hogy utána szerkezeti változás miatt ne kelljen már "soha" belenyúlni, ezért veszem a fáradságot és időt és átírom, ezzel nincs baj. Csak érteni is szeretném a miértjét.
Köszi.
-
nyunyu
félisten
Akkor meg pláne most kéne meglépni az egy táblára átállást, mert 20 táblánál már sokkal több időt fog igényelni a refaktorálás.
Amire kell csak figyelni: összes a táblába szúró insertnél legyen kitöltve a forrásrendszer azonosító.
Aztán ha alrendszerenként nagyon sok adat van, és az adatbázis licenszed is megengedi, akkor el lehet gondolkozni a forrásrendszer azonosító menti partícionáláson, amikor partíció kulcsonként külön táblateret használ, és mindegyiknek külön épít indexeket.
Ekkor konkrét azonosítóra szűrve ugyanúgy viselkedik a nagy tábla, mintha önálló táblája lenne az alrendszernek viszonylag kicsi adatmennyiséggel, ha meg nem szűrsz, akkor az alrendszerek tábláinak unióját látod. (ez utóbbi nem annyira hatékony, ha a partíciókulcs nincs a join/where feltételben!)Hello IT! Have you tried turning it off and on again?
-
nyunyu
félisten
Úgy szeretném megcsinálni, hogy utána szerkezeti változás miatt ne kelljen már "soha" belenyúlni, ezért veszem a fáradságot és időt és átírom, ezzel nincs baj. Csak érteni is szeretném a miértjét.
Ha most nem léped meg a refaktort, és később kiderül, hogy valamelyik táblába fel kell venned pár plusz oszlopot, akkor az összesbe veheted fel egyesével ugyanazokat, ugyanabban a sorrendben, különben hibával elszáll az összes union-os lekérdezésed!
Mondjuk ebből a szempontból a select *-os slendriánság sem egy életbiztosítás

Sokkal elegánsabb, és hibatűrőbb, ha egyesével felsorolod a lekérdezendő oszlopokat + insertnél a beszúrandó tábla oszlopait.magyarul mindenhol így nézzen ki a kód:
insert into tábla (oszlop1, oszlop2, oszlop3)
select oszlop1, oszlop2, oszlop3
from tábla2;Ez nem fog megborulni, ha bármelyik tábla szerkezete módosul.
[ Szerkesztve ]
Hello IT! Have you tried turning it off and on again?
-
nyunyu
félisten
De amúgy tényleg érdekelne, hogy miben/mennyivel "rosszabb", ha több táblában vannak az adatok. Nyilván a sebesség az egyik válasz, ez biztos. De érdekelne, miben még.
Leginkább a kód karbantarthatóságról szól a felvetésünk. (meg olvasni, átlátni is könnyebb a rövidebb, egyszerűsített kódot)
Most ha bejön egy új alrendszer/forrás, akkor kézzel definiálsz neki egy új táblát, arra indexeket, meg a meglévő kódbázisban az összes union-os selectet ki kell bővíteni +1 ággal, hogy az új forrást is visszaadja.
Plusz szopni fogsz, ha bármelyik táblába fel kell venni egy plusz mezőt, mert akkor kézzel alter table az összesre, hogy az unionok továbbra is működhessenek...Míg egy táblánál csak az új forrás adatbetöltő rutinját kell megírnod, ami egy új azonosítóval szúrja be a meglévő táblába a rekordokat.
Plusz oszlop igény esetén meg elég egy táblát alterelni, nem fog elszállni a kód (ha ki van mindenhonnan irtva a select * )
)[ Szerkesztve ]
Hello IT! Have you tried turning it off and on again?
-
Taci
addikt
Köszönöm szépen a sok tanácsot, lesz mit átnéznem/átírnom.
De legalább remélhetőleg stabil kódom/adatbázisom lesz. Még erre a full-text search-ös dolgot kell majd ránéznem.
Illetve PHP oldalról megnézni, hogy az új struktúrájú lekérdezésben hogyan tudnám hatékonyan használni a
bind_param-ot. (Ha kell/lehet-e egyáltalán.) -
Taci
addikt
Amire kell csak figyelni: összes a táblába szúró insertnél legyen kitöltve a forrásrendszer azonosító.
Ez alatt ezt érted? (Egy korábbi válasz ugrott be a PHP-s topikból ( [link] ), abban láttam ezt először.)
ENGINE=InnoDBEz miért fontos amúgy? Itt amúgy CREATE-nél van. Hol kell/ajánlott ezt használni?
-
nyunyu
félisten
Gondolom utólag akarsz arra is szűrni, hogy honnan származik az adat.
Most ha quick&dirty megoldást akarsz a meglévő táblákban lévő rekordok egy helyre lapátolására, akkor:
create table ujtabla as
select 'forras1' as forras, t1.*
from tabla1 t1;
insert into ujtabla
select 'forras2' as forras, t2.*
from tabla2 t2;
...
insert into ujtabla
select 'forras5' as forras, t5.*
from tabla5 t5;+ az eddigi kódban minden insertbe beleteszed, hogy az új rekordoknál mivel töltse a forras mezőt.
+ az eddigi táblaneveket mindenhol lecseréled ujtabla-ra
+ létrehozod az eddigi táblákra vonatkozó indexeket ujtabla-ra.Ekkor ha mondjuk külön akarnál selectálni a kettes rendszerből, akkor ezután így fog kinézni:
select *
from ujtabla
where forras='forras2'
and ...
order by date desc;lletve PHP oldalról megnézni, hogy az új struktúrájú lekérdezésben hogyan tudnám hatékonyan használni a bind_param-ot. (Ha kell/lehet-e egyáltalán.)
Nem vágom a PHPt, de gondolom a mezők bindelésénél ki kell cserélni a táblanevet az újra, valamint az új forras mezőnek fixen megadni egy értéket. (Mittudomén kettes webshopnál azt, hogy 'forras2', vagy aminek elnevezted)
[ Szerkesztve ]
Hello IT! Have you tried turning it off and on again?
-

Petya25
addikt
MS SQL-ben kéne valami trükk erre:
Az a problémám, hogy az egyben futtatott több tárolt eljárás előtt újra és újra kell inicializálni a változókat, nem tudom a kód futásban lejjebb a már fenti változót használni.
A tárolt eljárást többször futtatnám és az eredményét minden körben betolom egy átmeneti táblába.1. futás
-- a tárolt eljárás az eredményt eleve egy átmeneti táblába teszi: ##tfo_tomb2
declare @th char(1) = 'F', @dtol datetime = '2021.01.01', @dig datetime = '2021.04.30'
EXECUTE [tfo] @th ,@dtol ,@dig
GO
-- az eredményt elmentem és dobom a temp táblát
select 'F' as th, datum, telepo, ossz
into #tetel_ora
from ##tfo_tomb2drop table ##tfo_tomb2
2. futás
-- na itt már nem tudom használni a fenti változókat újra kell inicializálni őket
declare @th char(1) = 'G', @dtol datetime = '2021.01.01', @dig datetime = '2021.04.30'
EXECUTE [tfo] @th ,@dtol ,@dig
GOinsert into #tetel_ora
select 'G' as th, datum, telepo, ossz from ##tfo_tomb2drop table ##tfo_tomb2
--és ezt még párszor megteszem a @th változó cserélgetésével, de az a rész a kódban
--fix "set" lehetne, viszont a dátumot csak 1x állítanám az elején, de nem eszi meg....[ Szerkesztve ]
Antonio Coimbra de la Coronilla y Azevedo, bizony!
-
-
Ispy
veterán
válasz
 Petya25
#4948
üzenetére
Petya25
#4948
üzenetére
Nem lenne jobb egy etető eljárás? Azt meghívod a paraméterekkel, megcsinálja az insertet és fut a következő.
Egyébként meg simán declare az elején, utána meg set @a=1 vagy set helyett lehet select is, ha nem változik az értéke, akkor meg nem írod felül.
Már ha jól értem mit akarsz.
Egyébként meg a GO miatt dobja a deklarációt, mert az a kódblokk vége, onnantól új kód fut.
Szóval valami ilyesmi kellene:
Declare rész
.
.
Set variables
Exec sp1
.
.
.
Set variables
Exec sp2
.
.
.
Set variables
Exec sp3
.
.
.
GO[ Szerkesztve ]
"Debugging is like being the detective in a crime movie where you're also the murderer."








 )
)
















 Nagyon köszi a linket, áttanulmányzom!
Nagyon köszi a linket, áttanulmányzom! 
![;]](http://cdn.rios.hu/dl/s/v1.gif)






 )
)

Új hozzászólás Aktív témák

- APPLE MacBook Air 2020 13" Retina - M1 / 8GB / 256 GB SSD / MAGYAR / 96% akku, 81 ciklus / Garancia
- LG NanoCell 55NANO766QA Halvány píxel csík
- Philips 58PUS8545/12 1 ÉV GARANCIA Játék üzemmód
- Tyű-ha! HP EliteBook 850 G7 Fémházas Szuper Strapabíró Laptop 15,6" -65% i7-10610U 32/512 FHD HUN
- Bomba ár! HP EliteBook 840 G5 - i5-8G I 8GB I 128GB SSD I 14" FHD I HDMI I Cam I W10 I Gari!