-

GAMEPOD.hu
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-

Abu85
HÁZIGAZDA
válasz
 #32839680
#47061
üzenetére
#32839680
#47061
üzenetére
Mármint egy olyan bejegyzés, hogy némelyik felhasználó még mindig jelzi, de ugye ezzel sokat nem tudnak mit kezdeni. A korábbi black screen bugot azért sikerült javítani, mert a meghajtó okozta, de azóta nem igazán tudnak semmit sem reprodukálni. Ahogy írtam, ezekkel a black screen bugokkal mindig az a baj, hogy akármelyik komponens okozhatja, és az eredménye ugyanúgy az, hogy elmegy a kijelzőn a kép. Kb. olyan, mint a Kernel Power 41 hiba a Windows operációs rendszeren belül. Az oka lehet akármi, táp, vinyó, memória, proci, alaplap, stb., és a user csak annyit lát belőle elfeketedett a kijelzője, mert leállt a rendszer.
Az Edge böngészővel kapcsolatban van egy ilyen ismert bug, de az is csak a többkijelzős konfigokra vonatkozik.
A Windows frissítések mindig ilyenek. Én ezek miatt sosem frissítek azonnal, hanem csak három hónap múlva. Az MS-nél is olyan durva hibák vannak felsorolva, hogy tudnak róla, hogy jobb ezzel várni. Különösebb hátrányod ebből nem lesz, mert úgy sem szokták azonnal kihasználni az alkalmazások az új Windows 10 verziók frissítéseit.
A memóriára lehet fejleszteni hasonló dolgokat, de a lényeg, hogy ez hardveres tényező. Ha engedik, akkor villogni fog a kijelző. Amiért nem nagyon törődnek ennek a fejlesztésével, hogy a memóriák relatíve kis fogyasztók maradtak. Tehát egy többmonitoros idle konfiggal 6-8 wattot, ha nyersz, HBM2-vel 1 wattos se, miközben az üzemeltetése egy ilyen hardveres rendszernek több kijelző mellett eléggé bonyolult.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Ez nem kötekedés. A black screen sokszor a meghajtó nyakába van varrva, de valójában ritkán van köze hozzá. A Google-ön le tudod keresni, hogy 136 milliószor van ez említve az NV-vel, és nagyjából hasonló mennyiségben, 130 milliószor az AMD-vel. A probléma az, hogy alapvetően minden komponenshibánál fekete képernyőt kap a user, és mi van a képernyőre kötve közvetlenül? Igen, a GPU. Tehát sokan ehhez a komponenshez kötik a problémát. Pedig okozhatja ezernyi más komponens is.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
#32839680
#47066
üzenetére
A BSOD abból a szempontból kellemesebb, hogy az eseménynapló konkrétan leírja, hogy melyik modul az oka. Tudod az idejét a hibának, és meg kell nézni, hogy mitől van. A gyanakvással nem mész semmire. Én mindig is általánosan javasoltam, hogy ha van egy kékhalálja, akkor az első dolga legyen utána felütni az eseménynaplót, és megnézni az okát. Ezeket a rendszer kritikus leállásként jelzi. És akkor találgatni sem kell, kerek-perec le van írva, hogy mitől van. Sajnos nagyon sokan nem veszik erre a fáradtságot, talán nem akarnak pazarolni a probléma felderítésére négy égérklikket. Számukra nem javaslom a PC-t.
(#47067) b. : Nem kell azért hardvert cserélni, hogy kiderüljenek az egyes problémák okai. Erre van a Windowsban az eseménynapló. Alapértelmezett beállítással igen hosszú időszakra rögzíti, hogy mi történt. Elég megkeresni a kritikus hibákat, mert azok számítanak. A többi dolog nem igazán lényeges. A találgatások helyett én mindenképpen a célzott problémaelemzést javaslom. Sokkal hatékonyabb. Nem véletlenül vannak ezek a szervizfolyamatok beépítve az operációs rendszerbe.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Oké, szóval aranyos pletykák azok, amelyek szerint alig csökken majd a sebesség az új Radeonon, de én is leírtam, hogy ez nem ilyen egyszerű. [link]
Igen egy csomó helyről hallani, hogy mindössze 10% körüli az RT bekapcsolása az RDNA2-n, de nagyon fontosak a részletek.
A DXR 1.0 eleve egy rendkívül korlátozott dizájn, nincs támogatva benne egy rakás teljesítménykritikus funkció, például az executeindirect, csak memóriapazarló FP32-es vertex formátum van, meg a shaderek meghívása egy bekötési táblára épül, ahol ide-oda kell másolgatni egy csomó adatot az egyes shaderek között, ami rakás felesleges memóriaműveletet jelen. Meg kell csinálni, mert így működik a rendszer, de amúgy rohadt pazarló az egész, mert sokkal jobb megvalósítása is van ugyanannak a problémának.
A DXR 1.1 egy lényeges evolúciós lépcső, amit a Microsoft a gyártókkal közösen dolgozott ki, nem csak az AMD-vel, hanem mindenkivel. Megoldja a tipikus hiányosságokat, van executeindirect, sokkal szabadabb a vertex formátum megválasztása, illetve kidobja a bekötési táblát, és ezzel együtt azt a sok tök felesleges és alapvetően nagyon lassító adatmenedzselést. Itt már az alapvető működés pusztán sokkal nagyobb teljesítményt ad, mint DXR 1.0 mellett, mert maga az inline raytracing jelentősen kevesebb megkötéssel implementálható. Tehát a sugárkövetés már attól sokkal gyorsabb lesz az új hardvereken, hogy DXR 1.1-re implementálják és nem DXR 1.0-ra. És ez nem csak az RDNA2-re vonatkozik, hanem az Ampere-ra is, annak is a hardvere ehhez igazodik, tehát nagyjából ugyanakkora tempóelőnyt szed fel vele az NVIDIA, mint az AMD.
A jövőben a Microsoft az inline raytracinget fogja fejleszteni, egyszerűen ez a gyorsabb megoldása a problémának, de még a DXR 1.1-nek is vannak hiányosságai. Például nem alkalmaz teljesen konfigurálható BVH bejárás. Ennek az oka, hogy a gyártók eltérő BVH adatstruktúra-formátummal dolgoznak, és ezt nem mindenki nyitja meg. Márpedig ha ezt nem ismerik a fejlesztők, akkor nem tudják a korlátjait, nem tudják, hogy hova kell optimalizálni a nagyobb sebességhez. A sugárkövetés jelenleg PlayStation 5-ön a leggyorsabb, de csak azért, mert ez a konzol lehetőséget ad arra, hogy egy compute shaderben egyedi BVH bejárást írjanak a fejlesztők, így egy csomó olyan teljesítménykritikus algoritmus válik megvalósíthatóvá, amire például még a DXR 1.1 sem ad lehetőséget. De végeredményben ez is pusztán egy szoftver, a hardver megismerésével tudod, hogy mit kell kezdeni vele, így pedig nyilván nem nehéz olyan RT effektet csinálni, ami a DXR 1.0-ban megszokottnál nagyságrendekkel gyorsabban fut, miközben ugyanazt az eredményt adja. Szerintem azok az eredmények, amelyeket hallani az RDNA2-ről, a Radeon Rays 4.0 kiegészítésekből származnak, amelyek ugyanúgy megengedik majd PC-n a compute shaderből szabadon konfigurálható BVH bejárást a DirectX Raytracinggel. Az pedig nem újdonság, hogy a hardverek gyorsak tud lenni, ha optimalizálásban lemész a legalacsonyabb szintekig. De ez a sebesség nem ültethető vissza a natúr DXR 1.1-re, pláne nem a sokkal lassabb DXR 1.0-ra.Hosszabb távon a Microsoft dolgozhat azon, hogy szabványosítanak egy BVH adatstruktúra-formátumot. Ma ez azért baj, mert eléggé sok alternatíva van. Az Intel sajátot használ, az NVIDIA is, az AMD is, de legalább a konzolok ugyanazt használják, amelyiket az AMD. Tehát részben van már egy közös pont. Innen az lenne a lényeges, hogy ezt a közös pontot kiterjesszék. Ez részben egy licencelési probléma is, mert itt nem csak az Xbox Series X-ről van szó, hanem a PlayStation 5-ről is, és bizonyos IP-k, amelyek vannak az RDNA2-ben azok a Sony fejlesztései, de az AMD, a Microsoft és a Sony keresztlicencben dolgozik (de részben emiatt zártak a Radeon Rays 4.0 egyes részei, mert nem 100%-ban az AMD megoldása, hanem egy Microsoft-Sony-AMD kooperáció). Na most ezt ki kellene terjeszteni az Intelre és az NVIDIA-ra is, meg még azokra a gyártókra, akik jönnének, tehát meg tudom érteni, hogy jelenleg miért nincs szabadon konfigurálható BVH bejárás a DXR 1.1-ben, de előbb-utóbb itt is megegyeznek majd, mert úgyis erre kell menni az egyes algoritmusok megvalósíthatósága érdekében. Viszont ehhez ugye kell egy licencszerződés, ha az megvan, akkor el kell kezdeni tervezni az új hardvereket, immáron az érkező, egységesített BVH adatstruktúra-formátumra, stb. Szóval ez időben sokáig fog tartani.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Offline ez bevált dolog, de a real-time nem ennyire egyszerű. Utóbbinál azért nagyobb hátrány az adatmásolás per sugár, mint annak az előnye, hogy külön dedikálsz a sugárkövetésre egy GPU-t.
Ami működőképes lehet az a teljes feldolgozás felosztása, például AFR-rel, vagy SFR-rel, de leginkább valami scissor modellel. Vagy írnak egy olyan motort, ahol az árnyalás függetlenített a leképezéstől, így pedig az árnyalási munkák leoszthatók egy csomó GPU-ra, és lenne egy szem fő GPU, ami csak a leképezést csinálja.
A DXR 1.0, a DXR 1.1, illetve a Sony megoldása is brute force. A különbség az, hogy mennyire pazarlóan vagy hatékonyan bánik a rendelkezésre álló hardverrel. De az eredményük ugyanaz. Itt gondolj arra, hogy a megjelenített kép tekintetében a DirectX 11 is ugyanazt csinálta, de eközben a DirectX 12 többszálú optimalizálásával egy csomó rajzolási parancsra levetítve sokkal gyorsabb. Mindkettő API brute force, csak az egyik pazarló, míg a másik hatékony. A DXR 1.0 és a DXR 1.1 esetében nem mindegy, hogy például a DXR 1.1-gyel már amikor találatkor, vagy találat nélkül a függvény visszatér, akkor helyből ott a kontextus struktúrája a shaderben. Nem kell azt bekötni, hogy egyáltalán folytatni lehessen a számítást a hit vagy miss shaderrel. Egy csomó adatmozgást megszüntetsz ezzel a lapkán belül, miközben a számítás része ugyanaz marad. Ha ez nem számítana, nem nyomtak volna egy ekkora resetet az inline raytracinggel.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 Jack@l
#47100
üzenetére
Jack@l
#47100
üzenetére
Természetesen a raszterizálás is real time render, meg a nagyon szar minőségű sugárkövetés, csak gondolom hibrid sugárkövetésre gondolt X2N, vagyis nem olyanra, ami marha ronda egy full statikus környezettel. Nem olyan egyszerű ezt megoldani. A legfőbb probléma az efféle modellen ugyanaz, ami a raszterizálásnál. A geometria kezelése teljes lesz, tehát lehet, hogy az effektek, illetve a raszterizálás szintjén csak a kép negyedét számolod, de minden másban a négy kártya egyszer-egyszer kiszámolja ugyanazt. A legjobb módszer ennek az elkerülésére az, ha szétválasztják a leképezést és az árnyalást a motor szintjén, és akkor lesz egy GPU a leképezésre, és be lehet fogni egy rakás másik GPU-t árnyalásra. De ezzel meg az a probléma, hogy nagyon speciálisan írt motor kell ám hozzá. Nem kétlem, hogy erre elmehet az ipar, hiszen a Nitrous már így dolgozik, csak ez nagyon sok fejlesztés kérdése, a fejlesztés pedig idő.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#47102
üzenetére
Ami nem hibrid az vagy nagyon szar minőségű, vagy nagyon lassú. A kettő közé hozták a hibridet.
A Nitrous csak egy példa. Lehet írni olyan működésű motorokat másnak is. De mint írtam a gond az, hogy ez időbe kerül. Ellenben addig nem tudod a GPU-k között szétosztani az árnyalási feladatokat, amíg a motor szintjén nem szeparálod el ezt a leképezéstől.
Az Oxide egyébként kizárólag a Nitrous motor eladásaiból él. Nincs semmi más technológiájuk.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 paprobert
#47104
üzenetére
paprobert
#47104
üzenetére
A konzol lényegtelen a több GPU szempontjából.
Az a mester-szolga modell a GPU-knál, amit felvázoltam, már ma is működhet. Ehhez nem kell se új hardver, se új API, csak írni kell egy olyan leképezőt, ahol az árnyalás függetlenített a leképezéstől. És akkor egy GPU utóbbit megoldja, a többin pedig arányosan elosztod az árnyalási feladatokat. Ehhez minden megvan most a PC-ben. Akarat nincs a fejlesztés oldalán hozzá. Elsődlegesen az a baj, hogy viszonylag nagy változásról van szó, és az sok pénzbe és időbe kerül, amit pedig ha felvezetsz a vezetőségnek, akkor rácsapnak az asztalra, hogy lófa... vagyis nyugodtan interpretálják, hogy erre nincs pénz és idő sem.
Szóval én olyan nagyon nem várnám a több GPU-s Kánaán visszatértét, de persze örülnék, ha mégis jönne.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Azt nagyon sokára fogják elérni a játékfejlesztők. Talán 2030-ban. És valószínűleg segítene, ha rakhatnál mondjuk 8 GPU-t egy gépbe, de ehhez tényleg kell egy Nitrous-szerű motor. És akkor újra ott vagyunk, hogy pénz és idő.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Még úgy is sok terhelés sajnos. Majd úgy két generáció múlva.
(#47109) X2N: Még nincs olyan denoiser, de a Microsoftnak rengeteg aktív projektje van az Xbox Series X-hez, amelyek még nincsenek kész. Ezek között AI felskálázó és denoiser is van. Ezek természetesen direkten menthetők PC-re is. Szóval annyira nem reménytelen a helyzet.

(#47110) Jack@l: Olvasd el, amit X2N írt. Ezek miatt a raszterizálás egy ideig marad. Évekig még. Az effektek szintjén azonban a sugárkövetés aktívan alkalmazható.
Mint írtam a PlayStation 5-ből nem szabad kiindulni. Annak az API-ja olyan algoritmusokat enged meg, amelyekre a DXR 1.1 sincs felkészítve a compute shaderből szabadon konfigurálható BVH bejárás hiányában. Ekkora szoftveres hátszéllel könnyű arcoskodni, de valójában az egész csak szoftver. A PC-s hardverek is képesek lennének ugyanerre, ha lenne hozzájuk megfelelően megszabott specifikáció az API oldalán. De mint írtam a gyártók egyelőre nem egyeztek meg arról, hogy legyen egységes BVH adatstruktúra-formátum, így pedig nehéz szabványosítani a Microsoft számára, mert többféle különböző adatstruktúra-formátumra nem tudják felhúzni a teljesen konfigurálható BVH bejárást.
A hibrid RT nem kötelező. A PlayStation 4-re is van csak sugárkövetéssel dolgozó, nulla raszterizálást alkalmazó játék. Valószínűleg lesznek olyanok, akik az új generációban is megpróbálkoznak ezzel, de mindenképpen limitációkat jelentenek a mai hardverek. Meg a pár generáció múlva érkezők is.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
7 nm-en se lenne más. Ahogy korábban írtam, a FinFET a végét járja, tehát kell két-három generáció, mire elkezded úgy használni, hogy jönnek az órajelek. Lásd AMD. Ők sem kezdtek 2 GHz-en az első két 7 nm-es dizájnnál, de a harmadikat már 2 GHz fölé lövik. Nem változott semmi, csak az elmúlt két évben megismerték a gyártástechnológiát.
Sajna ez ilyen. Az egyik megoldása ennek a problémának, hogy a lehető leghamarabb GAAFET-re kell lépni.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#47212
Abu85
HÁZIGAZDA
KillerKollar
#47209
Abu85
HÁZIGAZDA
válasz
 KillerKollar
#47209
üzenetére
KillerKollar
#47209
üzenetére
Igen, de az RDNA2 és 3 között nem lesz akkora különbség, mint az RDNA1 és 2 között.
Eredetileg igen, két év szokott lenni generációk között, de az AMD már máshogy tervez. Pont azért, hogy a két éves ugrásokat, évesre csökkentsék. Valójában nem egy új mag fejlesztése a nehéz, mert az viszonylag gyors. A gondot a teljes lapka jelenti, viszont a Zen 2-es chiplet dizájnnal már elég csak a chipletet váltani és kész. Ezért tud mostantól évente új mag jönni.
(#47210) Pinky Demon: A Zen1-Zen2 ugrás valójában nem volt túl nagy technikailag. Inkább volt optimalizálás, plusz egy kis izmosítás. A Zen2-Zen3 ugrás lesz a nagyobb, mivel mélyebben is hozzányúlnak a dizájnhoz. Ugyanígy a Zen3-Zen4 ugrás sem lesz túl nagy technikailag. Hasonló optimalizálás és izmosítás, ahogy a Zen1-Zen2. Ez tök ugyanaz a tick-tock modell, amit az Intel csinált anno, csak kicsit más lépcsőkkel.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#47217
üzenetére
Igen. A fő különbség a régi fejlesztési modellhez képest, hogy iszonyatosan sok erőforrást spórolnak azzal, hogy egyetlen CPU chiplettel fedik le az asztali piac aljától kezdve a szerverpiac tetejéig tartó területet. Az Intel ehhez például fél tucat lapkát tervez generációnként. Az AMD már nem erre költi az erőforrást, hanem átrakja oda, ahol még több lapkát kell tervezni. A processzorpiacot minden évben megoldják egy picike chiplettel.
(#47215) KillerKollar: Most csak azért tűnik ez gyors elavulásnak, mert megint gyorsan fejlődnek az API-k, de ez is megtorpan majd. Utána különösebb hátrány nélkül lehet egy adott generáción maradni.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#47230
Abu85
HÁZIGAZDA
KillerKollar
#47228
Abu85
HÁZIGAZDA
válasz
KillerKollar
#47228
üzenetére
Nem. Az RDNA3 célja teljesen más. Ez a dizájn nem sokban fog különbözni az RDNA2-től a lapkát tekintve, csak megkapja a CDNA2 architektúra belső buszát, ami már fel van készítve az Infinity Fabric 3.0-ra. Az RDNA2 ugyanazt a belső buszt használja, amit az első CDNA, plusz ezt használják a konzolok is, de ez mindegy.
A Zen 4-nél az AMD már támogatja a host oldalon is az Infinity Fabric 3.0-t. Ebből lesz majd a Genoa platform, ahol nem is PCI Express interfésszel kötöd be a CDNA2-t, hanem Infinity Fabric 3.0-val. Itt egy kép a topológiáról, ami a szerverpiacra vonatkozik:
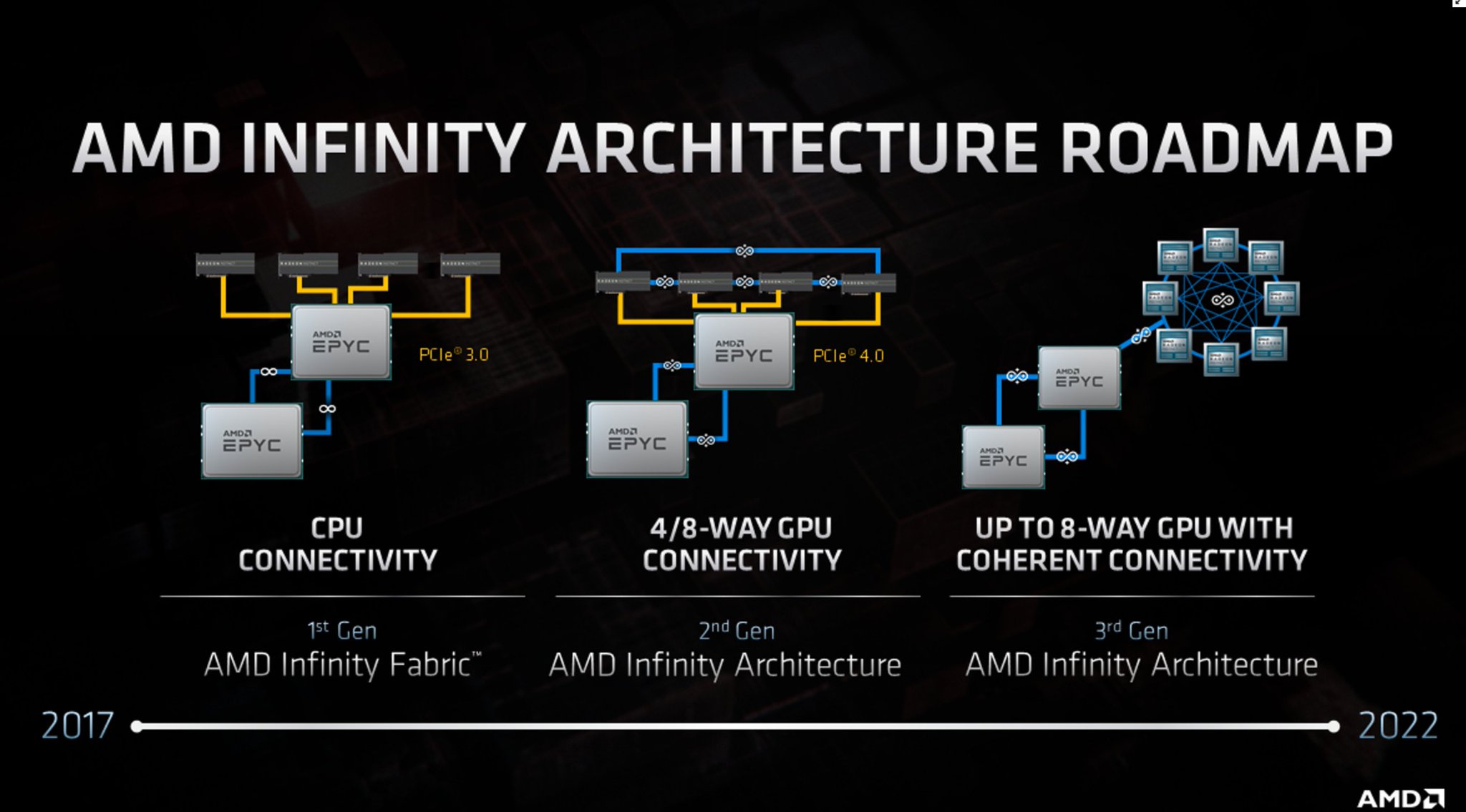
A mai tipikus felépítés az első részen látható. A középső majd a Milan és a CDNA párosítása, míg az utolsó a Genoa és a CDNA2.
Ez az irány részben le fog jönni az asztali piacra is, hiszen baromira nagy előny egy workstation esetében, hogy bedobsz nyolc GPU-t a CPU-hoz, és ezek ugyanazt a memóriaképet látják. Az RDNA3 erre fókuszál, hogy ezt a fajta összeköttetést megvalósíthassa a Threadripperekkel, amelyek nyilván a Zen 4-es EPYC processzorok asztali verziói lesznek, ahogy ma is. Azt nem tudni, hogy a normál Ryzenekig lejön-e ez a koncepció.Szóval az RDNA3 nem igazán architekturális fejlesztés, hanem platformszintű. Az a lényege, hogy a PCI Express mellé felkínáljon egy sokkal gyorsabb és egyben memóriakoherens összeköttetési formát. A szabvány amúgy is erre fog menni, de az még évek kérdése, talán majd a PCI Express 7.0-val lesz egy hasonlóan gyors, szintén memóriakoherens alternatíva. De ez is nagybetűs Talán!... Nem igazán akar rá várni az AMD, bedobják a saját zárt rendszerüket, aztán mindenki, aki haladni akar előre és nem várni éveket egy szabványra, az veheti is meg. Szerverszinten és a workstationök területén biztos lesz rá igény, hiszen ott a teljesítmény az pénz. Konzumer szinten azért kétséges, de az AMD számára a szerver és a workstation már bőven elég indok a bevetésre.
Fun fact, de ugyanezt csinálja az Intel a Sapphire Rapids esetében. Nekik is lesz egy zárt kiegészítésük, amit csak ők támogatnak, így ha a next-gen Xeonhoz majd Intel Xe gyorsítót veszel, akkor kapsz memóriakoherenciát. Aztán, hogy ennek lesz-e workstation verziója... papíron lehet.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#47242
Abu85
HÁZIGAZDA
Petykemano
#47238
Abu85
HÁZIGAZDA
válasz
 Petykemano
#47238
üzenetére
Petykemano
#47238
üzenetére
Úgy tud majd működni ettől, mint az új konzolok.
De elsődlegesen valószínűleg a professzionális piac a célpont. Ott azért nem kis haszon, ha összekötsz mondjuk 8 darab 16 GB-os GPU-t, amihez dobsz még hozzá a CPU oldaláról akár 256 GB memóriát. Csináltál a rendszeredből egy nagy, APU-ként működő konfigurációt, összesen 384 GB memóriával.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 apatyas
#47243
üzenetére
apatyas
#47243
üzenetére
A fizikai megvalósításról nem beszélt az AMD. Persze elképzelhető, hogy PCI Express kiegészítést terveznek, és akkor azon keresztül valósítják meg ezt. Ilyen a CCIX is, de ez nem biztos.
A programozásban lesz különbség. Ez a kép jól szemlélteti:

Az első egy normál CPU-ra írt kód. A második egy memóriakoherencia nélküli GPU-ra írt kód, míg a harmadik az a kód, amit majd a Infinity Fabric 3.0-val kell beírni, hogy a GPU-n fusson. Gyakorlatilag eltűnik az adatmásolásra vonatkozó része a kódnak.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#47245
üzenetére
Egységes memóriaképet látnak a hardverek. Azért nincs szükség a középen lévő kódsorokra. Az a parancs arra szolgál, hogy ne a CPU-n fusson a kernel, hanem a GPU-n.
Ez ugyanaz a koncepció, amikor az IBM Power CPU mellé direkten NVLinken keresztül kötöd be az NV gyorsítóját. Csak az AMD esetében ez nem IBM Power CPU-val, hanem x86/AMD64-gyel fog működni. A link miatt kizárólag EPYC-en, mert kell a vezérlő a host processzorba, ahogy az NV-nél is kell egy NVLink a prociba a direkt bekötéshez. Az Intel is ugyanezt csinálja az Xe-hez, az Xeonokkal fog működni.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#47249
Abu85
HÁZIGAZDA
Petykemano
#47248
Abu85
HÁZIGAZDA
válasz
Petykemano
#47248
üzenetére
A közös memóriakép a hasznos. Ma a GPGPU-s kódok jelentős részét az emészti fel, hogy a host memóriából másolod a VRAM-ba az adatot, vagy több GPU esetén az egyik GPU VRAM-jából a másikba. Ebből áll a kódok jelentős része. Az új modellel ezeket a kódokat be sem kell írni. Ezzel egyrészt tovább tudsz skálázódni. Nem véletlen, hogy az 1 EFLOPS-os rendszereket már ilyen konfigurációra építik. Másrészt olyan dolgok lesznek megvalósíthatók a rendszeren, amelyek korábban csak nagyon nehézkesen működtek.
Ezek az okai annak, amiért az AMD, az Intel és az NV is memóriakoherens interfészben látja a gyorsítók jövőjét. És persze amíg erre nincs egy szabvány, addig a processzor oldalán beépített vezérlőben kell támogatni a zárt interfészt.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#47250
üzenetére
Jelentősen más allokációkat másolni, mint csak lapokat címezni. De manuálisan nem tudsz olyan jó kódot írni, hogy csak a szükséges lapot címzed, és csak azt másolod például, ezért hiába kell az allokációból csak mondjuk 4 kB-nyi adat, át kell másolni a teljes allokációt, ami például lehet 100 MB is lehet. Tehát 4 kB-nyi adatigényért 100 MB-tal terheled a buszt, és az adott GPU VRAM-jába 99,9%-nyi olyan információt másolhatsz, amit lehet, hogy nem is fog használni. Ezért jobb ezt a problémát hardveresen kezelni, mert a hardver már meg tudja tenni, hogy csak annyi információt kér, amennyit címez, tehát nem terheled a rendszert teljesen felesleges másolásokkal.
A fentiek miatt van az, hogy az NV az NVLINK-kel sok GPU-t tud egy hostra rákötni. Az NVLINK memóriakoherens, tehát a skálázhatóságot a hardver már az interfészből biztosítja egy pontig, nem függ jelentősen a programkódtól. Az AMD is közel lineáris skálázhatóságot mond a friss diákon a CDNA-ra IF 2.0-val, ami reális is, ugyanúgy memóriakoherens az interfész.
Az Infinity Fabric 3.0 ezeknek a modelleknek a kiterjesztése. Nem csak az összekötött GPU-kkal biztosít memóriakoherenciát, hanem a teljes rendszeren belül.Ezek az NV, az AMD és az Intel oldalán is mind ugyanazok, csak más névvel, más interfésszel. A koncepció azonban a hatásfok drasztikus növelése, ami jelenleg a béka segge alatt van, de pont azért építik ezeket a gyártók, hogy jó legyen, és eközben még a programozási nehézségeket is megoldják. Igaz ennek rövidebb távon az lesz az ára, hogy AMD CPU-hoz AMD GPU-t, Intel CPU-hoz Intel GPU-t, NV GPU-hoz pedig valamilyen NVLinkes CPU-t kell venni. Nyilván ezért tárgyal az NV az ARM-mal, mert az IBM-től áttörést nem várnak, abban pedig nem bíznak, hogy az Intel és az AMD odaengedi őket a rendszereik közelébe, tehát kell nekik az ARM, hogy ezt az irányt ők is kiteljesítsék. Ez megérne még 50 milliárd dollárt is. Annyi hitelt biztos kapnak, és akkor követni fogják az AMD-t és az Intelt, vagyis teljes házon belüli platformot kínálnak memóriakoherenciával. Ez kritikus, hogy a jövőben esélyük legyen EFLOPS-os rendszerekbe kerülni, mert egyelőre ezeket viszi az AMD és az Intel, csak azért mert ők fel tudják kínálni a szóban forgó funkciót. Nem véletlen, hogy nem vegyítik ezen a szinten a gyártókat. Persze lehet bízni a szabványban is, de a CXL szabványosítása még a PCI Express 7.0-nál is csak opcióként merült fel. Az még sok-sok év, és ki tudja, hogy tényleg szabványosítva lesz-e. Az NV az ARM-mal tudna kínálni egy rendszert 2024 körülre, míg szabványos memóriakoherencia jó eséllyel csak az évtized vége felé lesz.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Én azt nem értem, hogy miért nem megy az ipar a CCIX-re. Az kész, már működik, kiegészítés van a PCI Expresshez, csomó cég használja... Ha csak azt a kiegészítést bevonják a PCI Express 6.0-ba, akkor meg van oldva a dolog. Erre várunk a CXL-re, ami még sok-sok év. Igazából saját magát szopatja az ipar ezzel.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 awexco
#47255
üzenetére
awexco
#47255
üzenetére
Az ARM támogatja a CCIX-et. Van licencelhető IP-jük rá. Az Intelnek és az AMD-nek például nincs ilyen hardverük. Szóval itt az ARM a legnyíltabb, de annak is kell lenniük, mert ők a felzárkózok, míg az Intel és az AMD inkább ezt próbálja gátolni. Az Intel azért, mert védik a piacukat, az AMD pedig azért, mert az Intelt éppen agyonverik, és védik a következő évekre vonatkozó első helyüket. Az ARM például veszélyes lehetne rájuk.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#47264
Abu85
HÁZIGAZDA
Petykemano
#47263
Abu85
HÁZIGAZDA
válasz
Petykemano
#47263
üzenetére
Amihez saját fabricot használnak.
Mondjuk az A64FX inkább hasonlít GPU-ra, mint CPU-ra az ARM SVE-vel.
Be tudják építeni anélkül is az NVLinket, hogy megvennék az ARM-ot, de arra nem képesek, hogy irányítsák az ARM fejlesztéseit. Márpedig az ARM továbbra is általános irányba fejleszt, nekik pedig az nem tökéletes.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
-
Abu85
HÁZIGAZDA
válasz
 Cathulhu
#47279
üzenetére
Cathulhu
#47279
üzenetére
Az Intel egy dinoszaurusz, ott régről származó elvek vannak, és az elveket nehéz rációval felülírni. Ha könnyű lenne, akkor rég Perlmutter vezetné az Intelt. Elmagyarázhatod a befektetőknek, hogy jobb teljesítményt tudna egy tajvani fazon, de nem fogja érdekelni őket, ők akkor is amerikai születésűt akarnak majd, mert az "USA a csúcslegjobb".
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Ez igaz. Két csúcs lesz. Egy sima és egy vizes. Hasonlóan a korábbi csúcsokhoz. A vizes gyorsabb.
Az is igaz, hogy idén csak címkézés lesz, de ez azért van, mert az AIB-knek kell egy kis idő, amíg a gyárinál jobb hűtést terveznek. Tehát idén amúgy sem tudnák bevállalni. Sokan nem veszik számításba, hogy itt az ünnepi szezonra fel kell tölteni a készleteket, vagyis ahhoz, hogy mondjuk Black Fridayre legyenek kártyák az üzletekben, már októberben el kell kezdeni szállítani. Na most a gyártás szempontjából ez azt jelenti, hogy már a gyártósoron kell lennie. Innen maximum a BIOS-t lehet last minute kicserélni, de nincs idő arra, hogy egyedi NYÁK-ot tervezzenek az AIB-k, mert azzal bukják az idei startot.
Több dolog miatt nem szokás custom kártyákkal startolni performance szinten. A legnagyobb ellenérv, hogy a gyártók a régi hűtőrendszerüket reszelnék át az új dizájnhoz, de nulla tapasztalatuk van ezzel, vagyis lehet, hogy rosszul tervezik meg a hűtést. Nem egyszer láttunk már ilyet, például a hőcső nem is ér hozzá a lapkához, stb. Manapság inkább adnak időt a gyártóknak, hogy tervezzenek normális hűtést.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 martin66
#47313
üzenetére
martin66
#47313
üzenetére
Nem mindig megengedő az NV sem. Ez alapvetően a gyártók megítélése. Az biztos, hogy a partnerek számára a karácsonyi szezon fontos, és ezért bármit beáldoznak. Tehát ilyenkor fokozottan kell felügyelni őket, mert képesek piacra dobni egy csomó szar custom dizájnt. Ez az ünnepek miatt hasznos, de aztán csak a probléma lesz belőle, és jönnek a V2 verziók. Nem először történnének ilyenek. Nézd meg hányféle revízió van a custom dizájnokra. Ezt persze úgy írják, hogy jobb lett, ami önmagában igaz, de valójában azért kell a revízió, mert az első custom dizájn szar lett.
(#47314) martin66: Idén csak a nagyok jönnek. A kisebb lapkákból majd jövőre lesz valami.
(#47316) do3om: Senki sem tud sokat a Navi 21 sebességéről, mert még le van zárva a driver. Az AMD már a normál driverekbe is kulcsokat rak, így az OEM-eknél hiába van ott a meghajtó csak a működést tudják ellenőrizni vele, mert az órajeleket random dobálni fogja, így minden benchmark futtatása között lesz 10-15%-nyi teljesítménykülönbség. Ezt egy külön programmal lehet feloldani, ami a meghajtót összeköti az AMD szerverével, majd kap egy kulcsot, hogy teljes sebességgel működhessen a driver. Viszont egy program elindul a kliensen, ami feleszi a munkamenetet, és visszastreameli az AMD-nek, vagyis ha kikerül egy bizonyos 3DMark pontszám, akkor az AMD vissza tudja keresni, hogy az pontosan melyik gépen jött ki, így könnyű elkapni a szivárogtatót.
Emiatt olyan sok leakre ne számítsatok, mert gépre pontosan visszakereshető lett, hogy ki futtatta. Majd a partnerek a megjelenés előtt pár héttel kapnak feloldott drivereket. Akkor jöhetnek csak a pontszámok.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Az NV általában engedékenyebb a gyártók felé, míg az AMD nem. Ez alapvetően technikai kérdés, hogy mi az amit elfogadsz, és mi az amit nem. Az AMD az utóbbi időben szereti, ha a gyártók nem második vagy harmadik nekifutásra csinálnak jó custom dizájnt, hanem elsőre. De ehhez több idő kell, mert nem lehet például felhasználni az előző generációhoz tervezett hűtőrendszert, hanem alaposan át kell tervezni azt. Az NV annyira nem köti meg a partnerei kezét, nem fogja őket érdekelni, ha rosszul állnak a hőcsövek, stb. Aki minőséget szeretne, majd megveszi tőlük a Founders dizájnt. Egyik felfogás se rossz, de azt tudni kell, hogy a gyártók az eladásokból élnek, tehát ha szabadjára engedik őket, akkor karácsonyra kiadják a rosszul tervezetteket is, majd csinálnak V2-es verziót jövőre, ami már jól van megtervezve. Ezzel azért mindkét cég tisztában van.
Nincs annyira sok buktató. Tudják, hogy mit akarnak, és ahhoz terveznek. Ennyi. Olyan közel lesz a start egymáshoz, hogy nehéz gyors módosításokat csinálni last minute szinten.
Azért a memóriával finoman kell bánni. Egyrészt a sok stack drága, és a fogyasztást is megdobja.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
A kiszolgálás szempontjából ez lényegtelen. Lesz x mennyiségű chip, és azokat alapvetően vihetnék a gyártók is, de sokszor nem tesztelik úgy le a dizájnjaikat, ahogy kellene, mert szorít az idő.
A PowerColornál volt ebből probléma nemrég, ugyanis terveztek egy Radeon RX 5700 XT dizájnt, aminél az 5700 csak úgy lett leskálázva, hogy leskálázták a hűtést, miközben mást nem terveztek át. Ebből adódott egy csomó meghibásodás. Konkrétan ebből és ebből többet vittek vissza, mint amennyi amúgy a megszokott normál hibaszázalék. Ellenben ez az 5700-as verziójuk a norma alatti, 2%-os meghibásodási aránnyal ment csak.A látszatra nagy hűtés a szemnek lehet, hogy bizalomgerjesztő, de ha elbaszod a tervezésnél, akkor hiába van rajta! Emiatt mondom az ismerőseimnek, hogy ha tehetik referenciadizájnt vegyenek, mert az tuti jó, ott nem lesz második, harmadik revízió, ahol kijavítják az első fejlesztés hibáit. A custom megoldások esetében akkor szoktak jók lenni a termékek, ha kapnak időt a gyártók. A probléma az, hogy a lapkát eleve később kapják meg, tehát nem lesz annyi tapasztalatuk vele, mint aki letervezte. Ilyen formában rengeteg adat hiányában terveznek köré rendszert, miközben az év vége felé még ott az a gond is, hogy kész kell lenni az ünnepi szezonra, mert ez az elvárás a vezetői szintről. Az esetek egy részében ez nem sül el jól, emiatt jönnek is később a revíziók. Általában akkor, ha a karácsony miatt sietni kell, az ebben az időszakban kiadott VGA-knál igen tipikus, hogy februárban jön az áttervezett variáns. Persze az eredetit nem vonják ki, de hibái lesznek, és ha azokat az orrotokra kötnék, akkor rohannátok a cseréért.
(#47357) Jack@l: Nagy százalékban ugyanannyit RMA-znak. De vannak egyes problémás szériái a gyártóknak. Ezeket második és harmadik revízióval javítják. Ha abszolút minőséget szeretnél, akkor ott a referencia. A custom minden arról szólt, hogy spóroljanak a gyártási költségeken, mert a referenciánál egységár van, és azt részben állja az AMD és az NV.
(#47360) b. : Nem! Az NVIDIA csak megengedőbb. De ugyanúgy nekik is szar, ha xy partnerük szar dizájnt hoz. Ellenben nem kötik annyira meg a partnereik kezét, mint manapság az AMD. EZ jórészt amiatt van, mert az AMD-nek voltak negatív tapasztalatai arról, hogy az utóbbi időben hogyan dolgoznak az egyes gyártók, és nem tekintik jónak. Ha az NVIDIA is belefut ebbe, akkor ők is lépni fognak.
(#47363) do3om: Régebben nem volt ennyire szigorú az AMD, de az 5000-es sorozatnál voltak olyan gondok, amelyekkel korábban nem szembesültek. Például a gyártók a szokásosnál nagyobb mértékben olcsósították a custom dizájnokat.
A custom mindig arról szólt, hogy a referencia az egy drága dizájn, mert ott tényleg igen jó minőségű komponenseket használnak, de ezek hosszabb távon nem érik meg. A gyártók emiatt olcsóbban gyártható terméket terveznek, viszont van egy szint ami alá nem éri meg menni. Ez időszakosan felmerülő probléma, az AMD és az NV mindig úgy reagál, hogy az előző generáció tapasztalatai alapján szigorítanak vagy engedékenyebbek lesznek. Az AMD most szigorít. Ez főleg abban fog kimerülni, hogy több tesztelést követelnek meg a custom dizájnoknál, mert nagyon sok probléma abból ered, hogy kihagynak a gyártók tesztelési lépcsőket, elvégre ha valami a referencián működött, akkor hasonló komponens mellett tuti nem lesz gond customben sem. A gyakorlat viszont azt mutatja, hogy lehetnek gondok.A Navi 21 árban nem lesz olcsó. Végleges árak nincsenek, de a leggyorsabb modell az ezer dollárhoz fog közelíteni. Attól is függ amúgy, hogy az NV hova áraz. Ez egyelőre mozgó célpont, de az Ampere leggyorsabb verziója 1500 dollár környékén lesz. Tehát elképzelhető, hogy az AMD is 1000 dollár fölé megy a vizessel. Annyit halottam még, hogy az AMD ebben a generációban megfizetteti majd a perf/wattot is, mert az RDNA2 ebben lép nagyot előre az RDNA-hoz képest.
(#47372) huskydog17: Sosem azért csinálnak új revíziót, mert az első jól sikerül. Ezek általános dolgok. Ha az új revízió gyorsan követi az elsőt, akkor valami gond volt az elsővel. Ha legalább fél évre rá követi, akkor az új revízió költségcsökkentést céloz. Fentebb írtam, hogy a custom megoldások elsődleges szerepe az alacsonyabb gyártási költség a referenciához viszonyítva, és ez hosszabb távon is fontos, tehát a megjelenés után fél évvel lehetséges olyan helyzet, hogy az első verzióval ugyan nincs gond, de már túl drága gyártani a kezdeti időszakhoz képest, és terveznek egy újabb, olcsóbban gyártható verziót.
(#47376) Z10N: A NYÁK-ot eleve ritkán tervezik újra. Amikor költségcsökkentés miatt terveznek új revíziót, akkor csak a komponensekből választanak olcsóbbakat.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 Yutani
#47381
üzenetére
Yutani
#47381
üzenetére
Ez nem a végfelhasználói árra vonatkozik, hanem a gyártási költségre. Általános, hogy a referenciadizájn előállítása az egyik legdrágább. Ez részben abból adódik, hogy a komponensek tekintetében nincs spórolás, illetve sokszor nincs is kifejezetten komoly beszállítói hálózat a gyártás mögött. A cél ezeknél a start lebonyolítása, és úgyis mindenki készít magának olcsóbban gyártható verziót. Így viszont nincs nagy egyezkedés sem, leginkább megveszik az adott célra a lehető legjobb komponenst. Ez az oka annak, amiért olyan ritkák az RMA panaszok a referenciakártyákra.
Én is amikor kérek új hardvert a gyártóktól magamnak, akkor törekszem referenciát kérni. De persze ez nem mindig jön össze. A dolog abból a szempontból nem zavar, hogy a bolti árnál így is sokkal olcsóbban veszem a hardvert. Sokszor beszámítják a régi cuccom is, és akkor egy új VGA kijön 10-20 rongyból.
 Persze van ennek hátránya is. Nem válogathatok kedvemre, mert azok közül kell szerválni egy kiszemeltet, amik megmaradt mérnöki minták, de működnek.
Persze van ennek hátránya is. Nem válogathatok kedvemre, mert azok közül kell szerválni egy kiszemeltet, amik megmaradt mérnöki minták, de működnek. [ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#47390
üzenetére
Sokat. Az a memóriakonfiguráció 35 wattot eszik. Ebben a generációban a memóriák nagyon nagy fogyasztók lesznek. Vége a 20 wattba bőven belefér szintnek. Ezért is volt kritikus fejlesztési szempont jelentősen csökkenteni az RDNA2 fogyasztását az RDNA-hoz viszonyítva, mivel így korrigálni lehet a memória extrém fogyasztását.
(#47395) Devid_81: A termékmintának megvan a 3 GHz vízzel is. A probléma a fogyasztás. Ehhez a szinthez már 400 watt fölé kell menni. Nem feltétlenül éri meg. Az RDNA2 elsődlegesen a perf/wattban lép jelentősen előre, és ebből adódik, hogy sokkal nagyobb órajelre is képes, mint az RDNA. Meg persze ezen segít a CDNA busza is.
(#47400) Petykemano: Nem tudsz a korábbi adatokból kiindulni, mivel a memória PHY-t folyamatosan tervezik. Az RDNA2 esetében áttervezték, mert a Microsoft és a Sony is ilyen memóriaszabványt használ.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
paprobert
#47402
üzenetére
Kell egy minimum lapkaszám az adott memóriabuszhoz. 512 bithez például 16 darab lapka. 256 bithez 8. Ennyi kötelező. De például ha lenne elég nagy kapacitású memóriastack arra, hogy 256 biten 16 GB memóriát lehessen hozni 8 memóriával, akkor nyilván annak a fogyasztása nem lenne annyira magas, mintha a 16 GB-ot 16 memóriával hoznád 256 biten. De egyelőre nincsenek erre megfelelő memórialapkák, ugyanis a legfőbb fejlesztések a gyártóknál a HBM2-es és a DDR5-es megoldások. A GDDR6 egy másodvonalbeli technológia. Nem marad sokáig velünk, így annyira sok pénzt nem is raknak bele. A legmodernebb gyártástechnológiákat, mindig a fontos megoldások kapják meg, vagyis a HBM2 és a DDR5.
Sok dolgot lehetne csinálni, de ahhoz pénz és idő kell. Viszont pont ezt a kettőt nem szeretik áldozni a gyártók egy olyan irányra, ahol téglafalban ér véget az út. Erről nem fogod meggyőzni őket, mert tudják nagyon jól, hogy a sávszélességigényes területen a HBM-nek bitang nagy fórja van, tehát ha nem most, akkor a következő körben már arra ugrik mindenki. Így meg ugye minek a következő körre valami nagyot fejleszteni a legacy vonalra.
A legtöbb ötlet ilyen ott veszik el, hogy senki sem fizeti majd meg. Úgy meg felesleges.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#47417
Abu85
HÁZIGAZDA
Zartszelveny
#47414
Abu85
HÁZIGAZDA
válasz
 Zartszelveny
#47414
üzenetére
Zartszelveny
#47414
üzenetére
Nem abból fakad. A perf/watt az adott tranzisztorstruktúra végnapjain abból ered, hogy mennyire ismered ki az adott node-ot. Kell két vagy három kör mielőtt jól tudod majd használni. Az AMD-nek a prognosztizált 50%--os perf/watt ugrása ugyanazon a 7 nm-es node-on pusztán az a tapasztalat, amit a Vega 20 megjelenése óta gyűjtögetnek. Nagyjából mostanra sikerült úgy megérteni ezt a csíkszélességet, hogy hatékony lapkát tudnak rá tervezni.
Ugyanez lesz 5 nm-en is. Meg a GAAFET-ig bármin.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#47419
Abu85
HÁZIGAZDA
Zartszelveny
#47418
Abu85
HÁZIGAZDA
válasz
Zartszelveny
#47418
üzenetére
A CDNA támogatni fog egy csomó olyan adatformátumot, ami az RDNA nem. Emellett máshogy épül majd fel a cache-szervezése is. Leginkább az AI miatt lett szétválasztva, mert a jó AI teljesítmény grafikai szempontból eléggé hasztalan.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Ez nem arról szól, hanem az a baj, hogy előbb a hardvernek kell ott lennie, és csak utána jönnek rá a szoftverek. Ha továbbra is jönnek RT nélküli szériák, akkor azzal a gyártók az RT terjedését gátolják, vagyis továbbra is egy csomó tranzisztort költenek el feleslegesen a lapkákba. Meg lehet azt játszani a nulladik vagy első generációnál, hogy a lapkák egy részében kihagyod, de a tényleges terjedést azt segíti elő, ha mindenhol ott van. Emiatt az új szériánál még eléggé alap fícsőrnek kell majd lennie.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#47451
Abu85
HÁZIGAZDA
Petykemano
#47450
Abu85
HÁZIGAZDA
válasz
Petykemano
#47450
üzenetére
De amiatt van. Ha az AMD is engedné 300 wattig a Ryzen 3950X-et, akkor be tudnának állítani 5 GHz fölötti órajelet, de nem látják értelmét, mert többet ártana az egész sorozat reputációjának, ha kazánt csinálnának belőle. Megelégszenek a 170 wattos maximummal. Ha megnézed a DIY eladásokat, akkor láthatod, hogy melyik opció éri meg jobban.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
-
Abu85
HÁZIGAZDA
válasz
 gejala
#47467
üzenetére
gejala
#47467
üzenetére
Ne keverjük ezeket össze. A mai GPU-k úgynevezett veszteségmentes színtömörítési algoritmusokat kínálnak. Ezek az AMD és az NVIDIA rendszereiben is 2:1, 4:1 és 8:1 arányú, veszteségmentes tömörítést kínálnak, amelyek ugyan hasznosak, de nem oldanak meg olyan kritikus menedzselési problémákat, mint a töredezettség. Tehát fel lehet ezekre építeni egy marketinget, és van is valós hasznuk ezeknek az eljárásoknak, de a működésük pontosan ugyanaz.
Az allokálás problémáját egyik ilyen veszteségmentes színtömörítési algoritmus sem kezeli, márpedig a VRAM használatának hatásfoka ettől függ, nem attól, hogy pár kilobájtot nyersz a puffer/image adatokon.
Az alternatív megoldásokkal két probléma lesz. A pletykákban szereplő Tensor magos módszer csak veszteségesen tud működni, vagyis minőségvesztés árán vállalod be, hogy többet nyersz a puffer/image adatok tárolásán. De ez minőségvesztés mellett sem oldja meg a töredezettség problémáját, amitől rossz hatásfokú a VRAM használat, illetve a kitömörítés időbe kerül. Egy image adat betöltése egy mai GPU számára nagyjából 50-70 ns körül van. Arra vannak tervezve a hardverekhez szabott optimalizálások, hogy a wave-ek futtatása szempontjából ezt az 50-70 ns-ot áthidalják konkurens wave-ekkel. Tehát egy shader mondjuk allokál valamennyi erőforrást a multiprocesszoron, ami megenged mondjuk 16 wave-et futtatni. Ebből egy belefut egy memóriaelérésbe, jön a következő wave, és kialakul a működésben egy olyan egyensúly, hogy a wave-ek egy része adatra vár, míg a másik része addig dolgozik. Ez a működés a normál memóriaelérésre van szabva, és ezért van megadva minden architektúránál egy minimum wave szám, amit el kell érni a hatékony működéshez. Ha azonban még át is kell méretezni az image adatot a betöltés után, akkor az az 50-70 ns megnő az átméretezés időigényével, ami jó esetben is minimum 100 ns lesz. Így már jóval nagyobb késleltetést kell áthidalni a konkurens wave-eknek, miközben elképzelhető, hogy nem is futtatható annyi wave a multiprocesszoron belül, ami ezt meg tudná tenni. Sőt, a statikus erőforrás-allokálás miatt igen ritka, hogy egy adott shader képes annyi wave-et futtatni, amennyit az architektúra elméletben megenged.
Ez tehát egy egyensúlyi kérdés, hogy megéri-e vállalni a konvertálás extra késleltetését, azzal ugyanis tényleg lehet nyerni a VRAM oldalán, de ennek az az ára, hogy a GPU közben malmozni fog, amíg adatra vár.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Nyugodtan leírhatod, hogy nem probléma, ha a memóriaelérés késleltetése kétszeresére nő. Van egy szint, amit a GPU-k át tudnak hidalni, hiszen erre vannak tervezve, de olyan mennyiségű wave-et nem fogsz tudni futtatni, hogy magas késleltetést áthidalj. És onnantól csak teljesítményt vesztesz, mert nincs adat, amivel a GPU dolgozhatna.
Offline render szintjén egy ilyen megoldás hasznos lehet, mert ott alapvetően mindegy, hogy 20 helyett 30 perc alatt végez a rendereléssel a GPU, de nem mindegy, hogy mennyi modellt tudsz belerakni a VRAM-ba. Real-time szinten viszont nem éri meg felvállalni azt, hogy a GPU sokszor malmozzon. Arról nem is beszélve, hogy az AI scaling mindig veszteséges technika. Ha minőség kell, akkor nem érdemes alkalmazni.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#47510
Abu85
HÁZIGAZDA
Petykemano
#47509
Abu85
HÁZIGAZDA
válasz
Petykemano
#47509
üzenetére
A DLSS nem működik általánosan. Az ilyen AI upscaling nehezen megvalósítható ilyen formában, de a Microsoft dolgozik egy általános megoldáson. A Facebook már prezentált is egyet.
Az AI upscalinggel az a baj, hogy technikailag csinálhatod általánosan, de sokszor nem ad jó eredményt. Emiatt nem alkalmazzák így.A RIS az általánosan működik, az jóval egyszerűbb post-process technika. Annak nincsenek extrém követelményei a működéshez.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#47515
Abu85
HÁZIGAZDA
Petykemano
#47513
Abu85
HÁZIGAZDA
válasz
Petykemano
#47513
üzenetére
Vagy építesz rá saját szervert, vagy bérelsz gépidőt valahol. Attól függ, hogy melyik a jobb opció.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#47517
Abu85
HÁZIGAZDA
Petykemano
#47516
Abu85
HÁZIGAZDA
válasz
Petykemano
#47516
üzenetére
Attól függ, hogy a neuronháló általános, vagy specifikus. Ha általános, akkor elég ha elkéred, és futtatod. A hátránya ennek az, hogy nagyon sok játékbeli tartalmat nem fog felismerni.
A játékspecifikus neuronháló a legjobb, amikor direkt a játékodra szabod. Ide gépidő kell, és csinálsz magadnak egy saját modellt.Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Eleve az, hogy háromról írnak fura. Én négyről tudok. De az lehet, hogy a vizes nem startol el idén. Eléggé sok a tartalék a fogyasztás oldalán, szóval azt megküldhetik rendesen, hogy majd a 3090 ne érezze jól magát. Technikailag úgy van tervezve a Navi 21, hogy ne menjen 250 watt fölé, de látva, hogy az NV sem szívbajos a 300+ wattokkal, az AMD is nekiugorhat ennek. Elvileg neki is ugranak. Emiatt lesz sok modell. Eredetileg csak kettőt terveztek.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 Devid_81
#47527
üzenetére
Devid_81
#47527
üzenetére
A GA102 nagyjából 630 mm2. Még nagyobb nem fér bele. Ez is ~100 mm2-rel nagyobb a komfortzónánál. De kb. még elmegy, csak vastagon fogó ceruzával kell árazni.
(#47529) Jack@l: A régi VGA-kat az új generáció szarrá fogja alázni sebességben. Az Ampere és az RDNA2 is.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
 nubreed
#47539
üzenetére
nubreed
#47539
üzenetére
Lesz némi árkorrekció. De nagyon szabadon ők sem mozoghatnak. Viszont sajnos valahol meg kell fizettetni a drágább gyártástechnológiákon a relatíve nagy lapkákat.
(#47541) Jack@l: Valószínű, hogy fél éves távlatban az új generációk ismét kapnak olyan meghajtót, ami a startkor mért sebességre rápakol, hiszen ez az elmúlt generációkban is megvolt, de alapból annyira gyorsak az új hardverek, hogy a mostani generáció nem jelent nekik problémát. Raytracingben például teljesen más szintet képviselnek.
Érdemes megnézni a konzolon az új Spidermant. Abba nemrég rakták bele a raytracing reflectiont. Mindössze 6%-os teljesítményvesztést okozott, pedig ez a legvadabb RT effekt, ami a Turingokon PC-n -40-60%-ot is csinál. Persze az összehasonlítás nem fair, mert a PS5-nek a raytracing pipeline-ja sokkal modernebb, meg PC-n ez a pipeline szabványosan nem is lesz elérhető, de az effekt ugyanaz, a Sony megtalálta az utat ahhoz, hogy szoftveresen ennyire felgyorsítsa. A pipeline egy részét egyébként áthozza PC-re az AMD, vagyis jó esély van rá, hogy a szabványosítás gyors lesz. Elég lesz csak beadni a Microsoftnak, és onnantól kezdve meg kell egyezni a gyártóknak abban, hogy a BVH gyorsítóstruktúra specifikációja mikortól lesz egységes. Ezt három év alatt meg lehet csinálni. Onnantól kezdve jön a kurva gyors raytracing PC-n is.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
A memóriahasználat az allokáció hatékonyságától függ. Minél hatékonyabb, annál jobban kitölti a rendelkezésre álló VRAM-ot. Ez alapvetően feature, de sok függ magától a driverből, mert DirectX 11 API-ban a driver kontrollálja ezt, míg DirectX 12-ben az alkalmazás. Viszont a probléma mindkét API esetében ugyanaz: a streaming motorok esetében az a jó, ha a lehető legtöbb memóriát felhasználja a rendszer, ugyanis ilyenkor később kell majd allokációt törölni. A DirectX 11 alatt nem tudni, hogy milyen szegmentálást alkalmaznak a gyártók, mert ott ugye a meghajtó mögött el van rejtve a memória, így nem látszik a fejlesztőeszközök felé gyakorlatilag semmi. De a hardver számára van egy ideális szegmentálás, és valószínűsíthető, hogy a DirectX 11-ben a memória felosztása hasonló ahhoz, ahogy DirectX 12-re felosztják, utóbbi API viszont közvetlen memóriamenedzsmentet enged, tehát látszik a szegmentálás.
Az NVIDIA így szegmentál: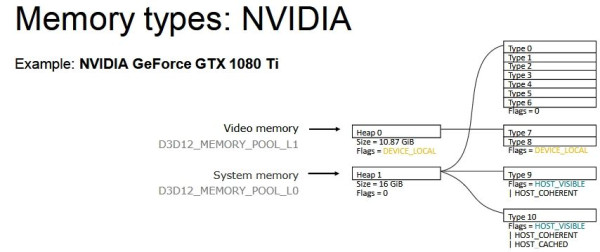
Míg az AMD így: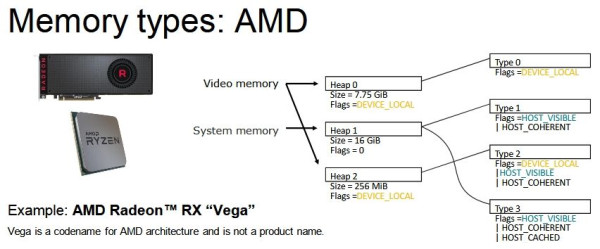
A különbség ebből ered, hogy az NVIDIA nagyon sok felé osztja a memóriahalmazokat, és mindegyik memóriahalmazon belüli type szegmenst külön kell kezelni, vagyis az allokációkat is erre a leosztásra kell tervezni. A VRAM-ot tekintve az a lényeg, hogy az NVIDIA a teljes VRAM-ot eszközlokálisan használja, viszont nem egy, hanem két eszközlokális type szegmens alatt, vagyis elképzelhető, hogy hiába van még az adott VRAM-on belül akár 1 GB-nyi szabad memória, a töredezettség akkora lehet két szegmens szintjén, hogy az új allokációk egy részének már nem található akkora összefüggő terület, ahova beférnének, így allokációkat kell törölni.
Az AMD 256 MB-ot minden rendszer VRAM-ják host felé látható és koherens memóriának használ, ahova főleg puffereket dobnak be, ezek nem igazán változnak. Ennek a lényege, hogy ezeket a puffereket a GPU többször címezi, mint a CPU, így jobb ha a GPU-hoz vannak közel. Az NVIDIA-nak is van ilyenje, de a rendszermemóriában, így náluk nem a CPU megy a VRAM-ig, hanem a GPU a rendszermemóriáig az adatokért. A maradék terület az eszközlokális halmaz, és csak egy type szegmens van rá alkalmazva, vagyis nincs logikailag két részre vágva. Ezzel nagyobb esély van rá, hogy ha van benne amúgy 1 GB-nyi szabad terület, akkor a nagyobb allokációk még beleférnek, így nem kell törölni más allokációkat.
A töredezettség miatt nagyon ezzel nem lehet mit kezdeni, olyan ez, mint a HDD-n az adatok töredezettsége. Tehát hiába streaming a motor, akkor sem lesz annyira hatékony a hardverek memóriahasználata, hogy igazán jól megközelítse a rendelkezésre álló területet. Azaz jó legyen a kihasználás. A legjobb kihasználáshoz lapalapú modell kell, mert ott minden allokáció gyakorlatilag egy 4 kB-os lap lesz, és nincs töredezettség. Úgy már ki lehet használni a rendelkezésre álló memóriát, vagyis egy program egy például 7,75 GB-os eszközlokális type szegmensen tényleg 7,75 GB-ot fog felhasználni nem csak 6-6,5-öt, stb. A next gen konzolokban ez a modell lesz, és majd csak beesik a PC-re is egy szabványos API, ami kezeli a lehetőséget.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
#32839680
#47549
üzenetére
Nem kell, mert lapokat mozgatsz. A képszámításnak az a szépsége, hogy az adatok nagy része változatlan marad, így egy jelenet változása mindössze pár megabájtnyi terhelést jelent a lapszitnen. De ha teljes allokációkat mozgatsz, akkor persze, hogy fáj, hiszen 4 kB-nyi adatért akár 100 MB-ot is másolni kell. Az új konzolokban pont az a lényeg, hogy csak 4 kB-ot másolsz.
PC-n az egyetlen API, ami így működik az az SSG API. Nincs semmi más, még csak hasonló sem. Sokáig valószínűleg nem is lesz.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
#32839680
#47551
üzenetére
Nem. Ahhoz egy külön I/O API kell, amit aztán lehet használni a grafikus API-k alól.
Annyira nem. A konzolnál ez egy killer fícsőr, de a tárkapacitás megöli. Tehát ott is számolni kell azzal, hogy ha elmennek ilyen irányba, akkor csúnyán lesz ám 300-400 GB egy játék. Szóval valószínű, hogy csak részben fogják bevetni. Azt pedig PC-n simán hozni fogod több memóriával. Amint bedobsz a PC-be mondjuk 64-128 GB-ot, máris kezeled erőből a problémát, és ennél tovább a tárkapacitás miatt a konzolok sem mennek majd.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#47555
Abu85
HÁZIGAZDA
Petykemano
#47554
Abu85
HÁZIGAZDA
válasz
Petykemano
#47554
üzenetére
Ebből nem tudunk kiindulni, mert az Xbox Series X nem alkalmaz feszültségskálázást. Fix módok között ugrál, tehát a nagy teljesítményű módhoz olyan feszültséget fog beállítani, ami kibírja a terhelésszimulációra írt tesztprogramot. A PS5-ről kellene megtudni ezt az adatot, mert az viszont feszültségskálázást használ.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.






















Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.
- Külpolitika
- OnePlus Nord 3 - kapcsoljuk északot
- A fociról könnyedén, egy baráti társaságban
- iPhone topik
- Bambu Lab X1/X1C, P1P-P1S és A1 mini tulajok
- ASUS Vivobook Snapdragonnal: talán egy új korszak kezdete!
- BestBuy topik
- Hardcore café
- Filmvilág
- Kávé kezdőknek - amatőr koffeinisták anonim klubja
- További aktív témák...
