Új hozzászólás Aktív témák
-
#7
 ukornel
aktív tag
Petykemano
#3
ukornel
aktív tag
Petykemano
#3
ukornel
aktív tag
válasz
 Petykemano
#3
üzenetére
Petykemano
#3
üzenetére
Gondolom, mert így kisebb interposert kell gyártani. Ez javíthatja a költségeket és a kihozatalt.
-
ukornel
aktív tag
"Az való igaz, hogy az utasítás-előbetöltés nagy dobás volt, de a GCN4-ben kb sz@rt sem ért, kell hozzá a Vega felépítése. Valószínűleg a GCN4-be csak azért került be, mert tesztelni akarták a működését és hogy megismerjék a fő limitációkat... az sem véletlen, hogy lecserélték a CU-kat, ott futhattak bele az első komoly limitációba."
+1
Nekem is van egy ilyen érzésem, hogy a Polaris egy korai fejlesztés volt az új gyártástechnológia és az utasítás-előbetöltés kiismerésére, tesztelésére. Nem véletlen, hogy csak az alsó-közép szegmensbe terveztek vele.b. #82
"szerintem ezekkel a ramokkal nehezen lesz olcsóbb , mint az 1070 ,(135 K) ha azt a szintet is hozza teljesítményben."A magam részéről nem hinném, hogy olcsóbb lesz, mint a 1070. Csalódást keltőnek találnám, ha az AMD azért gyártott volna le egy >500mm2-es csipet, ami az egybehangzó pletykák szerint 4096 számolóval 12 TFLOPSt hoz, hogy aztán ne érje utol a 1080-at. Látszik, hogy egy sor reformmal próbálják azokon a területeken behozni a lemaradást, ahol az Nvidia megoldása jobb. Én azt várom, hogy a 1080 és a Titan X közé kerüljön, és 1080 áron adják.
[ Szerkesztve ]
-
ukornel
aktív tag
Jesszusom. Ezt is megértük: AMD-s fórumban AMD-s szövegtől kapok hányingert.
Más ennek a harmadáért kap pár nap pihit.namaste #195
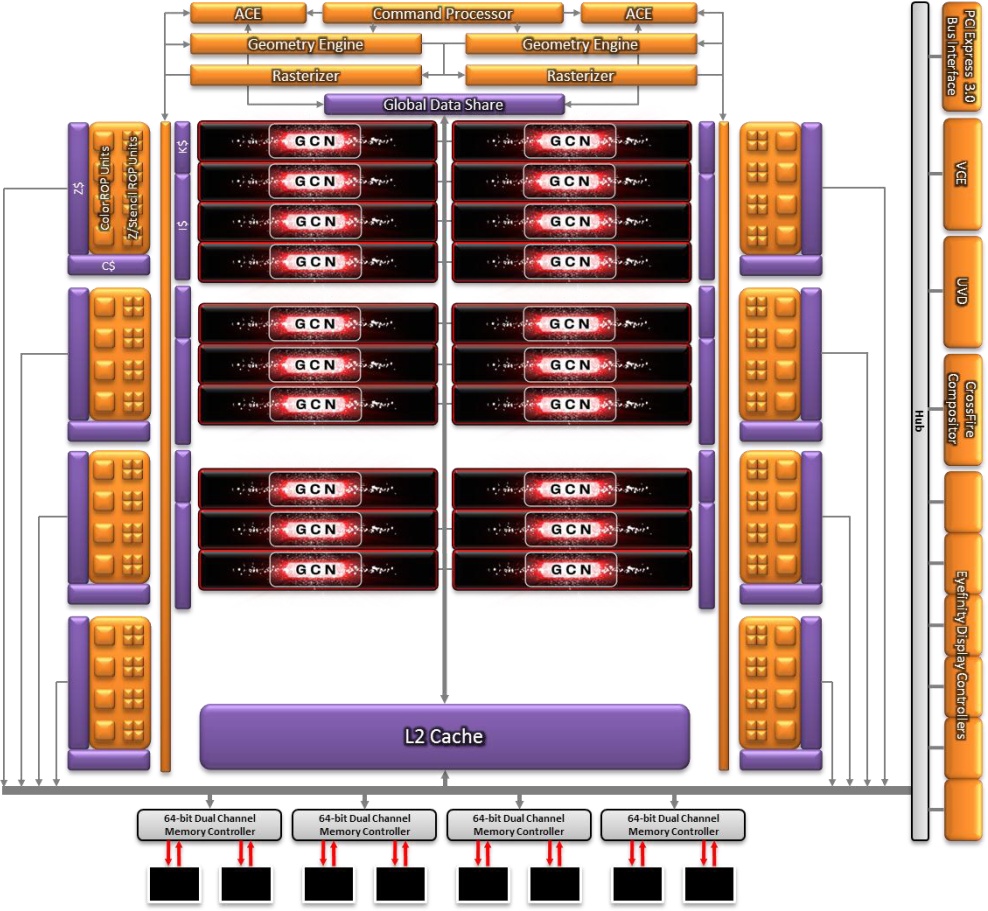
"AMD-nél nincsenek a ROP-ok a L2 partíció/MC-khez rendelve, hanem a Shader Engine-hez; az NV-nél fordítva, a ROP-ok az L2/MC mellett vannak és nem a GPC-kben."
Bocs, én ehhez hülye vagyok mint tyúk az ábécéhez, de anno az első GCN leírásában (lásd ITT) is az volt, hogy az L2 a memóriacsatornáknak megfelelően van fölszeletelve, és ide kapcsolódnak a ROP-ok. Ez összhangban áll azzal, ami a GCN Architecture Whitepaper 15. oldalán látható. Ez a kép nem pont ugyan az, de a lényege megegyezik: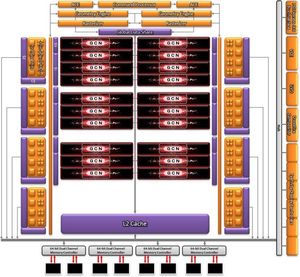
-
ukornel
aktív tag
Érdekesnek találom, hogy a Vega architektúra leírásában sok fejlesztés a jobb skálázódást célozza; a memóriarendszert a "világ legjobban skálázódó memóriaarchitektúrájának" nevezik.
Na, ezt most vessük a Polaris előtt kiadot roadmappel:
A Vegánál csak annyi áll, hogy "HBM2", plusz némi perf/watt fejlődés. A következő, "Navi" architektúra újdonságának írták, hogy "Scalability".
Mennyire kell ezeket a jelszavakat komolyan venni?
Persze, a skálázhatóság javítására itt és most nagy szükség van, hiszen a Fiji teljesítménye nem skálázódott igazán jól a plusz számolókkal.A Navi-nál még ez áll: "Nextgen Memory". Ez vajon mi fán terem? A HBM2 sávszélessége valószínűleg még 1-2 év múlva is élvonalbeli lesz, miért kell leváltani? Vagy a drága és macerás interposer helyett hoznak be valami rugalmasabb és olcsóbb megoldást, mint az Intel-féle EMIB?
(Lehet, hogy ez inkább a nagy Radeon találgatós topikba kellene...)Ide kapcsolódik:
Fiery #5
"512 GB/s memoria savszelesseg? Nem ugyanennyi volt masfel eve mar a Fiji is? Biztos, hogy ez eleg lesz 2017-2018-ban is? Vagy a Fiji jart tulsagosan a kora elott?"
Biztos, hogy ez eleg lesz 2017-2018-ban is? Vagy a Fiji jart tulsagosan a kora elott?"Az újabb VGA-k egységnyi számítási teljesítményre vetített sávszélessége (egy lebegőpontos műveletre hány bit memóriaelérés jut): az Nvidia 10-es sorozatánál 0,28-0,35 bit/FLOP között alakul; az RX400-as Radeonoknál 0,35-0,4 bit/FLOP között, míg az R9 390/X, Fury*.* 0,5 bit/FLOP körül szór.
Ez alapján azt mondanám, hogy -a szavaiddal élve- a Fiji járt a kora előtt.
Ugyanakkor, ha figyelembe vesszük, hogy a hírek szerint Fury sávszél-gondokkal küszködött, ez arra világít rá, hogy az Nvidia hatékonyabban használja ki a rendelkezésre álló sávszélt, előrébb jár a színtömörítési stb módszerekben, és így kisebb, 0,3-0,35 bit/FLOP között megoldotta azt a feladatot, amihez a Fijinek 0,5 bit/FLOP is éppen csak elég. Úgy is mondhatnánk, hogy az AMD ezt a hatékonysági lemaradást brute force elven, a vadiúj HBM technológiával próbálta megoldani.
Remélem, a Vegában a mozaikos optimalizálás és a javított színtömörítés visszafogja a sávszél pazarlást és egy szintre hozza a hatékonyságot az aktuális zöld kártyákéval. Ha így lesz, akkor a pletykák alapján számolt ~0,34 bit/FLOP egyáltalán nem lesz kevés a Vega10-nek. -
ukornel
aktív tag
Aha, dereng valami erről - újabb iteráció, nagyobb sebesség, nagyobb sűrűség, hurrá.
DE! A nagy kérdés, hogy az interposer kihozatalával és gyártási költségével sikerül-e valami áttörésfélét elérni?
Mert ha nem, akkor vagy valami EMIB-hez hasonlót kellene fejleszteni, vagy valami radikálisan újat kitalálni.KisDre #218
"A Scalability meg gondolom hogy ne legyen Polaris és Vega szerűen két architektúra egyszerre, hanem mint a Zen-t is eggyel akarják lefedni az egész palettát"Aha, lehet, hogy erről van szó. Bár én ezt a "Polaris-alsó / Vega-felső szegmens" felosztást nem érzem annyira tervszerűnek; a Polarisra inkább egy átmeneti, kísérleti sorozatként tekintek - a kísérletezésnek meg ugye nem a nagyvaddal kezdünk neki.
Szeretnék arra gondolni, hogy a "skálázhatóság" alatt már a 16384 számolóig azok darabszámával lineárisan növekvő teljesítményű architektúrát értik![;]](//cdn.rios.hu/dl/s/v1.gif)
-
ukornel
aktív tag
"Minden vonatkozó ábra és szöveges leírás arra utal, hogy a ROP-oknak van saját szín és mélység/stencil cache-ük"
Ez egyértelmű, szerintem senki nem is mondott mást.
"Miért nem vezet közvetlen nyíl a ROP blokkoktól az L2-be egyik ábrán se?"
Nem azért a húsz fillérért mondom, de az ábrán a memóriavezérlőkbe se közvetlen nyíl vezet...
-
ukornel
aktív tag
"Nem azért írtam, mert valaki ezzel ellentéteset állított volna, hanem mert ez van a doksiban."
Ez szép és jó, hogy benne van a doksiban. Úgy érzem, nem árt tisztázni, ki mit állított, mikor én kéretlenül és hozzáértés nélkül beleugattam.
Abu85: "Eddig a ROP blokkokhoz tartoztak a L2 gyorsítótár partíciói"
namaste:
"A GCN-nél a ROP és a hozzátartozó color/depth cache a memóriavezérlőhöz kapcsolódik, semmi köze az L2-höz."Lehet, hogy Abu nem fogalmazott pontosan, de az biztos, hogy a ROP (és "tartozékai") nem közvetlenül csatlakoznak a memóriavezérlőhöz. A témában nézd meg az Anandtech leírását a GCN megjelenésekor:
"As it turns out, there’s a very good reason that AMD went this route. ROP operations are extremely bandwidth intensive, so much so that even when pairing up ROPs with memory controllers, the ROPs are often still starved of memory bandwidth. With Cayman AMD was not able to reach their peak theoretical ROP throughput even in synthetic tests, never mind in real-world usage. With Tahiti [...] The solution to that was rather counter-intuitive: decouple the ROPs from the memory controllers. By servicing the ROPs through a crossbar AMD can hold the number of ROPs constant at 32 while increasing the width of the memory bus by 50%."
Igaz, Anandék crossbart írtak, Abu meg ring bust mondott, ami nem ugyanaz - talán valami bonyolultabb hibrid összeköttetés van, amire Abu forrása gyűrűs buszként hivatkozott, az Anandteché meg crossbarként. A lényeg most nem is ez, hanem, hogy már az első GCN-ben sem közvetlenül a MC-hez kapcsolódtak a ROP-ok.
A Vegánál ezt írják:
"AMD has significantly reworked how the ROPs (or as they like to call them, the Render Back-Ends) interact with their L2 cache. Starting with Vega, the ROPs are now clients of the L2 cache rather than the memory controller, allowing them to better and more directly use the relatively spacious L2 cache."Szerintem ez összhangban van azzal, amit Abu mond, de azzal is, amit te a #167-esben írtál. De lehet, hogy csak rosszul látok.
"Az ábrák se pontosak, össze-vissza vannak, pl. egyiken az L2 egy darabból áll, a másikon darabokban a memóriavezérlők mellett. De ez nem baj, mert különböző aspektusokat ábrázolnak és a szövegből ki lehet hámozni a lényeget."
OK, az ábrák nem pontosak, de őszintén szólva a Whitepaperen se könnyű elmenni."Az azt akarja szimbolizálni, hogy a ROP-ok bármely memória partícióba írhatnak egy crossbaron keresztül. És ahhoz a csíkhoz kapcsolódnak az egyéb részek egy hubon keresztül, azok se az L2-be dolgoznak, hanem a memóriába."
Ja, de van egy global data share is az L2-vel
Ezen a ponton egyre inkább úgy látom, hogy túl kevés a pontos, konkrét információ a hivatalos leírásban. Számomra mindenképp. Vagy egyszerűen a felkészültségem nincs meg az értelmezésükhöz. Asszem, kár volt belekotyognom, elnézést.

[ Szerkesztve ]




 Biztos, hogy ez eleg lesz 2017-2018-ban is? Vagy a Fiji jart tulsagosan a kora elott?"
Biztos, hogy ez eleg lesz 2017-2018-ban is? Vagy a Fiji jart tulsagosan a kora elott?"
![;]](http://cdn.rios.hu/dl/s/v1.gif)



Új hozzászólás Aktív témák

ph Az új Radeonok alapja az általános előrelépés mellett évek óta létező problémákra is reflektál.
- OTP Bank topic
- Napelem
- Formula-1
- Kicsit extrémre sikerült a Hyte belépője a készre szerelt vízhűtések világába
- Fotók, videók mobillal
- Milyen okostelefont vegyek?
- Motorola Edge 50 Pro - több Moto-erő kéne bele
- Foxpost
- Modern monitorokra köthető 3dfx Voodoo kártya a fészerből
- Star Trek Online -=MMORPG=-
- További aktív témák...

- ELADÓ 32 DB Nvidia RTX 3060 Ti és 8 DB Zotac Gaming Geforce RTX 3080 Trinity / KOMPLETT BÁNYAGÉP
- Rog 4070 Ti //KERESEM!!//
- EVGA GeForce GTX 1080 Ti FTW3 GAMING 11GB GDDR5X 352bit (11G-P4-6696-KR) Videokártya
- BESZÁMÍTÁS! SAPPHIRE RX 460 2GB GDDR5 videokártya garanciával hibátlan működéssel
- BESZÁMÍTÁS! Gigabyte AORUS MASTER RX 6800XT 16GB GDDR6 videokártya garanciával hibátlan működéssel