Új hozzászólás Aktív témák
-

sonar
addikt
Csak egy kis megjegyzés:
Múltkor olvastam egy könyvet v cikket a web parsolás témában,már nem emlékszem pontosan, de ott azt ajánlotta a szerző, hogy ha a file encoded akkor célszerű a bináris file-ba írást használni.
Az okfejtésre már nem emlékszem tisztán, de talán az volt, hogy gyorsabb és hatékonyabb és a későbbi feldolgozások (esetlegesen további decode-ok) zökkenőmentesebbek lesznek.A tudást mástól kapjuk, a siker a mi tehetségünk - Remember: Your life – Your choices!
-

kovisoft
őstag
-
kovisoft
őstag
-
-
-
-

Hege1234
addikt
köszi a segtségeket
így addig viszi el a folyamatokat, hogy
elkészül a fájl benne az a_dictionary a fájlban{"list1":{"cim":"Családi videó....","Minőség":"SD","Képarány":"4:3","Időtartam":"01:26:24","Készült":"1993"}}viszont újabbat pl. ha a list1- et átrom
list2-re akkor már nem tudja beleírni vagyis acontents.update(a_dictionary)
gondolom ilyenkor így már nem fut le -
kovisoft
őstag
válasz
 Hege1234
#3563
üzenetére
Hege1234
#3563
üzenetére
Csináltam egy próbát az update()-tel és "list1"-et és "list2"-t tartalmazó dict-ekkel. Ez lett az eredmény, az update() után bekerült a dict-be mindkettő (a sortörést én adtam hozzá, hogy olvashatóbb legyen):
> d1 = {"list1":{"cim":"Családi videó....","Minőség":"SD","Képarány":"4:3","Időtartam":"01:26:24","Készült":"1993"}}
> d2 = {"list2":{"cim":"Családi videó....","Minőség":"SD","Képarány":"4:3","Időtartam":"01:26:24","Készült":"1993"}}
> print(d1)
{'list1': {'cim': 'Családi videó....', 'Minőség': 'SD', 'Képarány': '4:3', 'Időtartam': '01:26:24', 'Készült': '1993'}}
> d1.update(d2)
> print(d1)
{'list1': {'cim': 'Családi videó....', 'Minőség': 'SD', 'Képarány': '4:3', 'Időtartam': '01:26:24', 'Készült': '1993'},
'list2': {'cim': 'Családi videó....', 'Minőség': 'SD', 'Képarány': '4:3', 'Időtartam': '01:26:24', 'Készült': '1993'}} -
Hege1234
addikt
huhh... végül csak összejött
nagyon köszi a segítséget, útbaigazítást!
#3564
fájllal nálad se akart működni?végül így tudtam csak megoldani:
import json
json_file_path = 'sample_file.json'
a_dictionary = {"list4":{"cim":"Családi videó....","Minőség":"SD","Képarány":"4:3","Időtartam":"01:26:24","Készült":"1993"}}
try:
with open(json_file_path, "r+") as j:
contents = json.loads(j.read())
contents.update(a_dictionary)
j.seek(0)
json.dump(contents, j)
except FileNotFoundError:
with open(json_file_path, "a") as j:
json.dump(a_dictionary, j)ezzel így átírva a list számot szépen hozzá is tudja adni a következőt
mivel itt a list számoltatva van és hozzá van adva +1
ezt csak úgy tudtam megoldani, hogy egy base_dictionary-t is hozzáadtam amibe csak simán van a list1 a számozott helyettlist'+str(result)try:
count = open("sample_file.json").read()
except FileNotFoundError:
print('')
try:
words = re.findall(r"list", count)
except UnboundLocalError:
print('')
try:
result = len(str(words).split())
except UnboundLocalError:
print('')
try:
result += 1
except UnboundLocalError:
print('')
base_dictionary = {"list1":{"cim":str(title), "Minőség": str(quality_m), "Képarány": str(kepar), "Időtartam": str(idot), "Készült": str(yea_r)}}
try:
a_dictionary = {'list'+str(result)+'':{"cim":str(title), "Minőség": str(quality_m), "Képarány": str(kepar), "Időtartam": str(idot), "Készült": str(yea_r)}}
except UnboundLocalError:
print('')
json_file_path = "sample_file.json"
try:
with open(json_file_path, "r+") as j:
contents = json.loads(j.read())
contents.update(a_dictionary)
j.seek(0)
json.dump(contents, j)
except FileNotFoundError:
with open(json_file_path, "w") as j:
json.dump(base_dictionary, j) -
#3569
 bLaCkDoGoNe
veterán
bLaCkDoGoNe
veterán
bLaCkDoGoNe
veterán
Sziasztok, az alábbit szeretném Pythonban megcsinálni:
Van egy CSV fájlom, benne egy rakás szám, mondjuk 4 "oszlopban". Ezeket beolvasom egy pandas dataframe-be.
Szam1 Szam2 Szam3 Szam40 9 8 7 61 4 3 2 12 5 1 9 4...Van egy Python listám, ami tartalmaz 8 random számot.
[17, 42, 3, 84, 999, 5, 72, 36]Szeretnék végigmenni soronként a dataframe-en, és megnézni, hogy a lista elemeiből megtalálható-e egy vagy több az adott sorban, majd a végén egy dictionary-t szeretnék kapni, amiben gyakorisággal szerepelnek a lista elemei, valahogy így:
{17: 8, 42: 1, 84: 3, 999: 0, 5: 23, 72: 4, 36: 3}
Köszi előre is a segítséget."«Fuck does Cuno care?» The boy turns to you. (He doesn't care.)" [+] "The parasite makes nothing for itself. Its only tools are taxes and tithes meant to trick you into offering what it has not earned. In Rapture we keep what is ours." [+]
-
#3570
 sztanozs
veterán
bLaCkDoGoNe
#3569
sztanozs
veterán
bLaCkDoGoNe
#3569
sztanozs
veterán
válasz
 bLaCkDoGoNe
#3569
üzenetére
bLaCkDoGoNe
#3569
üzenetére
Van egy Python listám, ami tartalmaz 8 random számot
Ez legyen inkább egy dict:lista = [17, 42, 3, 84, 999, 5, 72, 36]dict_lista = {v:0 for v in lista}df = pandas.read_csv('test.csv')for row in df.iterrows():for v in row[1].values:if v in dict_lista: dict_lista[v] += 1print(dict_lista)JOGI NYILATKOZAT: A bejegyzéseim és hozzászólásaim a személyes véleményemet tükrözik; ezek nem tekinthetők a munkáltatóm hivatalos állásfoglalásának...
-
#3571
bLaCkDoGoNe
veterán
sztanozs
#3570
bLaCkDoGoNe
veterán
válasz
 sztanozs
#3570
üzenetére
sztanozs
#3570
üzenetére
Én elkezdtem baromira túlbonyolítani, és nem is működött.

A tiéd nagyon elegáns megoldás, sokat tanultam belőle, köszönöm szépen!"«Fuck does Cuno care?» The boy turns to you. (He doesn't care.)" [+] "The parasite makes nothing for itself. Its only tools are taxes and tithes meant to trick you into offering what it has not earned. In Rapture we keep what is ours." [+]
-
Hege1234
addikt
a split-et, hogyan lehet úgy használni, hogy az inputba lévő számok mindig egy új sorba kerüljenek?
1
4
9
..stbx = [int(x) for x in input("Enter multiple value: ").split(',')]
#1 4 9 132 322
print("Number of list is: ", x)
#1,4,9,132,322.split('\n')-el próbálkoztam, de ezt a hibát írja kiValueError: invalid literal for int() with base 10: '1 4 9 132 322'
-

axioma
veterán
válasz
Hege1234
#3572
üzenetére
sztem te ezt keresed, mar ha jol ertem h kiiratni akarod for ciklus nelkul kulon sorokba (a split.("\n") arra valo h a sorvegeknel szetvagja az eredetit, az meg nalad 1 db-os lista):
print("\n".join(map(str,list)))
Masreszt ha nem kell kozben int-kent (ellenorzesnek sem!), akkorprint("\n".join(input('...').split()))Hm, lehet hogy tobb sorban megadott inputot szeretnel? Akkor viszont hogy kulonboztetne meg a felhasznalo hogy vege a bevitelnek v csak uj adatot ad be? A sorvegen tul 1 db input nem tud latni, mashogy osszerakott v pl file-bol olvasott szoveget tudsz tobbsorost kapni, interaktivan ebben a formaban nem.
[ Szerkesztve ]
-
Hege1234
addikt
köszi, kipróbálom majd
valahogy úgy tudnám leírni, hogyan használnám, hogy eddig
szövegszerkesztőből másoltam ki az egymás alatt lévő számokat
ezeket kijelöltem és beillesztettem az inputba
így automata minden új sorba került
(ahogy végzett egy számmal beadta a következőt)
szóval azt szeretném elérni, hogy ne kelljen már a szövegszerkesztőbe egymás alá tenni a számokat -
Hege1234
addikt
ki van printelve, hogy mit tud csinálni a számokkal
minden egyes szám mást csinálígy tudna a user lekérni egyszerre több mindent nem csak egy számnak a tartalmát
átnézi és egy sorba beírja mi kell neki
pl ezt írja az inputba
1 3 7 15gondolom akkor ezt kellene szeparálni, hogy a számok közötti szünet kapjon egy új sort '\n' ?
-
axioma
veterán
válasz
Hege1234
#3577
üzenetére
Akkor azt nem ertem, miert nem jo az eredeti...
Ha szokozzel akarod akkor sima split() a ',' nelkul [barmely whitespace-nel szetvagja]
Ha enterekkel akarod bekerni akkor macerasabb, ki kell elore jelolni h mi a bemenet vege [pl. ures sor], es akkor mar irsz egy normal while ciklust.
De a szokoz, parameter nelkuli split sztem a legjobb megoldas itt. Usernek kiirod hogy ugy kered, annyi...[ Szerkesztve ]
-
Hege1234
addikt
így gép előtt már látom mi a probléma
mivel egy dict-ből olvastatom ki az infót a megadott számok alapján
keyerror-t ad visszaKeyError: 'list1\n3'
amikor az van beleírva, hogy 1 3p:\split>read_l.py
1 - video 1#23
2 - video 2#23
3 - video 3#23
4 - video 4#23
írd ide a számot: 1 3
1
3
Traceback (most recent call last):
File "P:\split\read_l.py", line 18, in <module>
cim = title['list'+str(nums)]['cim']
KeyError: 'list1\n3'kiszedtem egy példát amin talán jobban átláthatóbb
title = {"list1":{"cim":"video 1#23"},"list2":{"cim":"video 2#23"},"list3":{"cim":"video 3#23"},"list4":{"cim":"video 4#23"}}
index = 1
for thevalue in title.values():
print(f"{index:5}"+' - '+thevalue['cim'])
index += 1
nums = input('\nírd ide a számokat: ').split()
nums = '\n'.join(nums)
print(nums)
cim = title['list'+str(nums)]['cim']
print('\n'+cim+'\n')ez van loop-ba téve, ha be van írva egy szám kiadja a címet
és bejön újra az inputszövegszerkesztőből nem tudom miért működhet..
megjelenítettem a rejtett karaktereket akkor ezt adja ki1CRLF
3CRLF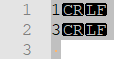
-
axioma
veterán
válasz
Hege1234
#3579
üzenetére
ehelyett:
nums = input('\nírd ide a számokat: ').split()
nums = '\n'.join(nums)
print(nums)
ezt rakd be:nums = input('\nírd ide a számokat: ').split()
print('\n'.join(nums))
de a nums-ot ne modositd (csak hasznald fel) a "fuggoleges" kiiratashoz - mar ha kell egyaltalan neked a kiiratas... mert a program magabol a nums-bol mukodik utana, az maradjon lista (igazabol csak egy iterator, de ez most neked mind1)Viszont ha ki akarod _minden_ kivalasztott cimet iratni akkor azt csak ciklussal tudod: ehelyett:
cim = title['list'+str(nums)]['cim']
print('\n'+cim+'\n')
legyen igy:for n in nums:
cim = title['list'+n]['cim']
print('\n'+cim+'\n')
Tanulsagkeppen: az n igy mar string, nem konvertaltad szamma, nem kell me'g egyszer str.
Masreszt ezt az egeszet egyben ennyivel el lehet intezni ugy, hogy me'g hibakezeles is legyen:for n in input('\nírd ide a számokat: ').split():
listanev='list'+n
try:
print('\n'+title[listanev]['cim']+'\n')
# egyeb dolgok amit csinalni akarsz a valasztott elemmel
except KeyError:
print('\n Nem letezik a valasztott '+listanev+' elem!')
ha jol ertem azt, hogy a szamokat "fuggolegesen" csak teszt celjabol akarod kiirni...[ Szerkesztve ]
-
axioma
veterán
válasz
Hege1234
#3579
üzenetére
Me'g egy aprosag, megkonnyiteni a dolgod: ehelyett:
index = 1
for thevalue in title.values():
print(f"{index:5}"+' - '+thevalue['cim'])
index += 1
ekvivalens az hogyfor index,thevalue in enumerate(title.values()):
print(f"{index+1:5}"+' - '+thevalue['cim'])[ Szerkesztve ]
-
Hege1234
addikt
köszi ezek így nagyon praktikusak
és már tudtam is máshova alkalmazni
átírtam minden tanácsot
aminek a révén rájöttem, hogy rosszul vezettem lemivel loopolva van, így úgy kell az
inputot értelmezni, hogy a számokat amik be vannak írva pl az 1 3 9
azokat így kellene elvileg megkapnianums = input('\nírd ide a számokat: ').split()
#1 3 9
végigmegy a list1-esen
nums = input('\nírd ide a számokat: ').split()
#3
végigmegy a list3-ason
nums = input('\nírd ide a számokat: ').split()
#9
végigmegy a list9-esen
nums = input('\nírd ide a számokat: ').split()
#és itt már újra várja a számot/számokat -
sztanozs
veterán
válasz
 RedHarlow
#3582
üzenetére
RedHarlow
#3582
üzenetére
nagyon nem tűnik összefüggőnek a két kódrészlet... Kicsit többet nem tudsz mutatni?
De kb így működik, feltételezve, hogy az
xml.dom.minidomcsomagot használod:file_handle = open("filename.xml","wb")
Your_Root_Node.writexml(file_handle)
file_handle.close()[ Szerkesztve ]
JOGI NYILATKOZAT: A bejegyzéseim és hozzászólásaim a személyes véleményemet tükrözik; ezek nem tekinthetők a munkáltatóm hivatalos állásfoglalásának...
-
sztanozs
veterán
válasz
Hege1234
#3586
üzenetére
pl így:
from datetime import timedelta
h, m, s = '00:10:00'.split(':')
delta = timedelta(hour=h, minute=m, second=s)
print(delta.totalseconds*1000)JOGI NYILATKOZAT: A bejegyzéseim és hozzászólásaim a személyes véleményemet tükrözik; ezek nem tekinthetők a munkáltatóm hivatalos állásfoglalásának...
-
Hege1234
addikt
válasz
sztanozs
#3587
üzenetére
nálam ezt hozza fel hibának:
delta = timedelta(hour=h, minute=m, second=s)
TypeError: 'hour' is an invalid keyword argument for __new__()lehet a python 3.9 miatt?
from datetime import timedelta
h, m, s = '00:10:00'.split(':')
delta = timedelta(hours=int(h), minutes=int(m), seconds=int(s))
print(delta.total_seconds*1000)TypeError: unsupported operand type(s) for *: 'builtin_function_or_method' and 'int'amit adott TypeError-t átírva, ezt írja hibának persze ez már lehet inkább amiatt mert rosszul használom..
-
sztanozs
veterán
válasz
Hege1234
#3588
üzenetére
Sorry, csak fejből írtam
map(int,...)-tel lehet még egyszerűsíteni:from datetime import timedelta
lista = ['00:10:00', '00:40:00', '01:00:00']
for elem in lista:
h, m, s = map(int, elem.split(':'))
delta = timedelta(hours=h, minutes=m, seconds=s)
print(delta.total_seconds() * 1000)[ Szerkesztve ]
JOGI NYILATKOZAT: A bejegyzéseim és hozzászólásaim a személyes véleményemet tükrözik; ezek nem tekinthetők a munkáltatóm hivatalos állásfoglalásának...
-
Hege1234
addikt
sztanozs:
igen, gondoltam mert amikor programkód tag-be teszed a script-et az mindig egyből működni szokott
ha már így belementünk ezt lehetne egyszerűsíteni?
from datetime import timedelta
import urllib.request
import re
link = 'https://nava.hu/wp-content/plugins/hms-nava/interface/classes/cacheManager.php?id=3964147&solrUrl=http%3A%2F%2F10.10.100.101%3A8983%2Fsolr%2Fnavapub%2Fselect&blogId=2&mode=titles&navaPointsUrl=%2F%2Fnava.hu%2Fnava-pontok%2F&searchPageUrl=%2F%2Fnava.hu%2Ftalalati-lista%2F&videoUrl=https%3A%2F%2Fnava.hu%2Fid%2F3964147%2F&embedUrl=https%3A%2F%2Fnava.hu%2Fembed%2F3964147'
resp = urllib.request.urlopen(link)
data = resp.read()
text = data.decode('utf-8')
urllib.request.urlretrieve(link, "info.html")
info = open("info.html", "r", encoding="utf-8").read()
time = re.findall("Időtartam:.<.span>(.*)..<.span>", info)
print(time, file=open("time.txt", "w"))
durat = open("time.txt").read()
duration = re.findall(".'(.*)'.", durat)[0].strip()
print(duration, file=open("duration.txt", "w"))
file = open("duration.txt")
line = file.readlines()
duration=line[0].strip()
h, m, s = duration.split(':')
delta = timedelta(hours=int(h), minutes=int(m), seconds=int(s))
rms = int(delta.total_seconds()*1000)
print(rms)(próbáltam BeautifulSoup-al is, de elég nagy katyvasz a html része szóval azt a részét inkább hagytam..)
mivel sehogy nem tudtam integer-be alakítani addig eljutottam, hogy megkaptam ebbe a formába
['00:27:07']de tovább már nem
ezért inkább re.sub-al leszedtem róla...
persze így is működik ahogy most van, de nagyon túlbonyolítottam sztem... -
sztanozs
veterán
válasz
Hege1234
#3592
üzenetére
Én requests modullal szedném le, és nem file-ba, hanem egyből stringbe. Melóban sajna nem tudom kipróbálni a linket ami a kódban van.
BTW a time.txt meg duration.txt honnan jön? Nem úgy tűnik, hogy azt a kód töltené le... Write módban miért olvasol belőle?
Nem egészen értem, mit csinálna a kód. Vissza is szeretnél írni bele?Milyen formában jön le a html adat, példát tudsz mutatni?
JOGI NYILATKOZAT: A bejegyzéseim és hozzászólásaim a személyes véleményemet tükrözik; ezek nem tekinthetők a munkáltatóm hivatalos állásfoglalásának...
-
-
-

JoinR
senior tag
válasz
Hege1234
#3592
üzenetére
import urllib.request
import re
from bs4 import BeautifulSoup
from datetime import timedelta
import time
link = 'https://nava.hu/wp-content/plugins/hms-nava/interface/classes/cacheManager.php?id=3964147&solrUrl=http%3A%2F%2F10.10.100.101%3A8983%2Fsolr%2Fnavapub%2Fselect&blogId=2&mode=titles&navaPointsUrl=%2F%2Fnav>
response = urllib.request.urlopen(link)
soup = BeautifulSoup(response.read(), from_encoding=response.headers.get_param('charset'), features="html.parser")
duration = soup.select_one("span[class=duration]").text
format = "Időtartam: %H:%M:%S| "
x = time.strptime(duration, format)
delta = timedelta(hours=x.tm_hour,minutes=x.tm_min,seconds=x.tm_sec).total_seconds()
delta_ms = int(delta)*1000
print(delta_ms) -
sztanozs
veterán
válasz
Hege1234
#3596
üzenetére
pedig ez feldolgozható kellene legyen beautful souppal is, kb így:
durations = [[*d.strings][1][:8]for d in soup.find_all("span", {"class": "duration"})]#3597 - strptime is elegáns...
Igazából a milisechez se kell külön modul, csak összedogatni a részeket:
for duration in durations:
format = "%H:%M:%S"
x = time.strptime(duration, format)
delta_ms = (x.tm_hour * 3600 + x.tm_min * 60 + x.tm_sec) * 1000
# vagy
h, m, s = map(int, duration.split(':'))
delta_ms = (h* 3600 + m * 60 + s) * 1000[ Szerkesztve ]
JOGI NYILATKOZAT: A bejegyzéseim és hozzászólásaim a személyes véleményemet tükrözik; ezek nem tekinthetők a munkáltatóm hivatalos állásfoglalásának...