Hirdetés
- StarCraft hírek: Készülhet egy új játék, miközben Game Pass-be tart a széria
- Unknown 9: Awakening - Amit a játékról tudni érdemes
- Jövő hónapban Xboxon is kipróbálható lesz a Fragpunk
- Újabb kedvcsinálón a The Last of Us TV sorozat második szezonja
- Újabb játékmenet videót kapott a Dragon Quest III: HD-2D Remake
-

GAMEPOD.hu
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-
#53822
 Petykemano
veterán
Simid
#53820
Petykemano
veterán
Simid
#53820
Petykemano
veterán
Mert a matissnál az azonos lapkán lévő, de másik CCX-ben található mag pont ugyanolyan késleltetéssel érhető el mint a másik lapkán található mag.
Így van:
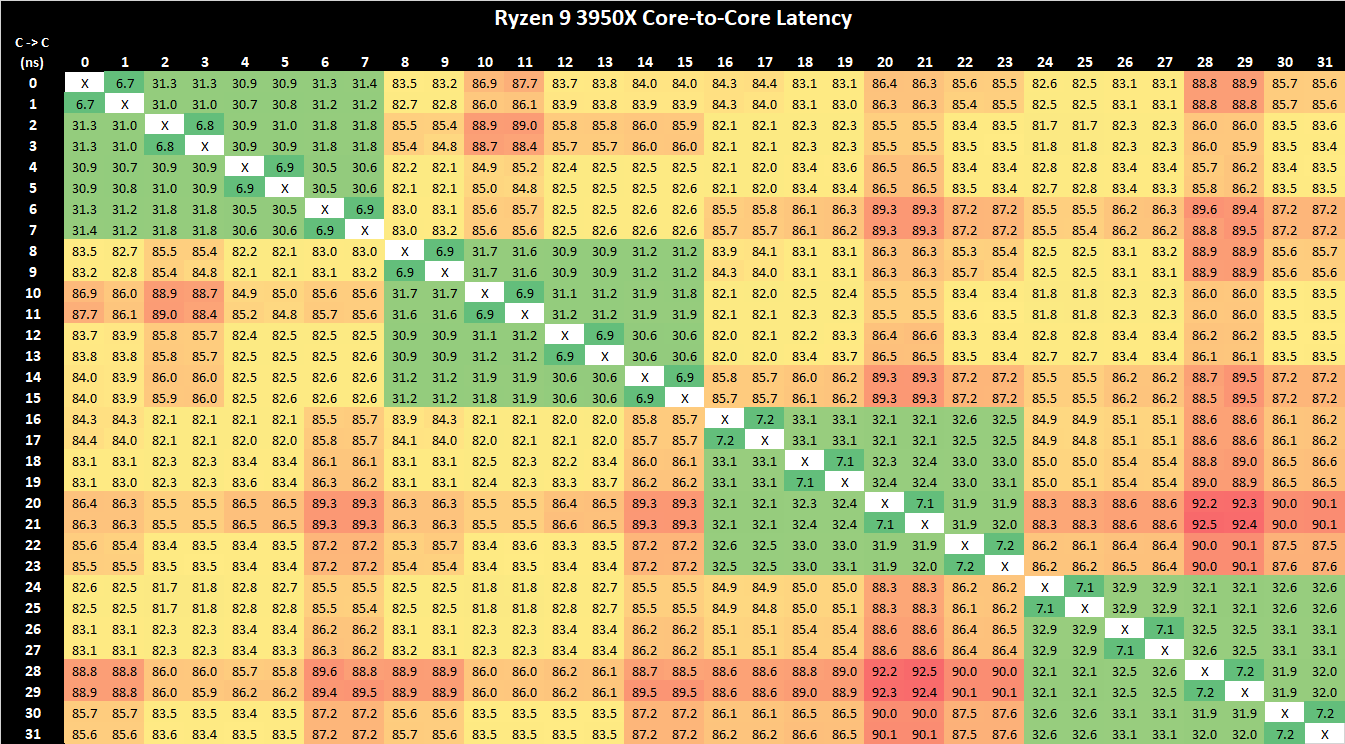
Szerintem annak az az oka, hogy valójában nincs kapcsolat a két CCX között nincs kapcsolat.
Tehát az adatforgalom vagy az IO lapján megy át, de mivel sehol nincs L4$ ezért esélyesebb, hogy a CCX-ek közötti adatcsere valójában a memórián keresztül történik.Azzal kapcsolatban nincs információm, hogy egy interposer a késleltetést csökkentené-e.
Arra vonatkozólag viszont van mérés, hogy interposeres adatkapcsolat mennyiben csökkentené a chipletek között zajló adatforgalom energiaigényét:"LIPINCON operates at 0.3V and has a bandwidth of 8Gb/s per pin and 320GB/s total bandwidth. Bandwidth density is claimed at 1.6Tb/s/mm2. It has an energy efficiency of 0.56pJ/bit. For reference, AMD’s non-interposer Infinity Fabric consumes ~2pJ/bit, while Intel has claimed as low as 0.3pJ/bit for EMIB, and 0.5pJ/bit for MDIO."
[link]Itt van egy érdekes tisztázó:
"EMIB and interposers are at the silicon level whereas Infinity Fabric is more of a protocol. Interposers are basically big (think ~800 mm2, right up to the 193i immersion stepper reticle limit) large geometry (think ~90nm node) silicon chips which are used as interconnect fabrics who communicate to their top chip(s) with small diameter microbumps. In essence, you can think of EMIB as a smaller interposer that only connects at the edges of the chips. Both use small (~50 um diameter) ubumps."
[link]
Szóval szrintem nincs kapcsolat a CCX-ek között még akkor se, ha egy lapkában vannak. Különben annak gyorsabbnak kéne lennie. Ha viszont interposerre kerülnének a lapkák (ad absurdum az IO lapka mint aktív interposerre kerülnének rá a compute chipletek), akkor az összes CCX egymásközötti kapcsolatában gyorsulásnak kéne bekövetkeznie.Találgatunk, aztán majd úgyis kiderül..



 )?
)?
Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.

- GIGABYTE RX 6600 XT 8GB GDDR6 EAGLE - 3 ventis hűtés - Eladó!
- ASRock RX 6900 XT 16GB GDDR6 Phantom Gaming OC Eladó! 175.000.-
- Hibátlan - GIGABYTE Aorus AMD Radeon RX 580 8GB GDDR5 VGA videókártya
- Pcie 5.0 ATX 3.0 12Pin - 16Pin Moduláris Tápkábelek És Adapterek 12VHPWR Egyedi Harisnya Nvidia
- BESZÁMÍTÁS! ASUS STRIX GeForce RTX 3090 24GB GDDR6X videokártya garanciával hibátlan működéssel
Állásajánlatok

Cég: Ozeki Kft
Város: Debrecen

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest