Új hozzászólás Aktív témák
-

Abu85
HÁZIGAZDA
válasz
 julius666
#21
üzenetére
julius666
#21
üzenetére
ROCm mindig lesz, hiszen a Xilinx megvásárlásakor felvázolták, hogy megszűnik a Vitis, és minden Xilinx holmi támogatása átkerül a ROCm-be.
Ez két lépcsőben megy majd végbe. Az első kör jövőre fog befutni, és a ROCm XRT interoperációval fog működni, és így lesznek elérhetők a Xilinx hardverek. A Vitis és az XRT API teljesen kukázva lesz ekkorra. A következő szint 2025, és akkor már az XRT interoperáció is eltűnik. Minden AMD gyorsító HIP C++-on keresztül lesz elérhető a ROCm futtatási környezeten keresztül.
Így fog kinézni a stack végül:
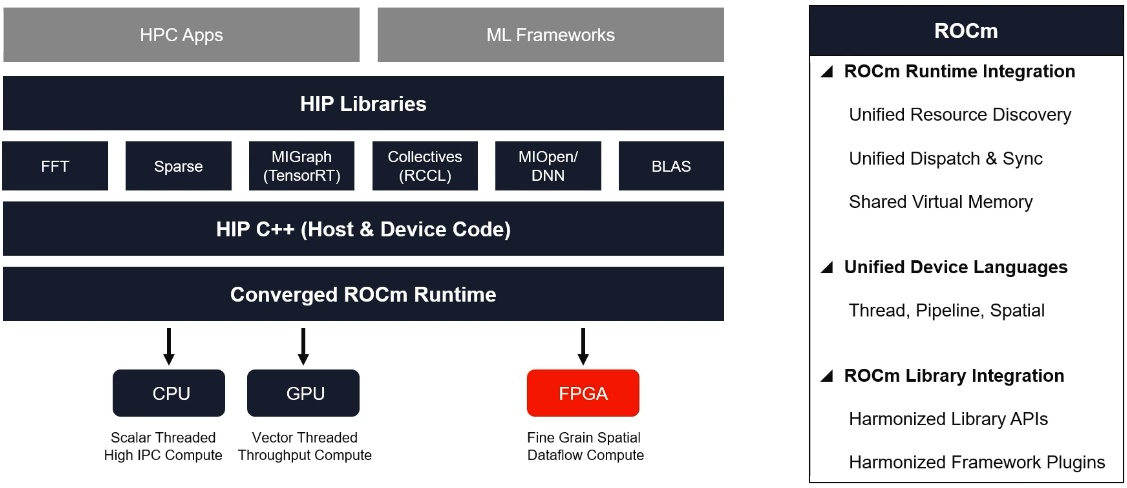
Ez azért lesz egyébként 2025-ben bevezetve, mert ekkorra lesz az AMD-nek a semi-custom üzletágán belül a custom packaging egy szolgáltatás. Onnantól kezdve xy cég odamehet az AMD-hez, és legózhat majd chipleteket a tokozásra. Nem kell külön gyorsítót venni, megveszed az egész csomagot a processzorral egy tokozáson. Az Instinct MI300 ennek az előszele, ami a CPU-t és a GPU-t rakja egy tokozásra, de később lehet majd kérni hozzá FPGA-t, ACAP-ot, az egésznek az lesz a lényege, hogy a CPU mellett ugyanarra a tokozásra rádobhass mindent, amire szükséged van megrendelőként, és ezek a hardverek ugyanazt a memóriát címezzék.
Ugyanerre megy egyébként mindenki, lásd Intel XPU projekt, csak ez sokat csúszik végül, de a koncepciója ennek ugyanaz, ami az AMD-nél a legózás. Az NV is ugyenerre megy, lásd Superchip dizájnok, csak az NV-nek nincs annyiféle hardverkonstrukciója, mint az Intelnek és az AMD-nek. Volt idő, amikor felmerült pletykaként a Lattice felvásárlása, csak annyira elhúzott mindenkitől a Xilinx ezen a piacon, hogy az NV valószínűleg nem mert belevágni, és inkább az ARM után mentek. Abból meg végül nem lett semmi.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
julius666
#25
üzenetére
A ROCm már évek óta van, és lényegében az összes ma megvásárolható Instinct gyorsító támogatja. Nyilván ez bővülni fog jövőre a Versal termékcsaláddal, amit nem véletlenül építenek be. Ezért vették meg a Xilinxet.
Heterogén érába egyelőre csak az AMD szállít valamit. Lásd MI300, aminek a mintáit elkezdték kiküldeni a megrendelőknek. Másnak nincs is meg a hasonló projektje, ami egybetokozza az eltérő hardvereket. Az Intelnek az XPU-ja majd 2026-ban jön, az NV meg az ARM felvásárlásának befuccsolásával nem gondolkodik egybetokozáson. Emiatt van az, hogy a nagy szuperszámítógépes projekteket éppen tarolja le az AMD. Lásd Frontier, El Capitan, stb. Meg ugye amiatt, hogy a CUDA már nem probléma, mert ott a Hipify, és a CUDA kódod egy nap alatt HIP C++ kód lesz. Emiatt sem erőlködnek az Exascale projekteknél az NV-vel, mert már az AMD is képes megenni a CUDA kódot egy tök egyszerű automatikus konverteren keresztül. Ezért nyeri az Intel és az AMD az Exascale projekteket, mert egyszerűen már nem szükségszerű az NV-hez ragaszkodni. Ha szükségszerű lenne, akkor a top500 dobogóján lenne NV gyorsítós gép, mint régen, de ma már nincs. Vagy a green500 top 10-ben is főleg NV gyorsítók lennének, és nem hét AMD-s gép.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
A kialakítása. A Grace és a Hopper monolitikus. Az AMD tudatosan tervezte úgy a MI300-at, hogy a chipleteket ki tudja cserélni. Később amúgy lesz ilyen dizájn is az NV-től, de a jelenlegi pletykák szerint az NV még egy darabig ezt a Superchip dizájnt fogja erőltetni. Ez az optimális az NVLinknek. Nem véletlenül csinálják így. Az AMD-nél Infinity Fabric számára más lehetőségek is vannak, mert sokkal mélyebben van integrálva, mint az NVLink az NV-nél. Nyilván utóbbit meg tudja még oldani az NV, de időbe telik.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.





Új hozzászólás Aktív témák

it Jobbak az AMD AI-chipek, mint bárki gondolta: egy AI-szoftvercég szerint már most hozzák az NVIDIA chipek teljesítményének 80 százalékát.
- LG LCD és LED TV-k
- Rengeteg áram kell az adatközpontoknak, erre válasz a geotermikus energia
- Politika
- Óra topik
- NVIDIA GeForce RTX 4060 / 4070 S/Ti/TiS (AD104/103)
- BestBuy topik
- Friss játéktrióhoz készült az új GeForce driver
- Bambu Lab X1/X1C, P1P-P1S és A1 mini tulajok
- Futás, futópályák
- Computex 2024: még két Socket AM4-es Ryzen jön
- További aktív témák...
