- Konzolokról KULTURÁLT módon
- Android játékok topikja
- Diablo IV
- Ingyenes az Epic Store-ban a Dragon Age: Inquisition – Game of the Year Edition
- Path of Exile (ARPG)
- iRacing.com - a legélethűbb -online- autós szimulátor bajnokság
- Íme az Assassin's Creed Shadows első előzetese
- PlayStation 5
- Xbox Series X|S
- EAFC 24
Új hozzászólás Aktív témák
-

ddekany
veterán
-
#13
 --Disztroj--
senior tag
--Disztroj--
senior tag
--Disztroj--
senior tag
Mindig benézem a hölgyet Falusi Mariannak


A jó bor is megárt, ha sok! Hallgasd meg Sono Matto Bozo
-

#52931072
törölt tag
Majd amikor kipukkad a lufi és elfogy az út, az éllovas ugrik elsőnek a szakadékba. Nem olyan rossz másodiknak lenni, ahol nincs harmadik futó. Az első helyezett mögött szélárnyékban vagy és az irányt is mutatja, neked csak vigyázni kell, hogy lásd merre kocog éppen.
Amikor meg majd beéri az amd, akkor majd azzal jönnek az nv hívei, hogy ott dlss42, amit bekapcsolva úgy néz ki mintha kétszer annyit számolna. .
. -

julius666
addikt
ROCm által supportált vasak terén történt már előrelépés, vagy még mindig katasztrofális? Azért a CUDA megbízhatóan megy hosszú idő óta mindenen IS, ez elég nagy fegyvertény ha valaki GPGPU/AI kapcsán beruházáson töri a fejét (akár kicsiben, akár nagyban).
AMD-nek ilyen téren eléggé tragikus a track recordja...
-
ddekany
veterán
válasz
 julius666
#15
üzenetére
julius666
#15
üzenetére
A teszt is erről szólt, hogy történt előrelépés. CUDA egyenlőre még élvezi, hogy ő volt az első, és nem volt versenytársa, de ennek a kényelmes szitunak azért valószínű, hogy hamarosan vége. A szoftveres világ nem szeretné, ha verseny nélkül szabná meg nekik az nVidia az árat. Egyértelmű a mozgolódás abba az irányba, hogy a gyakorlatban is fussanak változatos vasakon a mindenféle AI keretrendszerek.
-
julius666
addikt
Akkor nem értetted a kérdést: nem arra vonatkozott, hogy az egyes nyílt szoftver keretrendszerek mennyire támogatják a ROCm-t, hanem hogy az AMD a ROCm-el milyen saját vasait támogatja és mennyire. Mert eddig is ez volt a fő baj, a szoftveres világ szerintem nagyon szívesen ugrana az alternatívákra ha valósak lennének, nem pedig csak tervek papíron...

-
-
julius666
addikt
Az, hogy 1 vason ment valami tesztben az nem válasz a kérdésemre...
MI250 egyébként hivatalosan is supportált, nincs ebben semmi újdonság, az lenne a nagyon-nagyon szomorú (de sajnos számomra az se lenne meglepő) ha nem ment volna rajta... [link]Akkor még egyszer: CUDA megbízhatóan megy hosszú idő óta mindenen IS. Nem csak pár dedikált gyorsító kártyán. És a supporttal sincs igazán gond, megy minden patentül Win, Linux, anyámkínja alatt, míg AMD oldalon ki tudja ROCm amire most supportált meddig lesz az és a tényleges gyakorlatban mekkora szívást jelent. Ott alapvetően egy kiforratlan platformról van szó még mindig.
Jó dolog a verseny és ha van alternatíva, de a szereplők akik (mondjuk) AI trainelő/model futtató farmot akarnak építeni nem kevés pénzért azért elvárhatják, hogy ne legyen szívás support vonalon. Az AMD-nek ebbe éveken át rengeteg pénzt, effortot kellett volna beletolnia, hogy ez a sztori igazán hihető legyen. Ez látványosan elmaradt, inkább csak a félrenézés meg a bénázás meg ment, most meg hogy atombombaként szólt az AI az OpenAI-s termékek piacra kerülése után megy a kapkodás. Igény lenne rá, de szvsz kár csodára várni (sajnos).
-

consono
nagyúr
válasz
julius666
#21
üzenetére
Hát, azért ez túlzás.... Meg igazán kit érdekel az, hogy a CUDA megy e 1050-en, vagy mi a helyzet az RX580 ROCm támogatásával? A lényeg az, hogy a kurrens, támogatott nagy memóriás VGA-k ára és teljesítménye hogy áll. Ha a PyTorch támogatja a CUDA-T és a ROCm-t is, kit érdekel a múlt? Pont az LLM-nél szerintem teljesen irrelevásak a régi kártyák. Hobbira érdekes max.
"In God we trust. All others must bring data"
-
julius666
addikt
Nyilván a kutya nem akar 1050-en dolgozni AI vonalon, nem ezért írtam. Az, hogy mindenre elérhető a CUDA régóta és se runtime se support problémák nem nagyon vannak az a platform kiforrottságát és megbízhatóságát mutatja. Zöld oldalon én nem félnék attól, hogy ha kijön a következő generáció akkor elfeledkezik a gyártó a vackomról.
-

Abu85
HÁZIGAZDA
válasz
julius666
#21
üzenetére
ROCm mindig lesz, hiszen a Xilinx megvásárlásakor felvázolták, hogy megszűnik a Vitis, és minden Xilinx holmi támogatása átkerül a ROCm-be.
Ez két lépcsőben megy majd végbe. Az első kör jövőre fog befutni, és a ROCm XRT interoperációval fog működni, és így lesznek elérhetők a Xilinx hardverek. A Vitis és az XRT API teljesen kukázva lesz ekkorra. A következő szint 2025, és akkor már az XRT interoperáció is eltűnik. Minden AMD gyorsító HIP C++-on keresztül lesz elérhető a ROCm futtatási környezeten keresztül.
Így fog kinézni a stack végül:
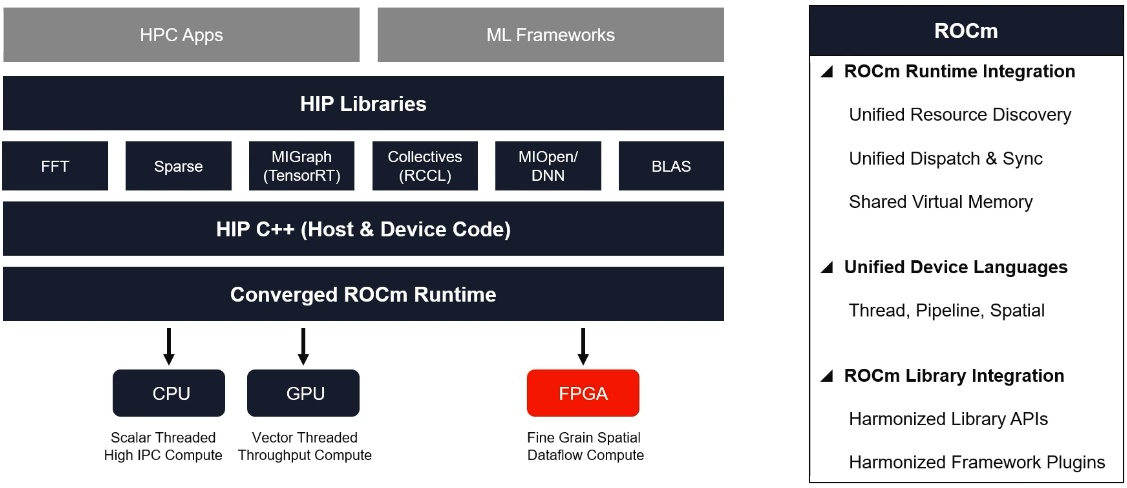
Ez azért lesz egyébként 2025-ben bevezetve, mert ekkorra lesz az AMD-nek a semi-custom üzletágán belül a custom packaging egy szolgáltatás. Onnantól kezdve xy cég odamehet az AMD-hez, és legózhat majd chipleteket a tokozásra. Nem kell külön gyorsítót venni, megveszed az egész csomagot a processzorral egy tokozáson. Az Instinct MI300 ennek az előszele, ami a CPU-t és a GPU-t rakja egy tokozásra, de később lehet majd kérni hozzá FPGA-t, ACAP-ot, az egésznek az lesz a lényege, hogy a CPU mellett ugyanarra a tokozásra rádobhass mindent, amire szükséged van megrendelőként, és ezek a hardverek ugyanazt a memóriát címezzék.
Ugyanerre megy egyébként mindenki, lásd Intel XPU projekt, csak ez sokat csúszik végül, de a koncepciója ennek ugyanaz, ami az AMD-nél a legózás. Az NV is ugyenerre megy, lásd Superchip dizájnok, csak az NV-nek nincs annyiféle hardverkonstrukciója, mint az Intelnek és az AMD-nek. Volt idő, amikor felmerült pletykaként a Lattice felvásárlása, csak annyira elhúzott mindenkitől a Xilinx ezen a piacon, hogy az NV valószínűleg nem mert belevágni, és inkább az ARM után mentek. Abból meg végül nem lett semmi.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
julius666
addikt
Nagyon szépek és jók ezek a tervek (papír mindent elbír), de ha megvalósulnak sincs semmiféle garancia arra, hogy nem úgy fog végbemenni, hogy kijön a ROCm-ből egy új főverzió (akár új néven) "na most már tényleg komolyan gondoljuk" jeligére, a régi vasakon meg hogy-hogynem már nem fog futni, vagy nem úgy, "nem megfelelő az architektúra tudása", vagy valami hasonló indokkal...
Már 2010 előtt is arról cikkeztél, hogy az AMD lesz itt a heterogén éra királya (GPGPU címszó alatt futott még akkor talán), azóta hány befuccsolt légvárat láttunk tőlük, hányan égették meg magukat akik arra számítottak, hogy be fognak jönni az ígéretek? Zöld oldalon meg azóta is tökéletesen működik a CUDA...
Én erről beszéltem feljebb. Nem lehet, hogy ez itt a probléma gyökere? Hogy nem a zöldek zsebében van az ipar, hanem egyszerűen csak senkinek nincs kedve pénzt égetni az AMD bénázásaival, szépen kivár mindenki amíg nem kezd el végre a diasorokon kívül, a valóságban is konzisztensen, generációkon átívelően stabilan szállítani az AMD?
[ Szerkesztve ]
-
Abu85
HÁZIGAZDA
válasz
julius666
#25
üzenetére
A ROCm már évek óta van, és lényegében az összes ma megvásárolható Instinct gyorsító támogatja. Nyilván ez bővülni fog jövőre a Versal termékcsaláddal, amit nem véletlenül építenek be. Ezért vették meg a Xilinxet.
Heterogén érába egyelőre csak az AMD szállít valamit. Lásd MI300, aminek a mintáit elkezdték kiküldeni a megrendelőknek. Másnak nincs is meg a hasonló projektje, ami egybetokozza az eltérő hardvereket. Az Intelnek az XPU-ja majd 2026-ban jön, az NV meg az ARM felvásárlásának befuccsolásával nem gondolkodik egybetokozáson. Emiatt van az, hogy a nagy szuperszámítógépes projekteket éppen tarolja le az AMD. Lásd Frontier, El Capitan, stb. Meg ugye amiatt, hogy a CUDA már nem probléma, mert ott a Hipify, és a CUDA kódod egy nap alatt HIP C++ kód lesz. Emiatt sem erőlködnek az Exascale projekteknél az NV-vel, mert már az AMD is képes megenni a CUDA kódot egy tök egyszerű automatikus konverteren keresztül. Ezért nyeri az Intel és az AMD az Exascale projekteket, mert egyszerűen már nem szükségszerű az NV-hez ragaszkodni. Ha szükségszerű lenne, akkor a top500 dobogóján lenne NV gyorsítós gép, mint régen, de ma már nincs. Vagy a green500 top 10-ben is főleg NV gyorsítók lennének, és nem hét AMD-s gép.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
ddekany
veterán
válasz
julius666
#25
üzenetére
Majd elválik, ez a mostani nyomulás bejön-e. A legtöbb nem jön be, de amúgy ez nem idegen más high-tech cégtől sem (pl. Intel). Most épp bíztató jelek vannak, örülsz.
![;]](//cdn.rios.hu/dl/s/v1.gif) Otthoni AI-ra meg még pár évig bizonyosan az nVidia marad a biztos megoldás. Ők kezdték (érdemben), szóval eltart egy ideig, míg sikerül a monopóliumukat, a megszokást kikezdeni, nyilván. De ez most amúgy a szerver oldali nagy-AI-modell oldalról szól. Ott elég, ha árverseny alakul ki nVidia-val, mert az akármi LLM gigamodell csoda mindkettőn értelmesen fut, ugyan abból a forráskódból, minkét esetben kifejezetten AI-ra kifejleszetett hardveren.
Otthoni AI-ra meg még pár évig bizonyosan az nVidia marad a biztos megoldás. Ők kezdték (érdemben), szóval eltart egy ideig, míg sikerül a monopóliumukat, a megszokást kikezdeni, nyilván. De ez most amúgy a szerver oldali nagy-AI-modell oldalról szól. Ott elég, ha árverseny alakul ki nVidia-val, mert az akármi LLM gigamodell csoda mindkettőn értelmesen fut, ugyan abból a forráskódból, minkét esetben kifejezetten AI-ra kifejleszetett hardveren.[ Szerkesztve ]
-
consono
nagyúr
"Otthonra" is érdekes lenne a váltás, mert egy 24 GB-s RX7900 jóval olcsóbb, mint egy 24GB-s RTX4090, de gyakorlatilag senki nem foglalkozik ezzel. Nem találtam teszteket, semmit, csak inkompatibilitási problémákat még, de ősszel elvileg jön a hivatalos támogatás: [link]. Bár ügyes emberek már most is hajtják: [link] "Under ROCm 5.6 with a batch size of 1, it can achieve 19it/s, which is comparable to most of the benchmarks for RTX 4080 and RTX 3090."
[ Szerkesztve ]
"In God we trust. All others must bring data"
-
Abu85
HÁZIGAZDA
A kialakítása. A Grace és a Hopper monolitikus. Az AMD tudatosan tervezte úgy a MI300-at, hogy a chipleteket ki tudja cserélni. Később amúgy lesz ilyen dizájn is az NV-től, de a jelenlegi pletykák szerint az NV még egy darabig ezt a Superchip dizájnt fogja erőltetni. Ez az optimális az NVLinknek. Nem véletlenül csinálják így. Az AMD-nél Infinity Fabric számára más lehetőségek is vannak, mert sokkal mélyebben van integrálva, mint az NVLink az NV-nél. Nyilván utóbbit meg tudja még oldani az NV, de időbe telik.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
























![;]](http://cdn.rios.hu/dl/s/v1.gif) Otthoni AI-ra meg még pár évig bizonyosan az nVidia marad a biztos megoldás. Ők kezdték (érdemben), szóval eltart egy ideig, míg sikerül a monopóliumukat, a megszokást kikezdeni, nyilván. De ez most amúgy a szerver oldali nagy-AI-modell oldalról szól. Ott elég, ha árverseny alakul ki nVidia-val, mert az akármi LLM gigamodell csoda mindkettőn értelmesen fut, ugyan abból a forráskódból, minkét esetben kifejezetten AI-ra kifejleszetett hardveren.
Otthoni AI-ra meg még pár évig bizonyosan az nVidia marad a biztos megoldás. Ők kezdték (érdemben), szóval eltart egy ideig, míg sikerül a monopóliumukat, a megszokást kikezdeni, nyilván. De ez most amúgy a szerver oldali nagy-AI-modell oldalról szól. Ott elég, ha árverseny alakul ki nVidia-val, mert az akármi LLM gigamodell csoda mindkettőn értelmesen fut, ugyan abból a forráskódból, minkét esetben kifejezetten AI-ra kifejleszetett hardveren.Új hozzászólás Aktív témák

it Jobbak az AMD AI-chipek, mint bárki gondolta: egy AI-szoftvercég szerint már most hozzák az NVIDIA chipek teljesítményének 80 százalékát.

Állásajánlatok

Cég: Ozeki Kft.
Város: Debrecen

Cég: Promenade Publishing House Kft.
Város: Budapest