-

GAMEPOD.hu
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-

hokuszpk
nagyúr
válasz
 Jack@l
#54172
üzenetére
Jack@l
#54172
üzenetére
ezen az alapon a cpuba se kell cache, mert az eppen futtatott jatekok egyike sem fer el benne egeszben.
kivekve a lines.exe -t az aknakeresot meg a paszianszt. szerencse, hogy ha van 10 szabad percem, akkor pont ezekkel jatszom.Első AMD-m - a 65-ös - a seregben volt...
-

Abu85
HÁZIGAZDA
válasz
Jack@l
#54325
üzenetére
Manapság nem lehet. Korábban írtam, hogy az AMD a driverét védi online hitelesítéssel. Amíg egy hardverhez nem érkezik press meghajtó, addig csak úgy lehet egy nem megjelent GPU-ra meghajtót erőszakolni, hogy ha valaki csatlakozik az AMD szerveréhez a saját azonosítójával. Ezzel teljesen meghatározható, hogy egy kiszivárgott eredmény melyik gépen ment le a világon. Ezért nincsenek manapság korai leakek az AMD-től.
A nem védett meghajtó hétfő este óta érhető el.
Van pár játék, amiben elképesztően gyors az RX 6700 XT. Az RTX 3070-nál 14-20%-kal gyorsabb. Ilyen például a Dirt 5, a WoW: Shadowslands, a Fortnite, az AC Odyssey és az AC Valhalla.
#54326 gejala : Próbáljátok ki a múlt év végi patch-csel. Jelentősen gyorsabb. Nagyjából +30%-ot rakott rá az RDNA2-re. Az Ubi visszaportolta a Valhalla leképzőjében a cache-aware módosításokat. Emiatt működik most annyira durván.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#54665
üzenetére
Miért fizetnének? Van pár sajtósa a gyártóknak. Ők küldik ki a különböző híreket. Erre van fenntartva nekünk egy külön e-mail cím. Némelyik hírt megírjuk, némelyiket pedig nem. Azért jelezni szokták, hogy mi az, ami számukra nagyon-nagyon fontos hír. Ezt sem kötelező megírni, de azért, amit ők maguknak fontosnak tartanak, az jellemzően nekünk is fontos. Általában az van, hogy ami nekik fontos arról mind írunk, és amit nem jeleznek fontosra, azok egy részéről is. Általában kisebb részéről. Amit fontosnak tartanak arra azért éri meg figyelni, mert nehéz hardverhez jutni a mai világban. Ha nem írsz róluk híreket, akkor nem nagyon küldenek hardvert, maximum akkor, ha GeForce Garage tag vagy, de az meg a függetlenség feladásával jár.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#54742
üzenetére
Az új DXR igazából csak bizonyos lépcsőket átvisz programozhatóba. Tehát a mostani hardverek jók hozzá, csak bizonyos fixfunkciós blokkok nem fognak működni többet. A következő lépés inkább szoftveres szinten lesz lényeges. A hardverek megfelelnek elég sokáig visszamenőleg.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#54751
 Alogonomus
őstag
Jack@l
#54749
Alogonomus
őstag
Jack@l
#54749
Alogonomus
őstag
válasz
Jack@l
#54749
üzenetére
Nincs olyan, hogy "raytracinget", az nem egyetlen művelet. Az Nvidia RT magjai a DXR API rengeteg lehetséges funkciójából egy bizonyos halmaz használatához kimondottan hatékonyak. A maradék funkciókat pedig csak közepes, vagy rossz hatékonysággal tudják kezelni.
Az Nvidia készített egy versenyautót, ami versenypályára nagyon jó, terepre nem annyira. Az AMD készített egy városi autót, ami versenypályára nem ideális, de cserébe terepen is tűrhetően elboldogul. -
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#54900
üzenetére
Elég sokat. Ugye maga a PCI Express áll a vezérlőből, illetve az I/O kivezetésből. Utóbbival van a gond, mert az nem skálázható. Ez azt jelenti, hogy 28 nm-en is kb. ugyanakkora részt vesz el a lapkából, mint 7 nm-en, vagy modernebb node-on. Mivel a többi részegység skálázható, így jelen pillanatban ott tart a helyzet, hogy egy RDNA2 WGP annyi helyet igényel a lapkán, amennyit egy x4-es PHY tömb. Tehát ha 16 sáv helyett nyolcat használnak, akkor arra a helyre befér két WGP, vagyis 256 darab ALU részelem. És ha ezt tényleg az RDNA2-re számolod, aminél ugye a kisebb verziók 3 GHz környéki működésre vannak tervezve, akkor ennyi ALU lényegében +1,5 TFLOPS-ot jelent. Utóbbi sokkal többet ér, mint nyolc PCI Express sáv. Egyszerűen így gyorsabb lesz a hardver.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#54939
üzenetére
Nyilván okkal törődünk egyre többet a konzollal a hírekben és a cikkekben is.

Az oldal felől ez egyszerű tényező. Ha más érdekli az olvasókat, akkor máshoz igazodunk. Egyelőre egyébként nem látom, hogy hatalmas para lenne itt, mert hiába drágák a hardverek, sokan megveszik, és van olvasó bőven.

[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-

Yutani
nagyúr
válasz
Jack@l
#55184
üzenetére
Ha már a 3060 is CPU limites, akkor fordulhat elő, hogy a 3080 is az lesz, és adott (alacsony) felbontáson nem fog sokkal magasabb FPS-eket produkálni a kisebb kártyától (viszont ebben a pillanatban nem tudnék rá példát mondani, de biztos van). A mester szerint a felskálázás esetében ugyanez fog jelentkezni. Már ha 1080p-ről vagy alacsonyabbról skálázunk fel 1440p-re vagy 4k-ra. Csak éppen alacsony felbontásról inkább gyengébb kártyákkal fogunk felskálázni, ahol még mindig inkább GPU limit van, mint CPU, szóval...
[ Szerkesztve ]
#tarcsad
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#55369
üzenetére
Az alacsony felbontású számítás miatt alakul ki a CPU-limit. Van egy ismert problémája az NVIDIA kártyáinak, amik miatt a DirectX 12-es játékok gyengébb processzorokkal egyszerűen nem skálázódnak jól. Ez leginkább 1080p-ben és alatta keletkezik. Erről csináltak is teszteket. [link] és [link]
A jelenség megszűnik 1440p-ben és fölötte, de az FSR-rel a számolt felbontás alacsonyabb lesz a beállítottnál, pont úgy, ahogy a DLSS esetében, tehát a CPU-limit ugyanúgy érződni fog a DirectX 12-es játékokban a GeForce-okon, nagyjából úgy, mintha valóban 1080p alatti minőséget számolnál natívan.Ha valaki GeForce-szal játszik, érdemes Zen 3-ra lépnie, lehetőség szerint négynél több maggal, de az optimális a nyolcnál több. A Radeonok DirectX 12-ben sokkal jobban kezelik ezt a problémát, így azok nem skálázódnak annyira rosszul gyengébb CPU-kkal, mint a GeForce-ok. Ez is benne lehet egyébként abban, hogy az AMD miért mér jelentős gyorsulásokat RDNA 2-re az FSR-rel, miközben ezt meg sem közelítik a GeForce-os eredmények. Egyszerűen nem használtak a leggyorsabb Ryzent, hogy a GeForce-okat belefuttassák a CPU-limitbe. Ezt majd külön érdemes megnézni a tesztelőknek, így ajánlott Ryzen 9 5950X-szel dolgozniuk, hogy a GeForce-ok sebessége biztosan skálázódjon, ne a proci fogja vissza őket, amikor 1080p alatti felbontáson számolnak az aktivált FSR-rel. Minimum nyolcmagos Zen 3 kell egyébként, hogy a skálázódás elfogadható legyen, hatmagossal már érezhető, hogy a GeForce-ok olyan limitekbe fut 1080p-ben is, amelyeket a Radeonok meg sem éreznek, ezek nem nagyok, de egyértelműek kimérhetők. Biztosra 16-magos Ryzennel lehet menni. Főleg úgy, hogy FSR-rel simán 1080p alatt is számoltathatsz.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#55371
üzenetére
Attól, hogy nem fogadsz el egy tényszerűen kimért problémát a GeForce-okon, még létezni fog, és nyilván amíg ez kezelhető annyival, hogy 1440p-re rakod a számolt felbontást, hogy GPU-limitbe kerül, addig ez nem akkora para. De ez a gond a felskálázási technikákkal érződni fog, mert azok bizony nem fognak ilyen magas felbontásban számolni, tehát a valóban számolt felbontáshoz közeli limitek fognak élni. Lásd a fentebb linkelt két tesztet. Erre figyelni kell majd a tesztelésnél, mert ha nem raksz elég erős procit a rendszer alá, akkor könnyen lehet, hogy a Radeonok bőven GPU-limitben lesznek akkor, amikor a GeForce-okat még a gyenge proci akadályozza a skálázódásban.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#55373
üzenetére
Nem is arról van szó, hogy mit látsz, hanem arról, hogy milyen limitekbe ütközik a rendszer alacsonyabb felbontáson számolt képkockákkal. Erről linkeltem két tesztet fentebb, ahol sok procival és sok VGA-val nézték a problémát. És továbbra is hangsúlyozom, hogy attól ez a jelenség nem szűnik meg, hogy félsz rákattintani a linkekre, mert nem kompatibilisek az adatok azzal a világgal, amit felépítettél magadnak.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#55376
üzenetére
Sokkal reálisabb körülmények között bekövetkezik a GeForce-okon a DirectX 12-es alkalmazásokban a procilimit. Lásd linkek.

#55375 paprobert : Persze. A felskálázással hiába lesz 4K a kirakott a felbontás a számolt ennél sokkal kisebb, és arra már erősen érződhet egy procilimit. Ez egy ilyen móka. De nagyrészt ez elkerülhető az erős Ryzenekkel. Mi alapvetően azért mérünk a tesztgépben nyolcmagos Zen 3-mal, mert a hatmagossal már érezhetően büntit kapnak a GeForce-ok 1080p-ben, annak ellenére is, hogy a Radeonok tökre elvannak hatmagossal. Úgy gondolom, hogy 12-magos lenne az optimális, de egyelőre örülünk, hogy van nyolcmagos.

[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#55384
üzenetére
Ha megnézted volna azt a két linket, amit adtam, akkor tudnád, hogy ez igazából csak a DirectX 12-es játékokban jelentkezik. DirectX 11-ben és Vulkan API-val nem, ott valamiért nincs olyan gondja az NV-nek, hogy hamarabb fut CPU-limitbe.
#55385 Petykemano : Van. Két képet össze lehet hasonlítani pixelenként, és az eltérés erősen objektív adat. De a felskálázis eljárások eleve olyanok, hogy a hiányzó részleteket neuronháló(k) segítségével pótolják. Tehát pixelről-pixelre vizsgálva mindenképpen jelentős eltérés lesz a natív és a felskálázott kép között, mert se a DLSS, se az FSR neuronhálója nem alkalmas arra, hogy hajszálpontosan ugyanazt az eredményt adja, mint a natív felbontás.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Yutani
nagyúr
válasz
Jack@l
#55392
üzenetére
Erősebb kártyáknál jön ki a limit alacsony felbontáson, ha nincs alatta elég erős proci. Ez a limit úgy értendő, hogy ugyanazzal a gyenge processzorral az AMD kártyák több FPS-t adnak, mint az erősebb NV kártyák. Példa:

De annak ellenére, hogy kimérhető dolog, eléggé valószínűtlen, hogy előfordul ez a felállás. Ki raknak 3090 alá 1600X-et?

#tarcsad
-

sutyi^
senior tag
válasz
Jack@l
#55422
üzenetére
Az azért "probléma" mert ha benyomod a DLSS-t vagy esetleg majd az XFR-t, akkor megkapod az alacsonyabb felbontással járó overhead limitet is (ha nem lesz orvosolva).
-Pedig nem is én utállak téged, te utálod saját magad! - ...és mégis egész nap együtt kell lennem saját magammal.
-
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#55589
üzenetére
[link] - itt a teljes előadás, a Microsoft DXDevDay rendezvényéről, ahova készült ez a demó.
#55590 morgyi : Ez ugyanaz, ami a DXDevDay-re készült.
Az AMD saját demója a Hangar 21.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#55709
üzenetére
Nincs 4K-s adatsorom róla. Igazából AMD-s sincs. OEM van, és abban csak 1080p-s mérések vannak négy DX12-es játékkal: Dirt 5, WoW: Shadowlands, Hitman 3, Assassin's Creed Valhalla
Viszont a proci egy Ryzen 9 3900, ami 65 wattos, és az NVIDIA DX12 drivere sokkal lassabb ilyen körülmények között. Viszont a 6600 XT úgy ~25%-kal gyorsabb, mint a 3060 Ti. WoW: Shadowlands-ben 40%-kal, de itt be van kapcsolva a sugárkövetés, ami ebben a játékban szintén nem kedvez az NV-nek, azt kikapcsolva már közelebb lennének. Egyelőre ennyi van.
4K-ban szerintem gyorsabb lenne a 3060 Ti, mert saját mérésekből kiindulva erősen látszik, hogy az NV még 1440p-ben is procilimites egy Ryzen 7 3700-zal, ami nem sokkal lassabb, mint a 3900. Az AMD már sokkal gyengébb procin sem limites 1080p-ben sem.
#55710 Raymond : Mint írtam, ár még nincs.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#55728
üzenetére
A 6600 XT 128 bites GPU-val dolgozik.
Nem életszerű, de az NV limitbe fut, ha nem high-end procit raksz alá. Ezzel nem tudunk mit kezdeni, mi is kicseréltük a tesztgépben a korábbi procit, és látványos a gyorsulás, még középkategóriás GeForce-on is.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
válasz
Jack@l
#55728
üzenetére
Nvidia megint gondban van Amd megint jó mert 128 bites kártyát adnak 399 dollárért de 1080TI!!!! saját játékokban, FHD ban CPU limites környezetben. és nem jó az nvidiára abban az 5 játékban az árnyékokra szabott láthatatlan Rt effekt . szóval jó az!...
Amúgy ez megint ilyen megvezetés árpletyka szerintem. Olcsóbb lesz majd a debüt napon mert az összes külföldi fórum fortyog., redditen még az ős / elvakult AMD fanok is morognak.[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
Abu85
HÁZIGAZDA
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#55832
üzenetére
Mert jóval több is. A Lanczos évtizedek óta a legjobb megoldás skálázásra, nem véletlen, hogy a MadVR is arra épít, de rengeteg olyan operációt alkalmaz, amelyben a GPU-k veszettül lassúak. Az AMD implementációja pont ezen módosít jelentősen, illetve az egész algoritmus problémáit kicseréli olyan eljárásokra, amelyek nem okoznak képi hibákat.
És figyeld meg, hogy mennyien be fogják építeni. Pont az a lényege, hogy semmiféle overengineering nincs benne. Egyszerű megoldás egy egyszerű problémára, ami akármilyen futószalagon belül működik, ráadásul 14 évre visszamenőleg fut a hardvereken.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#55834
üzenetére
A probléma az eredeti algoritmussal az volt, hogy nem mindig végez elég jó munkát, illetve nem is gyors.
A "nem is gyorsra" az volt a válasz, hogy megkeresték azokat a részeit az számításoknak, amelyek marhára lassan futnának egy GPU-n. Ilyenek a különböző szögfüggvénye, a négyzetgyök, stb. Ezek azért futnak lassan, mert a fő ALU-kban, nincs rá utasítás egyik GPU-ban sem. Helyettük a multiprocesszorok tartalmaznak pár SFU-t, amelyek el tudják végezni a feladatokat, de úgy 32-, 256- rosszabb esetben 512-szer lassabban. Ez ugye elég nagy szopás ahhoz, hogy valós időben az alapalgoritmus ne legyen alkalmazható. Egyrészt az SFU-k száma nem sok egy teljes GPU-n belül, másrészt az egyes speciális operációk is 8-16 órajel alatt valósulnak meg.
Ezt a problémát kezeli a kódban egy 0x5F3759DF WTF-szerű ötlet, amely a lassan futó operációkat kicseréli alapműveletekre, amelyek több nagyságrenddel gyorsabban futnak, és ezért csak kevés pontosságot áldozol. Emiatt az alapalgoritmus teljesítménye az egyes GPU-kon akár a százezerszeresére is tud nőni, vagyis eljutottál ahhoz a tartományhoz, hogy valós időben alkalmazható legyen.A másik probléma a "nem elég jó munka". Ehhez az alapalgoritmusnak külön kezelték a képi hibákat adó részeit. Ezeket kompletten átírták, illetve a képi hibák lehetőségét mellőzni lehessen. Ugye ennek is az volt a kulcsa, hogy az alapalgoritmust átlagosan a sok tízezerszeresére gyorsították egy GPU-n, tehát most már van miből költeni a jobb minőségre. Ebből jön az élek rekonstrukciója, ami az eljárás alapja.
A további modulnak számító RCAS már csak egy adalék, ami extra helyreállítási munkát végez.
#55835 Petykemano : A Xilinxet nem ezért veszi meg az AMD.
A FidelityFX Super Resolution eleve egy rohadt gyors eljárás. Amellett, hogy ez adja az ismert eljárások közül a legjobb rekonstrukciós minőséget, még ez is fut a leggyorsabban a GPU-kon. Tehető ennél gyorsabbá is, de egy középkategóriás VGA-n sem számol 1 ms-nél tovább, ha azt leviszed 0,9-re, ami egyébként még talán realitás is, akkor sem nyersz vele sok sebességet, mert a képszámítási teljes idejének a töredékrészén optimalizáltál 10%-ot, vagyis a teljes képszámítás időigényén ez jó ha 1%-ot dob.
Jobb minőség sem várható, mert eleve képes arra az algoritmus, hogy a natívval nagyon megegyező minőséget csináljon. Elméletben a natív minőség a referencia. Papíron ennél jobbat nem lehet csinálni. Az más kérdés, hogy a FidelityFX Super Resolution esetében is van olyan, hogy az UQ beállítás szebbnek tűnik, de ugye papíron ez nem lehet szebb, csak szubjektív benyomás szintjén.
Az alacsonyabb felbontásról való rekonstrukción lehet javítani. De ez egy balansz kérdés. Minél alacsonyabb felbontásról skálázol fel valamit, annál nagyobb számítási teljesítmény kell magához a skálázáshoz, hogy jó eredményt érj el. Az AMD nem véletlenül ajánl előre skálázási paramétereket. Azok ugyanis a sweet spotok.
A másik dolog, hogy az AMD régóta tart FidelityFX-es preziket, és sokszor elmondták már, hogy az elmúlt évtizedben arra jöttek rá, hogy sokszor a legegyszerűbb megoldások a legjobb válaszok egy problémára. Semmiféle overengineeringet nem szabad felvállalni. A FidelityFX fejlesztése úgy működik, hogy feltárnak egy problémát, arra átbeszélnek pár megoldást, és abból mindig a legegyszerűbbet választják, mert az esetek 99,99%-ában az a legcélszerűbb. Amikor egy algoritmust bonyolítasz, akkor előjönnek vele a problémák, nehezebben kezelhető lesz, több limitációt kell figyelembe venni, arra nem is biztos, hogy mindegyik fejlesztő hajlandó. Magát a FidelityFX CAS-t is az egyszerűsége adta el. Ugyanezt az elvet követi az FSR is.
#55836 FLATRONW : Mire gondolsz NGU alatt? Hirtelen nem tudom dekódolni.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#55857
Alogonomus
őstag
Jack@l
#55856
Alogonomus
őstag
válasz
Jack@l
#55856
üzenetére
A tensor magok használata nélkül is magas már az Ampere kártyák fogyasztása. Munkára fogott tensor magokkal vagy még vadabb fogyasztási értékek jelentkeznének, ami 2,5 kilós 4 slotos kártyákat eredményezne, vagy a tensor magok "felzabálnák" a fogyasztási keretet a hatékonyabb feldolgozók elől, ami meg simán teljesítményveszteséget okozna csak.
-
#55983
 Petykemano
veterán
Jack@l
#55982
Petykemano
veterán
Jack@l
#55982
Petykemano
veterán
válasz
Jack@l
#55982
üzenetére
Hát...
Szerintem két-három dolog áll a háttérben.Egyrészt a GDDR6 árak. Lehet, hogy az AMD úgy gondolja, hogy nagyobb hatással tud lenni az infinity cache megoldásán keresztül egy termék árazására, mintha a GDDR6 lapkák dráguló árazására hagyatkozna.
Az infinity cache meg amúgy is lehet, hogy ilyen musthave ahhoz, hogy két különálló lapkát egyben lásson a rendszer.
64bit GDDR6 vezérlő helyén monolitikus 7nm-en nagyjából 16MB oo$ fér el.
De ugye tudjuk, hogy a memóriavezérlő rosszul skálázódik, külön gyártva ugyanannyi lapkaméreten elfér 32MB is.Valójában ha a navi21 vonatkozásában akarnánk értelmezni, akkor a kérdés úgy szólna, hogy vajon további 128bit GDDR6-ot tudna-e helyettesíteni további 128MB oo$?
A másik fontos tényező az oo$ vs GDDR6 tekintetében az lehet, hogy az AMD eléggé elkezdte az architektúráit késleltetésre kihegyezni.
[link]
jó, ez nyilván nem most kezdődött, de olyan mintha most már kifejezetten cél lenne. Ami valahol logikus is, hiszen a magas fps-hez (alacsony frametime-hoz) nem csak magas frekvencia kell(het), hanem az is, hogy minél kisebb legyen a várakozási idő, az üresjárat.
Abu meg mintha azt is mondta volna, hogy ez a RayTracingnek is hasznos.További szempont lehet még az, hogy itt az FSR. Ennek a lényege, hogy alacsonyabb felbontáson számolódik a képkocka. Kisebb felbontáshoz nem kell olyan nagy sávszélesség, de az alacsonyabb frametime miatt fontosabb a jó késleltetés.
Számomra az egyetlen kérdés az kapacitás.
Tehát ha ugyanannyi GDDR6 lapkát kell feltenni, akkor nem sok költséget nyertél.Felmerül a kérdés, vajon a VRAM kapacitást nem spórolják-e ki majd az akkor már rendelkezésre álló 16xPCIe5 terhére?
Találgatunk, aztán majd úgyis kiderül..
-

GeryFlash
veterán
válasz
Jack@l
#56092
üzenetére
Fuggetlenul hogy ez a 6600XT egy okadek szar, 4GB-os kartyat az Nvidinal kell keresni, a Full HD belepo szintu gamer laptopokba gyartanak most 3050TI-t

Hi, i'm new to APHEX TWIN, so i was wondering how much the IQ requirements was to enjoy his stuff. and understand all the underlying themes, because its really complex stuff. I have IQ of 119 but i heard that you need atleast 120 is it true?
-
#56094
Petykemano
veterán
Jack@l
#56092
Petykemano
veterán
válasz
Jack@l
#56092
üzenetére
> Legközelebbb 64 bites 4 gigásat adunk százezeré...
Egy látnok lehetsz
Az év végén megjelenő navi 24 szerintem pont ilyen lesz.
(De lehet, hogy már a 6600-ból is lesz 4GB-os.)> Már procinál is feltűnt, de átvették most a vga-khoz is,
> hogy az also kategóriában sokkal rosszabb a prf/dollar arány, mint a csúcskategóriában.
> Elég "érdekes" marketing stratégia.
Ez a "bármit és mindent is eladunk, ezért inkább azt vedd meg, amit drágábban adunk" stratégia.Találgatunk, aztán majd úgyis kiderül..
-

.Ishi.
aktív tag
válasz
Jack@l
#56115
üzenetére
Z1ON fentebb linkelte:
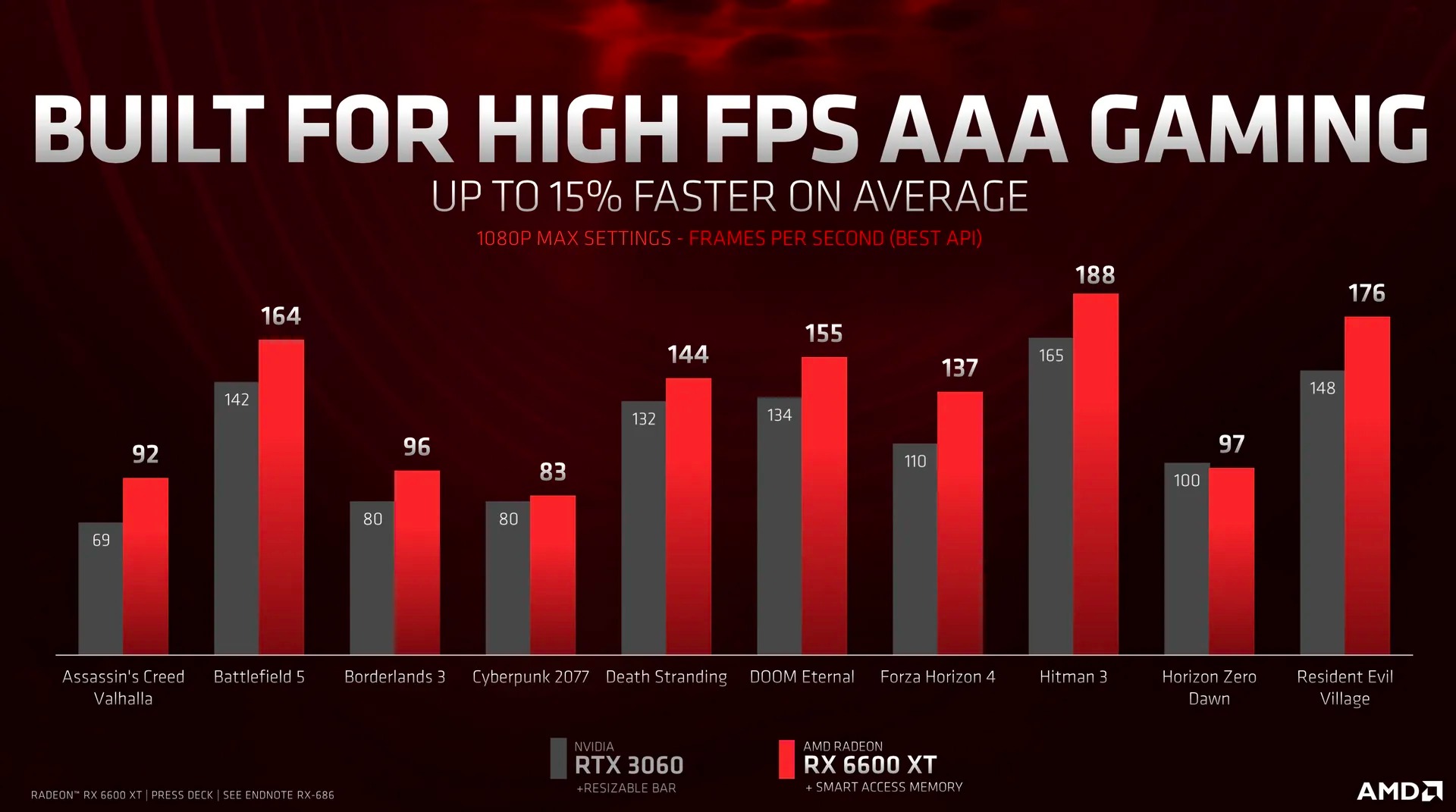
Itt vannak tipikusan AMD-s címek is, de szerintem meglesz az RTX 3060 + 10%. Ha pusztán az MSRP-ket nézzük (legalábbis viszonyítási alapul), akkor szerintem így fog alakulni:
RTX 3060 - $330 - RTX 2070 szint
RX 6600XT - $379 - RTX 2070 Super szint
RTX 3060 - $399 - RTX 2080 Super szint
Így sem tűnik sajna olyan vonzónak ez a kártya.
#56116 Petykemano: Bár nem ismerem a kínai netkávézók sajátosságait, de ha van egy rahedli 1060-asuk, amit le akarnak váltani, akkor nem hiszem (csak és kizárólag az MSRP alapján), hogy 50 dolcsival többet kifizetnek +10% teljesítményért. Szerintem morgyi tapintott rá a lényegre: az RX 6600XT-t az AMD egyszerűen nem akarta beállítani egy nagyon vonzó opciónak. -
#56280
Petykemano
veterán
Jack@l
#56279
Petykemano
veterán
válasz
Jack@l
#56279
üzenetére
Nem érted, vagy nem akarod érteni.
Vagy én nem értem, hogy Te mit akartál mondani.A pcix4-8x = pcix3-16x összefüggés csak elméletben igaz.
A kártya 8x PCIe4 sávval van szerelve. Ez elméletben ugyanakkora sávszélesség, mint a 16x PCIe3. De ha berakod egy olyan alaplapba, ami csak PCIe3-at tud, akkor a kártya csak 8x PCIe3 sávszélességgel tud kommunikálni.
Tehát de:
A jelek szerint aki Doom Eternal-t szeret játszani és ragaszkodik a 6600XT-hez, az jobban teszi, ha PCIe4-es alaplappal rendelkezik.hozzáteszem újra:
Jelenleg ez nem tűnik dealbreakernek. Csak a kártya ebből a szempontból nagyon pengeélen táncol, nincs benne tartalék, nincs benne "Fine Wine". Ha neadjisten 1-2 év múlva már kevés lesz a 8GB (ahogy ma kevés a 4GB) akkor az akinek még mindig csak PCIe3-es lapja van, az csúnya belassulást fog tapasztalni. (Ezt abból láthatjuk majd esetleg, hogy egyre több játékban lesz erősebb az 5700XT, mint a 6600XT. DE reméljük persze, hogy nem így lesz.)Találgatunk, aztán majd úgyis kiderül..
-
#56282
Petykemano
veterán
Jack@l
#56281
Petykemano
veterán
válasz
Jack@l
#56281
üzenetére
De egyrészt a Rocket Lake már tudja a PCIe4-et.
Másrészt a most útnak indult igen népszerű(nek ígérkező) 5x00G (Cezanne) processzorok meg nem. (Nem tudom persze, hogy akad-e 6600XT vásárló, aki 5600G-t vesz 5600X helyett)Én a "maga felé hajlik a keze" típusú szándékosság helyett azt látom, hogy ez PR fogás.
Tehát a tesztek nagy része úgyis PCIe4 rendszerben fog történni. És még ha ki is térnek ennek a hiányosságnak a felderítésére, az csupán 1 slide a 30-ból.
Tehát él Abu érvelése: jobban megéri ugyanarra a helyre 1WGP-t tenni, mint 8x PCIe csatolót. Legalábbis ma így van.
ha úgy alakul, hogy nőne a játékok memóriaigénye, akkor persze már hasznosabb lenne megcserélni. De addigra majd jönnek új kártyák.[ Szerkesztve ]
Találgatunk, aztán majd úgyis kiderül..
-
Yutani
nagyúr
válasz
Jack@l
#56467
üzenetére
Ez alapján vihar volt a biliben a sok sírás-rívás, hogy a kártya meghal 8xPCIe 3.0-án:

Nem láttam a tesztben olyan játékot, ahol kritikus lett volna a visszaesés. Sőt, ha valaki fHD@60Hz-en van (mint én), semmit nem vesz észre. Tehát ha lenne normális áron ilyen kártya, meg merném venni.
#tarcsad





 Így van.
Így van.












![;]](http://cdn.rios.hu/dl/s/v1.gif)








Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.
- Autós topik
- MW2 - MW3 játékosok baráti köre
- Intel Core i3 / i5 / i7 / i9 10xxx "Comet Lake" és i3 / i5 / i7 / i9 11xxx "Rocket Lake" (LGA1200)
- Fortnite - Battle Royale & Save the World (PC, XO, PS4, Switch, Mobil)
- Szimpatikusnak tűnik a T Phone új generációja
- Autós topik látogatók beszélgetős, offolós topikja
- Ford topik
- Politika
- Honor 200 Pro - mobilportré
- ZEN.com
- További aktív témák...
